

今天是2025年3月12日,星期三,北京,天气晴。
先说一个文档解析的怪事儿,word解析,应该老老实实解析底层xml,转pdf再解析(有很多现成的工具库了),绕了大圈,效果还不保证,例如表格,除非里面是贴的图片这个时候则单独做解析即可。
另外,我们继续来看看Agent的一些事,两方面,一个是标准化设施建设,一个是工具调用规划能力训练框架,这都是基建层面的事儿,可以跟进。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、Agent标准化设施几再思考
关于agent,OpenAI 放出来新的agent 开发套件,https://openai.com/index/new-tools-for-building-agents/,其实就是 Responses API,简化智能体开发的核心工具。
例如,Responses API采用了统一的基于项目的结构,简化了多态性处理,使得开发者在处理不同类型的数据和响应时更加方便,提供了直观的流式事件处理机制,让开发者可以更轻松地处理和响应模型的实时输出。引入了如response.output_text等 SDK 辅助工具,方便开发者快速获取模型的文本输出。
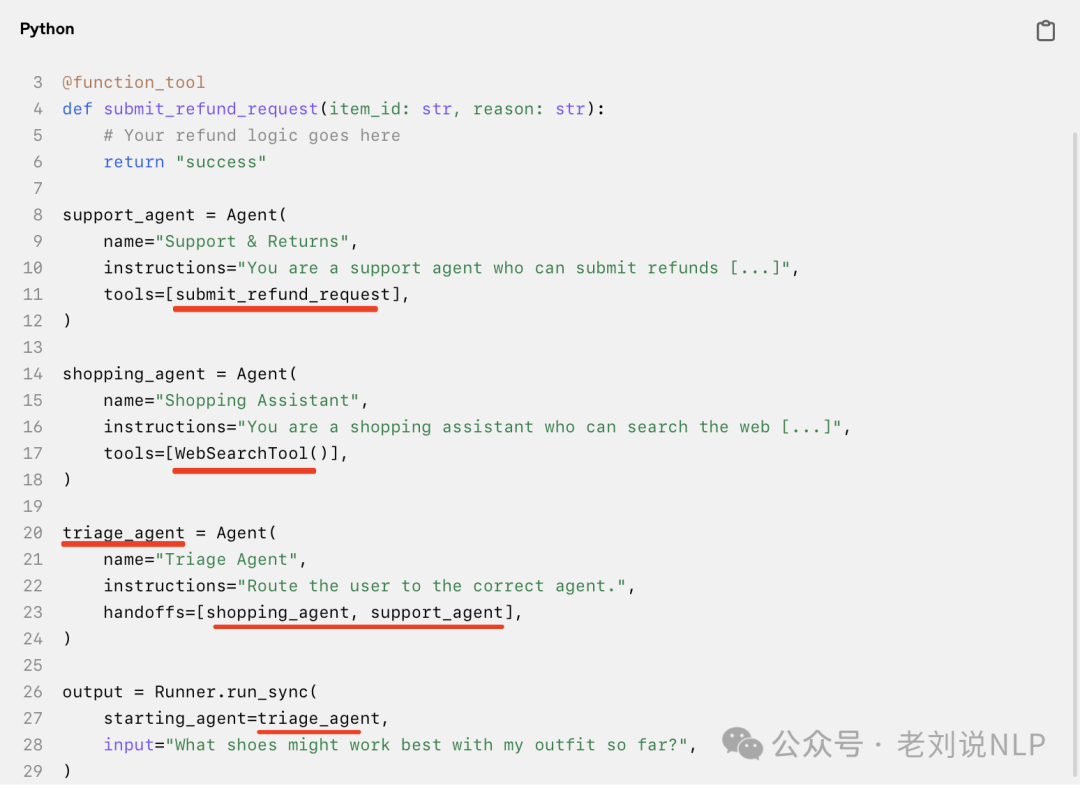
上述代码就是一个例子,agent中可以封装另一个agent,再包一层。
这其实说明了一个问题,那就是agent这块框架在往标准化走。
事实上,工程、工具使用会日趋标准化跟完善化的。比如MCP,MCP虽然没啥新意,但成为事实标准的希望很大,因为事实上需要这个东西,它可以作为Agent能力的一个扩展坞,增强工具调用这些的能力广度。mcp目前最大的问题还是鉴权这块功能基本没有 不过社区很多人提了,估计官方很快会加。
但是呢,出现那么多Agent工具框架,是否也会走向大一统呢? 是否都会受到冲击呢?,例如https://github.com/WangRongsheng/awesome-LLM-resourses中做的agent工具的归类,长达30个。

