
从这一篇文章开始,我们将正式开启 RAG101 系列教程。
先解释一下为什么叫 RAG101?
在美国大学中,课程编号通常采用三位数体系,其中第一位数字表示课程的级别或学年,后两位是该课程在该级别中的编号。例如,编号以“100”开头的课程通常为初级课程,适合大一新生选修。其中,“101”通常表示某学科的入门课程,无需先修课程即可注册。
因此,“XX101”被广泛用于表示某个领域的基础或入门知识。例如,“数学101”表示数学的基础课程,“编程101”表示编程的入门课程。这种用法已超越教育领域,成为描述任何主题基础知识的通用表达。
在我们这个系列的教程中我们将采用 Qwen 系列的模型进行代码演示,并且通过 OpenAI API 兼容的方式调用 Qwen 系列的模型。
https://help.aliyun.com/zh/model-studio/developer-reference/use-qwen-by-calling-api
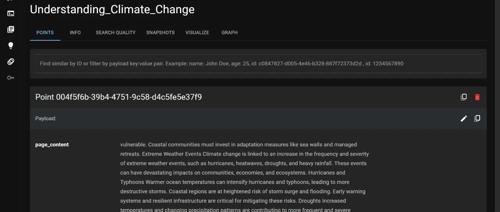
首先加载文档
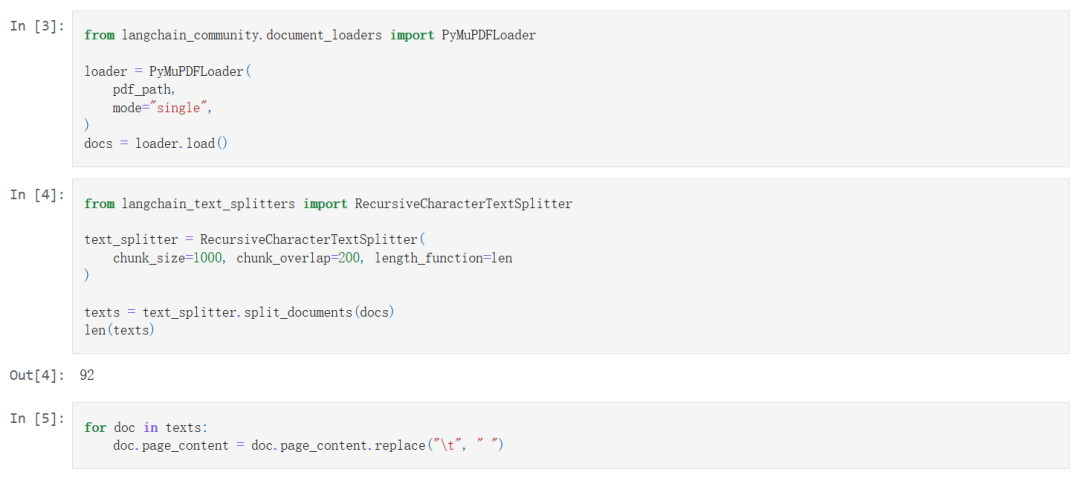
在上述代码中:
-
