
Understand-R1-Zero:深入剖析R1-Zero类训练方法,揭示其背后的原理与优化策略。亮点:
-
深入分析基础模型,发现DeepSeek-V3-Base已展现“灵光一现”现象;
-
提出Dr. GRPO算法,优化强化学习过程,提升token效率;
-
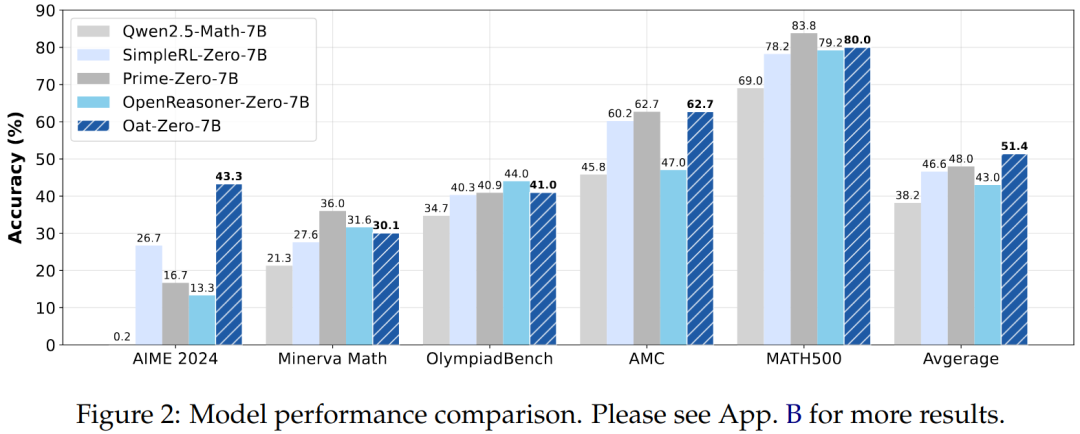
仅用27小时计算资源,在8×A100 GPU上实现SOTA性能。
参考文献:
[1] http://github.com/sail-sg/understand-r1-zero
(文:NLP工程化)
Understand-R1-Zero:深入剖析R1-Zero类训练方法,揭示其背后的原理与优化策略。亮点:
深入分析基础模型,发现DeepSeek-V3-Base已展现“灵光一现”现象;
提出Dr. GRPO算法,优化强化学习过程,提升token效率;
仅用27小时计算资源,在8×A100 GPU上实现SOTA性能。
参考文献:
[1] http://github.com/sail-sg/understand-r1-zero
(文:NLP工程化)