

你知道吗,除了ChatGPT,AI 世界还有另一大基石——BERT!
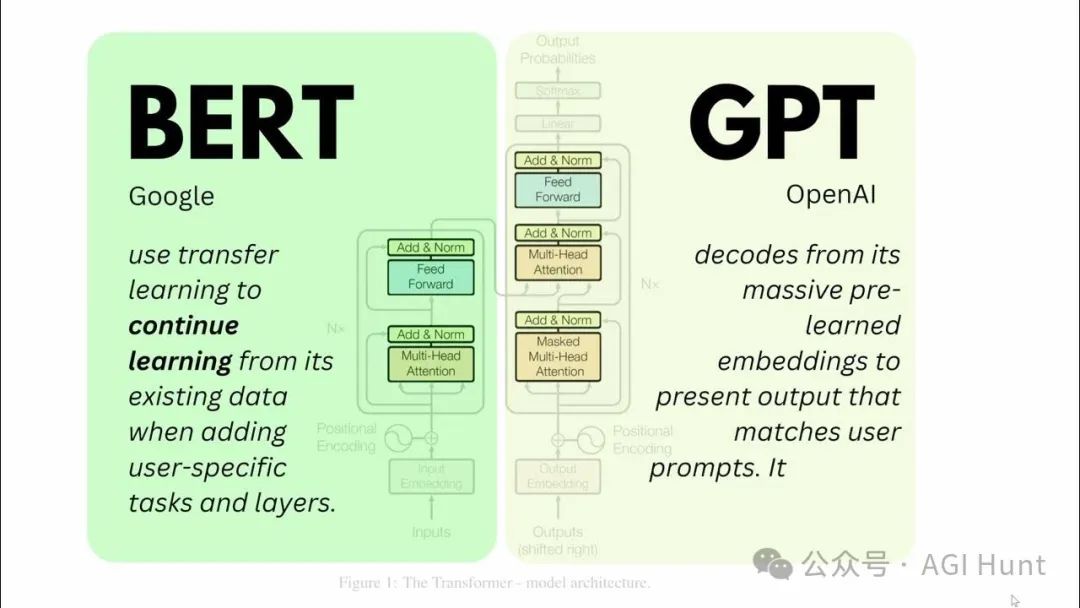
当我们被ChatGPT、Claude、Grok、DeepSeek 这些对话式 AI 迷得神魂颠倒时,却很少有人意识到,这些模型仅仅代表了AI语言模型的一个分支——解码器(Decoder)。
而在AI基础设施的另一端,编码器(Encoder) 模型如BERT默默支撑着搜索引擎、信息检索、文本分类等核心应用。
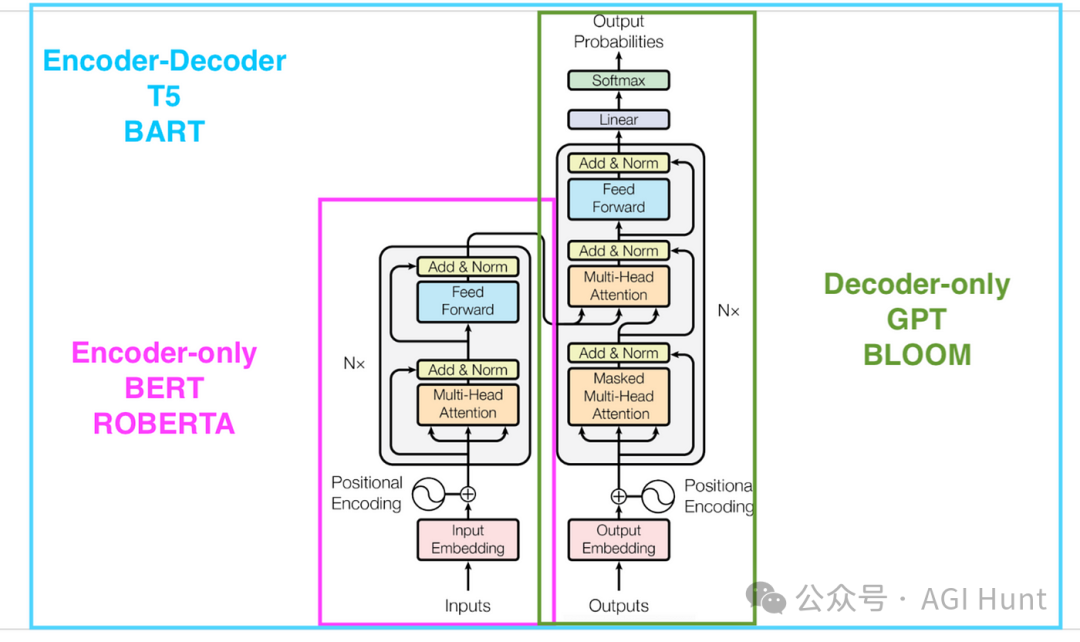
虽然ChatGPT可以生成连贯文本和回答问题,但它无法像BERT那样深入理解文本的双向语境。这就像左右脑分工,各有所长。
现在,BERT家族终于迎来了真正的全面升级!

Mila和Polytechnique Montreal的研究团队刚刚发布了NeoBERT,这是一个经过2.1万亿token训练的下一代编码器模型,堪称BERT家族的超级进化版!

过去几年里,GPT、Llama等自回归模型一直在快速发展,而BERT这类双向编码器却进步缓慢。
这个局面终于被打破了!
NeoBERT:远超所有基线
让人震惊的是,在标准的MTEB基准测试中,NeoBERT以完全相同的微调条件轻松超越了所有基线模型,包括BERT large、RoBERTa large、NomicBERT和ModernBERT!
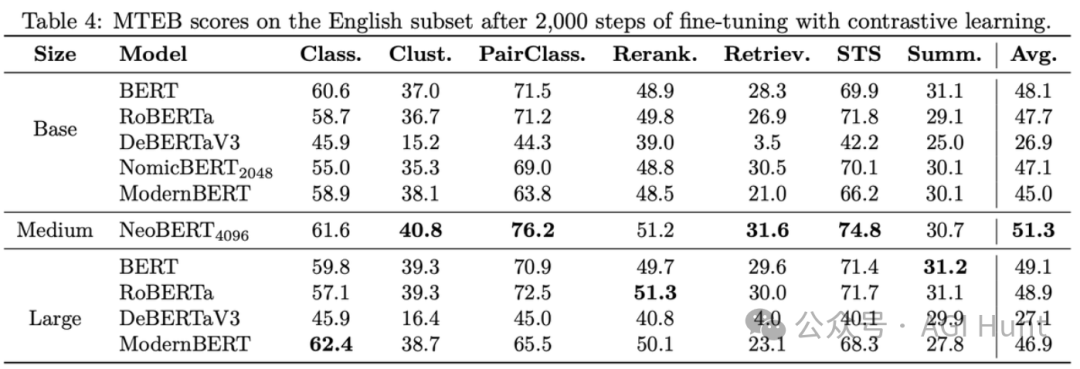
这个全面的MTEB基准覆盖了7个任务和56个数据集,是评估编码器性能的最权威标准之一。这意味着NeoBERT在文本检索、分类、聚类等多种下游任务中都表现出色。
不仅如此,它还带来了一系列令人眼前一亮的创新功能:
-
原生4096上下文长度(是RoBERTa的8倍,NomicBERT的2倍)
-
优化的深度宽度比(28层 × 768隐藏层大小)
-
精巧的250M参数设计(比典型的large模型少100M)
-
同类最高推理速度(显著快于ModernBERT)
这些进步并非偶然。
Sarath Chandar教授的团队在正式预训练NeoBERT之前,先进行了大规模的消融实验,预训练了9个不同的模型来验证各种设计选择。
这些模型都是在BERT的规模(1M步,131k批次大小)上进行的,通过严格控制种子和数据加载器状态,确保实验的可比性。
