
MoshiVis:让语音模型“看懂”图像,开启视觉对话新时代。亮点:
-
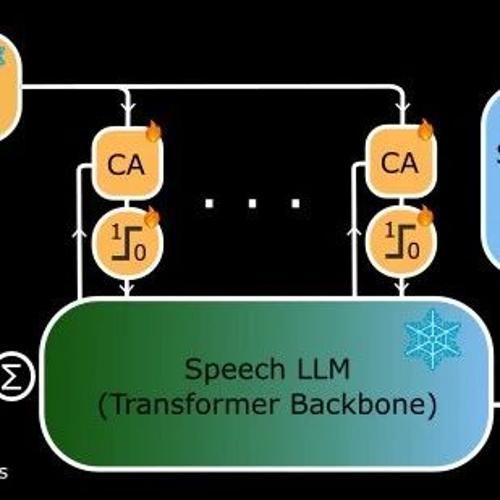
基于7B参数的Moshi模型,新增约206M适配器参数,轻松讨论图像;
-
支持PyTorch、Rust、MLX三种后端,灵活部署;
-
提供实时视觉对话能力,低延迟高效率。


参考文献:
[1] http://github.com/kyutai-labs/moshivis
(文:NLP工程化)
MoshiVis:让语音模型“看懂”图像,开启视觉对话新时代。亮点:
基于7B参数的Moshi模型,新增约206M适配器参数,轻松讨论图像;
支持PyTorch、Rust、MLX三种后端,灵活部署;
提供实时视觉对话能力,低延迟高效率。
参考文献:
[1] http://github.com/kyutai-labs/moshivis
(文:NLP工程化)