当然,我们会进一步去想,这两年模型基础能力和工具都攒了很多,现在随着基座能力的变强,如何规范化地使用这些工具其实也需要提上日程。
在这里,说下一个有趣的点,有个朋友提到LLM+workflow!=Agent,这个是认同的,agent最本真的,必定是自主的而不是一套规则系统。但是呢,这是未来趋势,不是现实。
那么为什么会出现现在的LLM+workflow==Agent这样的局面,是因为一开始要通用,然后做着做着发现没法通用,然后就只能workflow应付了,这其实归根结底还是需求认识不够导致。但现在回过头来看,又起来agent,讲真正的agent。是因为后期的包装很漂亮,视觉冲击有了一些,又燃起了一起兴趣。
当然,这又是一次迭代升级,至少从技术上来说,很令人振奋。
二、OpenManus-RL增强Agent的规划能力框架
增强agent的规划能力是个有趣的话题,如何去实现,最直接的方式就是强化学习,所以可以看,OpenManus-RL,LLM Agents开发的强化学习微调开源项目: https://github.com/OpenManus/OpenManus-RL,
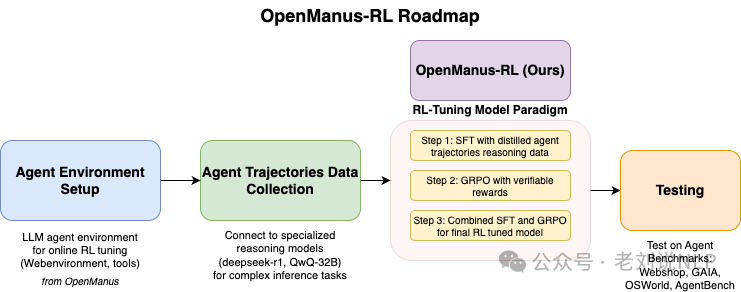
可以看看采用的方案实现路径:

在数据数据的合成上,可以使用如下方式
思维树(ToT),基于树的推理路径,使代理能够系统地探索分支可能性;
思维图(GoT),利用图结构有效表示复杂的推理依赖关系;
深度优先搜索决策树(DFSDT),通过深度优先搜索优化动作选择,增强长时规划;
蒙特卡洛树搜索(MCTS),概率地探索推理和决策路径,有效平衡探索和利用。
在推理数据样本上,有几种推理输出格式。
ReAct,明确集成推理和行动,鼓励结构化决策;基于结果的推理,优化明确的预期结果预测,推动目标对齐。
数据集也有一些开源的,包括:

例如,
Agent-FLAN,地址在:https://huggingface.co/datasets/internlm/Agent-FLAN
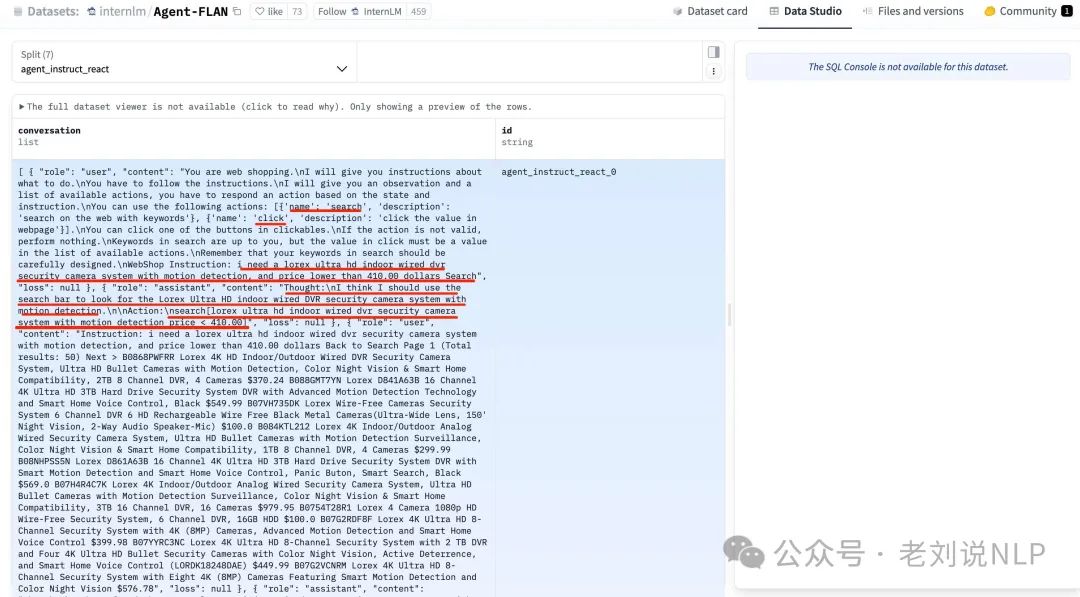
AgentInstruct,地址在:https://huggingface.co/datasets/THUDM/AgentInstruct

在基座模型的选型上,可以使用GPT-O,Deepseek-R1,QWQ-32B。
在后训练策略上,可以分为多种路径:
监督微调(SFT),使用人类注释的指令初始化推理能力;
基于广义奖励的策略优化(GRPO):基于格式的奖励:奖励遵循指定推理结构的程度,基于结果的奖励:奖励准确的任务完成和目标达成。
近端策略优化(PPO):通过近端更新增强代理稳定性。
直接偏好优化(DPO):利用明确的人类偏好直接优化代理输出。
基于偏好的奖励建模(PRM):使用从人类偏好数据中学习到的奖励函数。
基于这些数据,可以训练agent奖励模型。这个项目提供的是一套框架,但具体应该如何实现,核心还是怎么做符合特定场景的agent工具。
总结
本文主要介绍了Agent相关标准化的一些进展以及OpenManus-RL增强Agent的规划能力框架,工具层和标准层越来越多,这两年出现的多个agent框架,后续也可能会走向大一统。
大家可以多关注。
参考文献
1、https://github.com/OpenManus/OpenManus-RL
2、https://openai.com/index/new-tools-for-building-agents
(文:老刘说NLP)