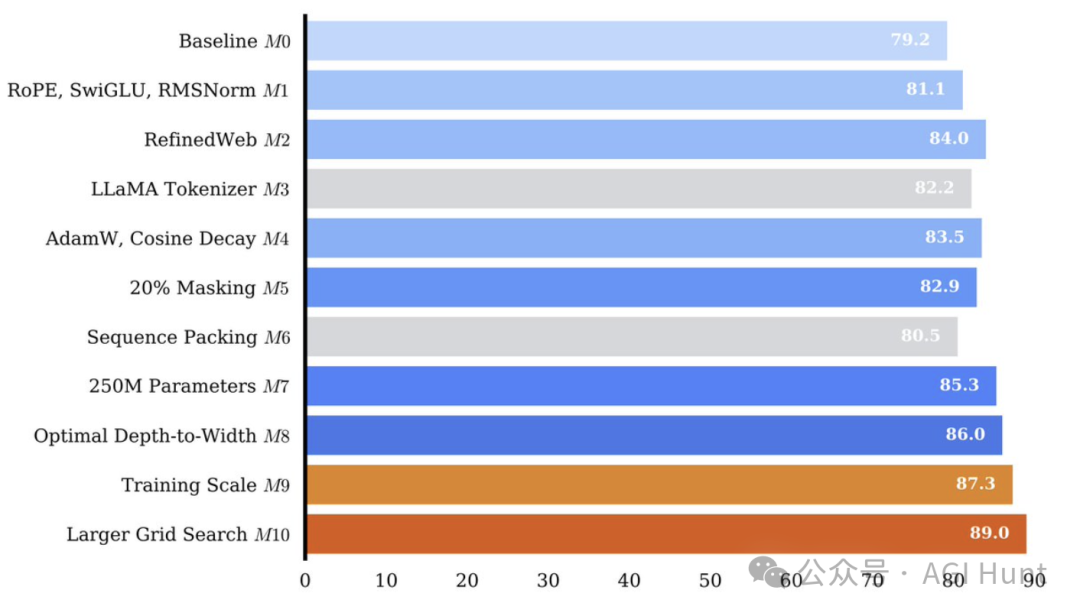
架构革新:从黑盒到白盒
NeoBERT背后的架构改进值得每个NLP开发者深入了解。团队基于最新的理论研究,对传统BERT架构进行了系统性改造:
1. 深度宽度比优化
传统小型语言模型如BERT和RoBERTa处于宽度低效状态。Levine等人的研究表明,在Transformer中存在最优的深度宽度比。为此,NeoBERT:
-
保持了原始BERTbase的768宽度
-
增加深度至28层
-
实现了最佳参数分配,获得显著性能提升
# BERT base配置bert_config = {"hidden_size": 768,"num_hidden_layers": 12,"num_attention_heads": 12}# NeoBERT配置neobert_config = {"hidden_size": 768, # 保持宽度不变"num_hidden_layers": 28, # 增加深度"num_attention_heads": 12}
2. 位置编码革新
BERT和RoBERTa使用的绝对位置嵌入存在两个关键问题:
-
难以泛化到更长序列
-
位置信息需要跨层传播
NeoBERT采用了旋转位置嵌入(RoPE),直接将相对位置信息整合到自注意力机制中:
# 旋转位置嵌入(RoPE)实现核心def apply_rotary_pos_emb(q, k, cos, sin):q_embed = (q * cos) + (rotate_half(q) * sin)k_embed = (k * cos) + (rotate_half(k) * sin)return q_embed, k_embed
RoPE不仅提升了性能,还带来了惊人的外推能力。
结合YaRN扩展,NeoBERT可以处理远超预训练长度的序列,这对长文本处理至关重要。
3. 归一化层革命
NeoBERT将归一化层移到了每个前馈和注意力块的残差连接内部(Pre-Layer Normalization),并用RMSNorm替代了经典LayerNorm:
# LayerNorm vs RMSNormclass LayerNorm(nn.Module):def forward(self, x):mean = x.mean(dim=-1, keepdim=True)var = x.var(dim=-1, keepdim=True, unbiased=False)return self.weight * (x - mean) / torch.sqrt(var + self.eps) + self.biasclass RMSNorm(nn.Module):def forward(self, x):# 只计算一个统计量,计算效率更高norm = torch.sqrt(torch.mean(x * x, dim=-1, keepdim=True) + self.eps)return self.weight * x / norm
这种组合带来了:
-
更高的训练稳定性
-
更大的学习率可能性
-
更快的模型收敛速度
-
略低的计算复杂度
4. 激活函数升级
NeoBERT抛弃了传统的GELU激活函数,引入了SwiGLU激活,显著提升了模型性能:
# GELU vs SwiGLUdef gelu(x):return 0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * x**3)))def swiglu(x, w1, w2, v):return (torch.sigmoid(w1 @ x) * w2 @ x) @ v
由于SwiGLU引入了第三个权重矩阵,团队将隐藏单元数量缩放为原来的2/3,以保持参数总量不变。
精心设计的训练策略
数据创新
数据质量和规模是预训练的关键。
NeoBERT的训练数据相比传统模型有了质的飞跃:
-
使用RefinedWeb:容量达2.8TB,包含600B tokens
-
比RoBERTa大18倍:远超RoBERTa的160GB数据集
-
比BERT/NomicBERT大215倍:这两者仅使用了13GB数据
-
2023年最新数据:包含最新知识,而BERT/RoBERTa的数据停留在2019年
# 数据集规模对比datasets = {"BERT/NomicBERT": "13GB (BooksCorpus + Wikipedia)","RoBERTa": "160GB (多源数据)","NeoBERT": "2.8TB (RefinedWeb)"}
上下文长度扩展
团队采用了两步训练策略来扩展模型的上下文窗口,兼顾性能和计算成本:
-
第一阶段:序列长度1024,训练100万步(2万亿token)
-
第二阶段:序列长度4096,额外训练5万步(1000亿token)
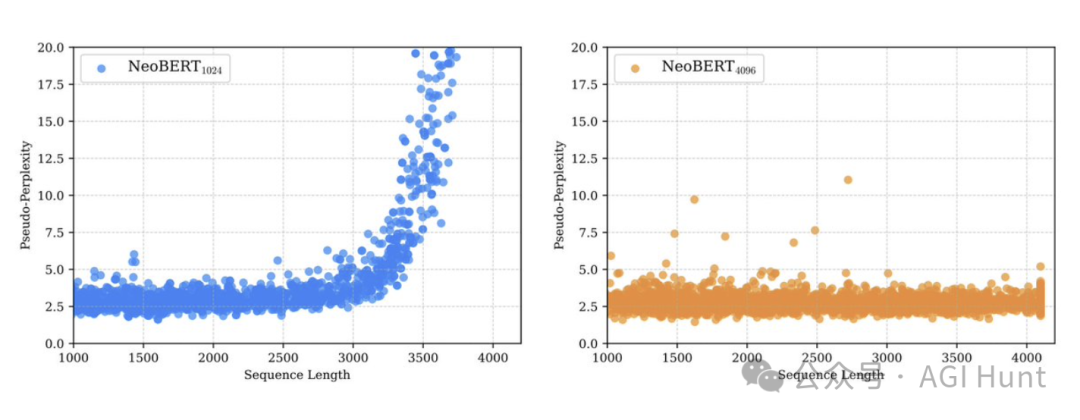
为确保模型在第二阶段接触到足够的长序列,团队创建了特殊子数据集:
# 长序列训练策略second_stage_datasets = {"Refinedweb": "20%", # 原始数据集"Refinedweb1024+": "40%", # 只包含>1024 token的序列"Refinedweb2048+": "40%" # 只包含>2048 token的序列}
这种方法缓解了长序列通常带来的分布偏移问题,因为长文本往往代表更复杂或学术性内容。
预训练优化
NeoBERT的预训练过程融合了针对编码器的特定修改和广泛接受的解码器改进:
掩码语言建模改进
基于Wettig等人的研究,NeoBERT采用了20%的掩码率(而非BERT的15%或NomicBERT的30%)。
这个比例对base模型来说是最优的——模型在训练任务难度与其能力匹配时学习效果最佳。
优化器与学习率调度
NeoBERT使用AdamW优化器,配置与LLaMA 2相同:
-
β₁=0.9
-
β₂=0.95
-
ε=10⁻⁸
-
权重衰减0.1
-
梯度裁剪最大范数1.0
学习率调度精心设计:
# 学习率调度scheduler = {"warmup": "线性预热2000步","peak_lr": 6e-4,"decay": "余弦衰减至峰值的10%(训练90%的步数)","final_phase": "最后10万步保持恒定学习率"}
大规模训练
NeoBERT的训练规模令人印象深刻:
-
批次大小:2M tokens
-
训练步数:1M步(第一阶段)+ 5万步(第二阶段)
-
总训练tokens:2.1万亿(理论值)
这相当于:
-
与RoBERTa 相同的token量
-
比NomicBERT 多2倍token
-
比RoBERTa 多2倍训练步数
-
比NomicBERT 多10倍训练步数
训练效率提升
为实现如此大规模训练,团队采用了多项效率优化技术:
# 效率优化清单optimizations = ["DeepSpeed+ZeRO并行化", # 减少内存使用"xFormers库融合操作", # 减少计算开销"尺寸对齐64的倍数", # 适配GPU架构"移除偏置简化计算", # 不影响性能"FlashAttention", # 精确计算注意力无需存储完整矩阵]
Sarath Chandar(@apsarathchandar)也不忘提及其他相关工作:
值得一提的是ModernBERT (https://arxiv.org/abs/2412.13663),这是另一个很棒的并行努力,目标也是modernize BERT,但有一些不同,详见我们的论文!
开发者实用指南
完整安装与使用
想要立即尝试NeoBERT,只需要几行代码:
# 安装依赖!pip install transformers torch xformers==0.0.28.post3# 如果需要序列打包(去除填充),还需安装flash-attention!pip install flash_attn# 加载模型和分词器from transformers import AutoModel, AutoTokenizermodel_name = "chandar-lab/NeoBERT"tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)model = AutoModel.from_pretrained(model_name, trust_remote_code=True)# 生成文本嵌入text = "NeoBERT是同类中最高效的模型!"inputs = tokenizer(text, return_tensors="pt")outputs = model(**inputs)embedding = outputs.last_hidden_state[:, 0, :]print(embedding.shape) # [1, 768]
实际应用场景
NeoBERT特别适合以下任务:
-
检索增强生成(RAG):更准确的文档检索
-
文本分类:包括情感分析、毒性检测等
-
问答系统:更精准的答案提取
-
文本聚类:改进无监督学习算法
-
信息抽取:从非结构化文本中提取结构化信息
对于需要嵌入大量文本数据的开发者,NeoBERT提供了显著的效率和性能提升。
全面开源
最令人振奋的消息是——团队完全开源了所有内容,包括中间模型检查点!
