
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
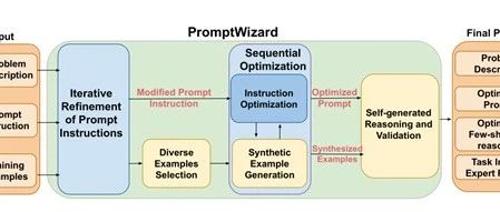
微软研究院发布了一个创新框架Prompt Wizard,主要用于优化大模型的提示,以提升在数学、科研、金融、法律等各种任务中的表现。
Prompt
Wizard的核心由多个模块组成,通过其自我进化和自我适应的机制以及反馈驱动的批评和综合过程,实现了对大模型提示指令和上下文示例的迭代优化。

开源地址:https://github.com/microsoft/promptwizard
首先,PromptWizard会对问题的清晰表述和初始提示进行设定,这为整个优化过程奠定了基础。研究人员首先定义了一个问题描述,例如“让我们一步一步思考来解决这个数学问题”,并结合一系列以问题-答案对的训练样本,为PromptWizard提供了一个起点,使其能够开始探索和优化提示。
接着,PromptWizard进入迭代优化提示指令的阶段,由变异组件(Mutate
Component)主导。变异组件利用预定义的认知启发式或思考风格,对初始提示进行变异,生成多种不同的提示变体。这些思考风格引导大型语言模型从不同角度审视问题,创造出丰富多样的提示指令。

例如,可能会提出“我该如何简化这个问题?”或“是否存在其他视角?”等问题,从而提高提示指令的多样性。这种变异过程不是随机的,而是有目的的,旨在探索不同的解决方案,以找到最适合特定任务的提示。
变异组件生成的提示变体随后被送入评分组件(Scoring Component)进行评估。评分组件的任务是对这些变异提示在一小批训练样本上的表现进行打分。评分机制可以基于传统的指标,如F1分数,也可以使用大型语言模型本身作为评估器。通过这种方式,系统能够系统地识别出最有效的提示,同时淘汰表现不佳的提示。这个过程确保了只有那些真正有助于提升模型性能的提示能够进入下一步。
在评分组件筛选出表现最佳的变异提示后,批评组件开始发挥作用。批评组件通过分析大型语言模型在处理特定案例时的困难,如在GSM8k示例中解释关系或进行时间转换,来审查提示的成功和失败之处。
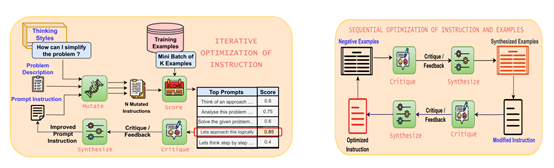
这种针对性的反馈对于精炼提示至关重要,因为它提供了对特定弱点的洞察,允许进行有针对性的改进,而不是进行一般性的更改。批评组件的反馈是具体且详细的,不仅指出提示在哪些方面做得好,更重要的是,它明确指出了提示需要改进的地方,为下一步的优化提供了明确的方向。
综合组件是迭代优化过程中的最后一个环节,利用批评组件的反馈来优化最佳提示。综合组件重新表述并增强指令,使其更具任务针对性和优化性。例如,如果反馈指出提示在解释特定关系方面存在问题,综合后的提示将直接解决这一问题,从而产生更清晰、更有效的指令,使其更接近于理想的解决方案。
在进行了初步优化之后,PromptWizard还通过CoT推理来增强模型性能。由推理组件和验证组件共同完成。推理组件接收选定的少量示例,并为每个示例生成详细的推理链,以促进问题解决。这些推理链不仅提供了从问题到答案的清晰路径,还增强了模型对任务的理解和推理能力。
验证组件则使用大型语言模型检查示例(问题、推理)的一致性和相关性,有效地过滤掉了错误的示例和/或幻觉推理,确保了最终生成的提示和示例的质量。
为了全面评估PromptWizard框架的性能,研究人员在GSM8K、AQUARAT、SVAMP、Ethos、MedQA、MMLU以及BBH等主流基准测试中进行了综合评测,涉及数学、逻辑推理、医疗问答等多个领域。
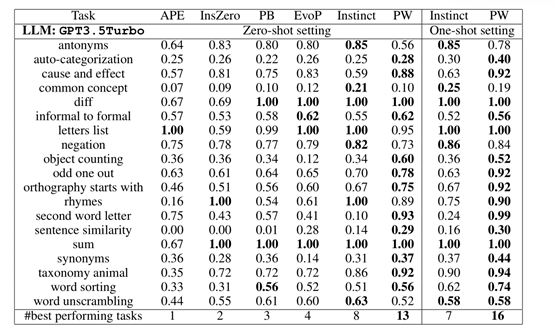
结果显示,在PromptWizard框架强化下大模型的回答能力得到了显著提升,例如,在AQUARAT测试中,大模型不仅能够准确解析复杂方程,还能清晰表达解题思路。即使在没有预训练的情况下,模型也能凭借3个few-shot样本取得优异成绩。
而在SVAMP测试中,模型在解决简单算术问题时同样表现出色,尤其是当few-shot样本数量较少时,性能提升尤为明显。
(文:AIGC开放社区)