我使用了 PyMuPDFLoader 来加载 PDF 文档。得到了一个 Document 对象,如果我们不指定 mode=”single” 那么就会得到一个 Document 对象列表,每页 PDF 一个 Document 对象。
-
文本拆分,将整个文档拆分成一个个小的文本块,最终我们得到了 92 个小文本块,这也是 Document 对象。
-
我们对原始文本进行了简单的处理:去除了制表符。
在 RAG 系统中,文本拆分(Text Split) 是一个至关重要的步骤,主要有以下几个原因:
1. 降低向量维度,提高检索效率
-
直接对整个文档进行向量化会导致非常高的维度,使得计算资源消耗巨大,并影响检索效率。 -
通过拆分文本成较小的块(chunks),每个块可以独立编码为向量,使得向量存储和检索更加高效。
2. 提高检索相关性
-
如果文档过大,整个文档被编码成一个向量,查询时可能无法精准匹配到细粒度的信息。 -
通过拆分成多个较小的文本块,每个块都可以单独进行语义搜索,从而提高召回的准确性,确保检索到的内容与查询更相关。
3. 适配嵌入模型的长度限制
-
OpenAI 的 text-embedding-ada-002等嵌入模型对输入文本长度有限制(例如 8192 tokens)。 -
如果文本过长,直接传入会导致截断或错误,因此需要拆分成小块,以确保每个块都能被完整编码。
4. 处理大规模文档
-
RAG 适用于长文档检索,如果不拆分,单个向量存储会变得庞大且不易管理。 -
拆分后,每个小块独立存储,可以更好地进行增量更新、删除或动态调整。
5. 解决语义漂移问题
-
文档中不同部分的语义可能相差较大,比如某段是定义,某段是实验结果,如果不拆分,整个文档的向量可能会导致语义混杂,影响检索效果。 -
通过拆分,确保每个块内的内容具有较高的语义一致性,提高检索的精确度。
6. 便于 RAG 生成更精准的答案
-
RAG 的核心是 “检索 + 生成”,如果检索返回的信息过于冗长或不精确,生成模型的回答也会受影响。 -
通过拆分文本,检索阶段可以返回更小、更精准的上下文,提升最终生成答案的质量。
拆分策略
常见的文本拆分策略包括:
-
固定长度拆分(Fixed-length Chunking):按照固定的字符数或 token 数拆分,如 512 字符或 256 tokens。
-
递归字符拆分(RecursiveCharacterTextSplitter):基于句子、段落等自然边界进行拆分,避免割裂句子。
-
语义感知拆分(Semantic-aware Splitting):使用 NLP 方法按语义边界拆分,使得每个块保持语义完整性。