# NeoBERT资源resources = {"模型": "https://huggingface.co/chandar-lab/NeoBERT","论文": "https://arxiv.org/abs/2502.19587","代码和检查点": "即将发布"}
与其他编码器不同,NeoBERT是唯一完全开源的同类模型,团队发布了:
-
代码
-
数据
-
训练脚本
-
模型检查点
这种开放态度让NeoBERT不仅是一个技术突破,更是一个真正平民化的AI工具,让更多研究者和开发者能够访问这一强大的资源。
不少研究者对此表示欢迎。Jacob Portes(@JacobianNeuro)表示:
非常酷!你可能会发现CrammingBERT和MosaicBERT也很相关。
他还提了一个有趣的问题:
非常彻底的分析!在这种情况下,你对编码器与解码器的看法是什么?
NeoBERT vs 传统编码器:全方位对比
为了让开发者更清晰地了解NeoBERT的优势,这里提供了与主流编码器的详细对比:
|
|
|
|
|
|
NeoBERT |
|---|---|---|---|---|---|
|
|
|
|
|
|
28 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
250M |
|
|
|
|
|
|
SwiGLU |
|
|
|
|
|
|
RoPE |
|
|
|
|
|
|
Pre-RMSNorm |
|
|
|
|
|
|
2.8TB |
|
|
|
|
|
|
|
|
|
|
|
|
|
1,024→4,096 |
|
|
|
|
|
|
20% |
|
|
|
|
|
|
2.1T |
未来展望与实用建议
NeoBERT的出现标志着编码器模型进入了新时代。对于开发者而言,这意味着:
-
现有BERT基础应用可以无缝升级:NeoBERT保持了与base模型相同的隐藏层大小,允许直接替换。
-
处理长文本的能力大幅提升:4096的上下文长度足以处理大多数实际应用场景中的长文本。
-
性能提升不再依赖庞大参数量:NeoBERT证明了精心设计的架构和更好的训练数据可以替代简单地增加参数量。
-
新一代嵌入模型的基础:NeoBERT为未来的GTE、jina-embeddings、SFR-embeddings等高级嵌入模型提供了更强大的预训练基础。
对于考虑在项目中使用NeoBERT的开发者,这里有一些实用建议:
# NeoBERT最佳实践best_practices = {"批处理": "利用NeoBERT的高效推理,增加批大小","微调": "从小学习率开始(1e-5),用余弦衰减","长文本": "考虑使用YaRN进一步扩展上下文窗口","内存优化": "运用梯度检查点和混合精度训练降低内存需求"}
NeoBERT的不仅为NLP应用提供了更强大的基础,还证明了双向编码器仍然有广阔的发展空间。
通过将最新的架构创新和训练方法应用到编码器模型中,NeoBERT重新定义了编码器的能力边界。
而NeoBERT的意义,不仅在于编码器领域的重大突破,还在于它与ChatGPT等解码器的互补关系。
当我们沉浸在ChatGPT流畅生成的对话中时,背后可能正是编码器模型如NeoBERT在默默支撑整个系统的检索和理解能力。
这种互补性正是AI技术生态的未来:生成式AI负责对话和创作,理解式AI负责深度解析和精准检索。
随着NeoBERT的开源,或许有理由相信,下一代RAG系统、搜索引擎、推荐系统将迎来质的飞跃。编码器的春天已经到来,而这仅仅是开始。
虽然在AI双轮驱动的未来,ChatGPT可能是台前更受瞩目的明星,但别忘了,NeoBERT这样的幕后编码器模型才是支撑整个AI理解能力的基石。
编码器理解世界,解码器表达世界。
或许,这才是AI的完整图景。
相关链接
-
论文链接:NeoBERT: A Next-Generation BERT https://arxiv.org/abs/2502.19587 -
模型下载:HuggingFace – chandar-lab/NeoBERT https://huggingface.co/chandar-lab/NeoBERT -
GitHub仓库:https://github.com/chandar-lab/NeoBERT -
相关工作:ModernBERT https://arxiv.org/abs/2412.13663 -
研究团队:Sarath Chandar实验室 https://chandar-lab.github.io/
(文:AGI Hunt)