文本拆分是 RAG 系统优化检索和生成效果的关键步骤,它能够降低计算成本、提高检索相关性、适配嵌入模型、增强生成质量,从而使整个 RAG 系统更加高效和精准。
嵌入文档
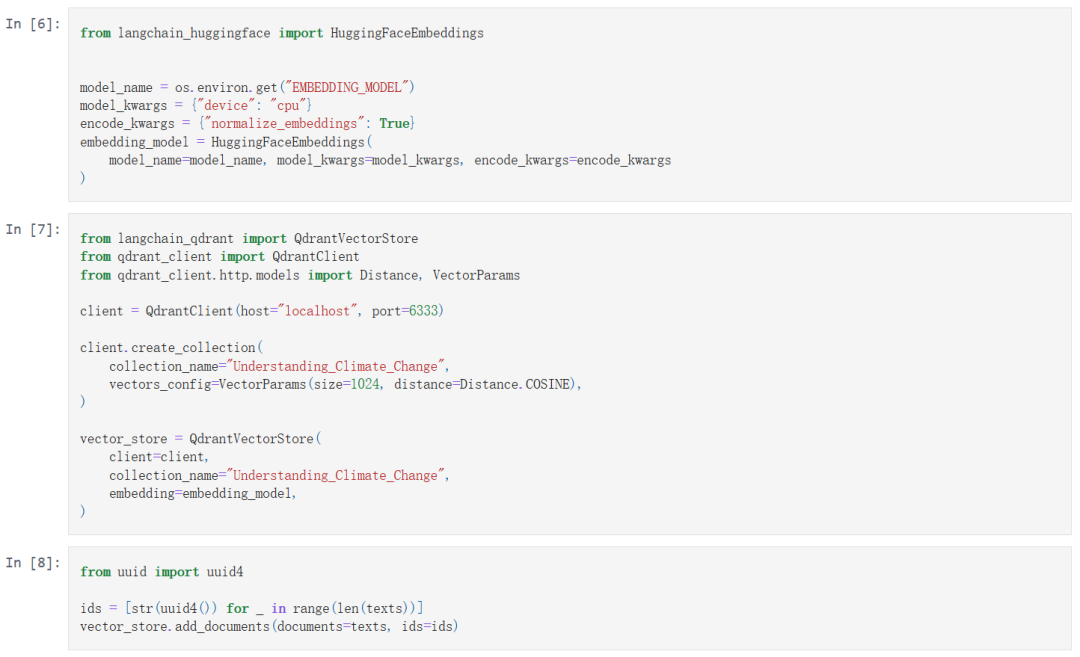
现在进入了关键阶段,我们将上一步的文档进行嵌入处理,具体来说:
-
导入本地的嵌入模型,我使用了 bge-m3 模型,这个模型支持中英文嵌入,稍后就能看到效果了。
-
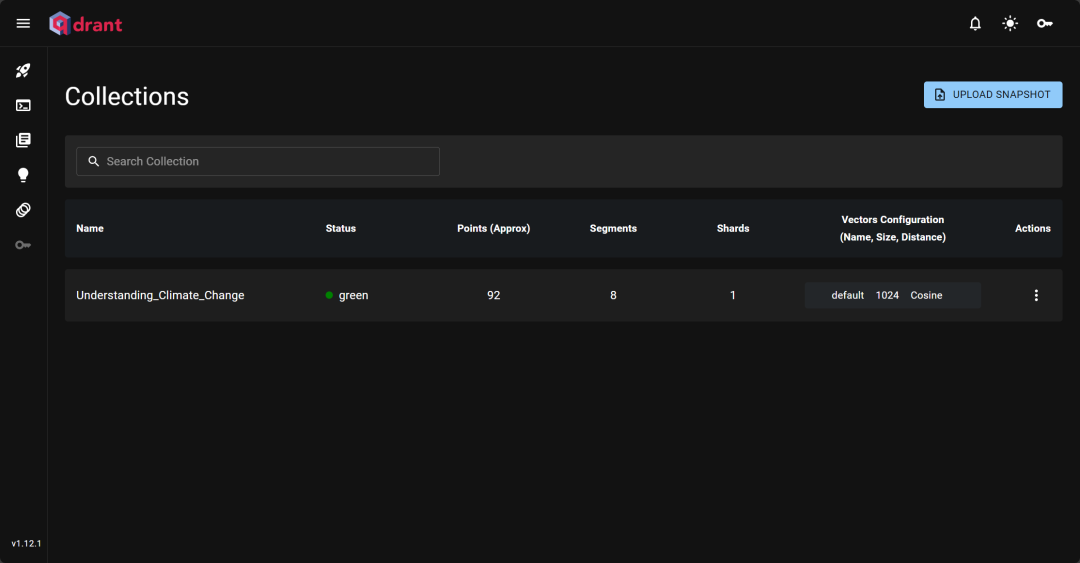
初始化向量数据库,我使用了 Qdrant 向量数据库。你可以看这一篇文章了解一下 Qdrant:《Qdrant:使用Rust编写的开源向量数据库&向量搜索引擎》。
-
将文本向量插入向量数据库中。
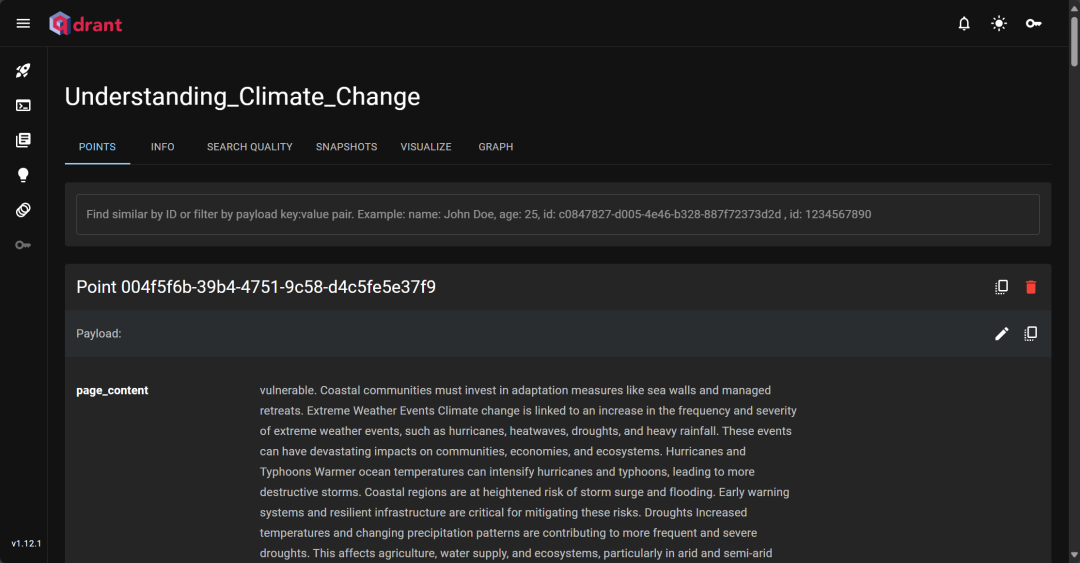
检索
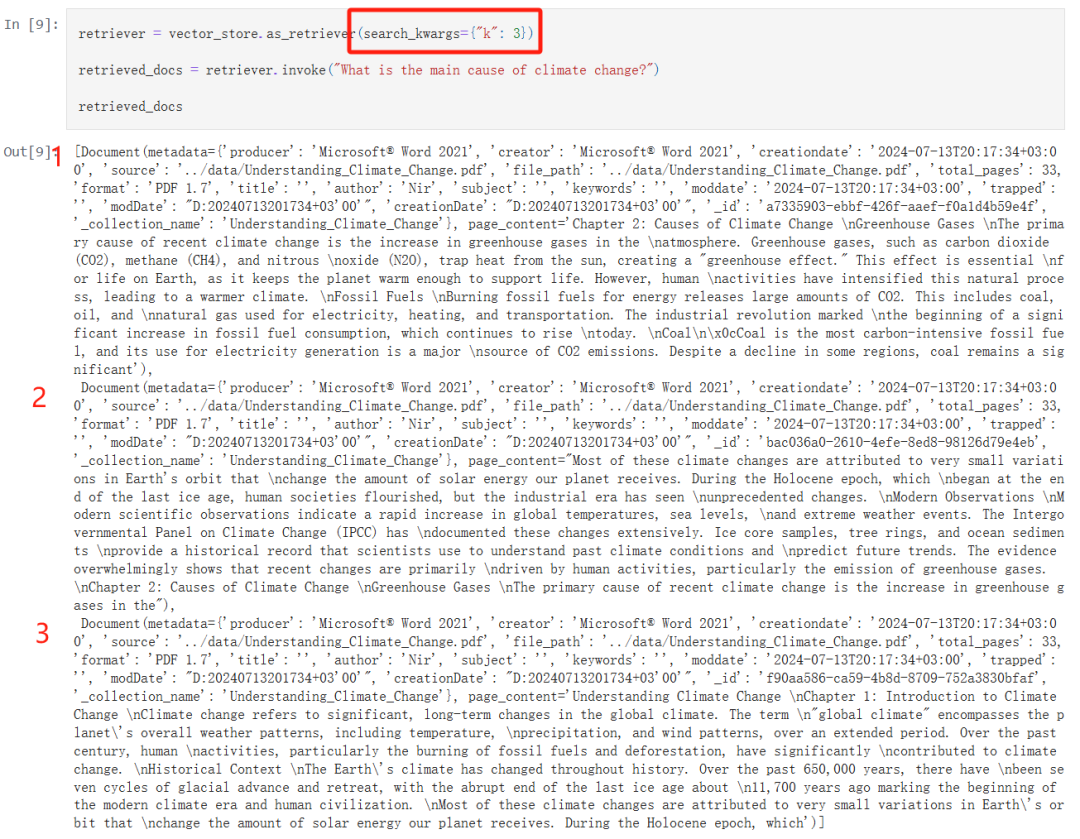
现在我们便可以使用语义检索了:
-
我通过 search_kwargs={“k”: 3} 指定了每次检索只返回前三个最相关性大的文本。
-
我通过中英文的方式进行了检索,验证了一下 bge-m3 的嵌入效果非常好,检索到的结果是一致的。
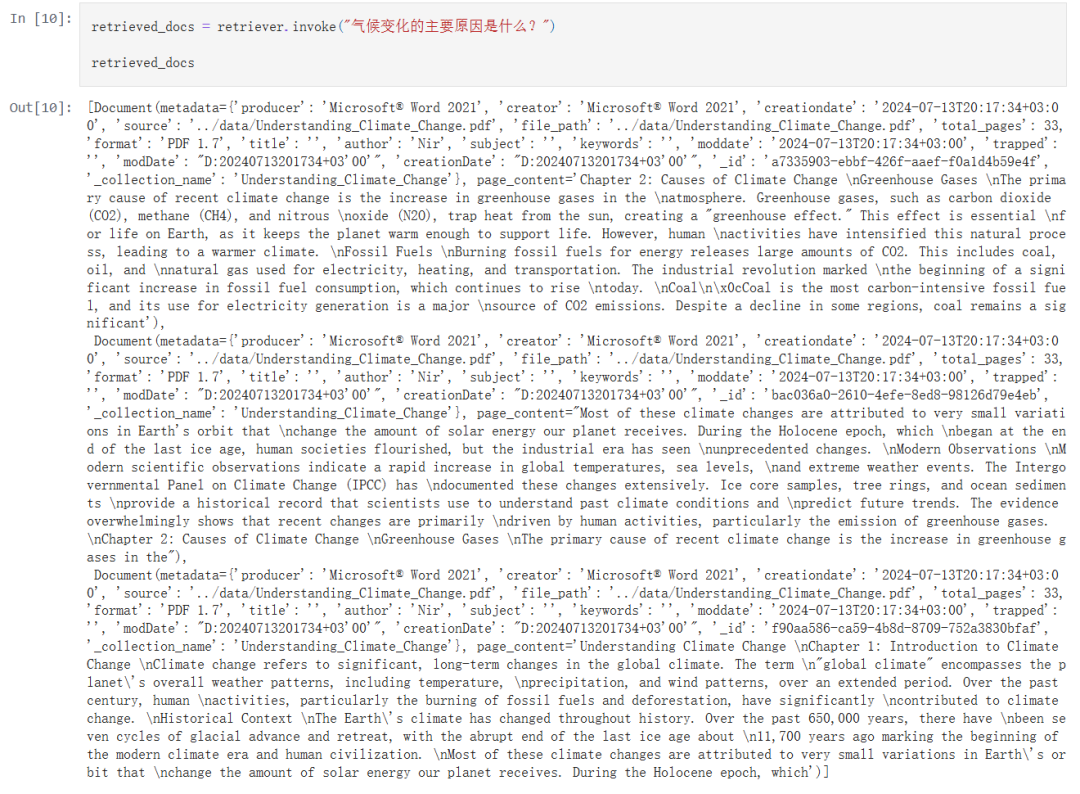
检索增强生成
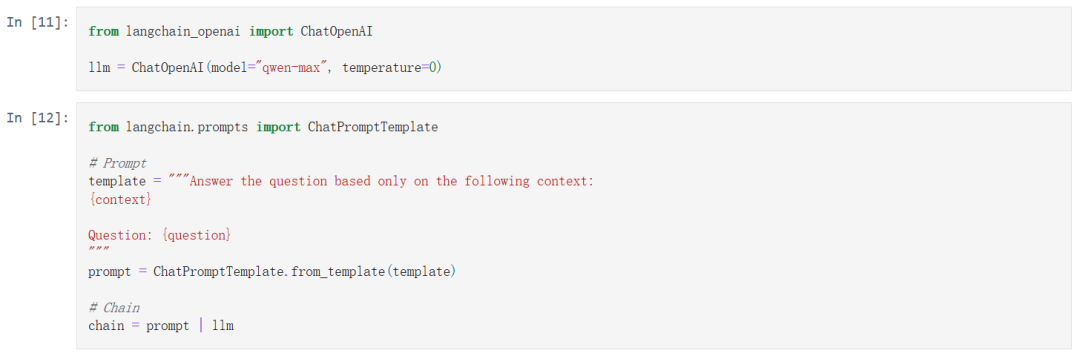
首先我使用以 OpenAI API 兼容的方式调用了 Qwen-max 模型,并通过简单的 RAG 提示构建了一个链 chain。
接下来我们将开始先后使用英文和中文去询问:

结果非常不错,即使我们的原始文档知识库是英文、LLM 提示也是英文,但是我们用中文询问时,LLM 会自动使用中文回答。
最终我将上述所有的过程组成一个完整的 RAG 链:
为了能够提升代码复用率,我将本文中的关键部分抽取出来了,放到了 helper_functions.py 中。
本文源代码:
https://github.com/realyinchen/RAG/blob/main/RAG101/001-SimpleRAG.ipynb
https://github.com/realyinchen/RAG/blob/main/RAG101/helper_functions.py
文章来源:PyTorch研习社

(文:PyTorch研习社)