


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
此项研究成果已被 NeurIPS 2024 录用。该论文的第一作者是杜克大学电子计算机工程系的博士生张健一,其主要研究领域为生成式 AI 的概率建模与可信机器学习,导师为陈怡然教授。
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。
针对这一问题,来自杜克大学和 Google Research 的研究团队提出了一种新的解码框架 —— 自驱动 Logits 进化解码(SLED),旨在提升大语言模型的事实准确性,且无需依赖外部知识库,也无需进行额外的微调。

-
论文地址:https://arxiv.org/pdf/2411.02433
-
项目主页:https://jayzhang42.github.io/sled_page/
-
Github地址:https://github.com/JayZhang42/SLED
-
作者主页:https://jayzhang42.github.io
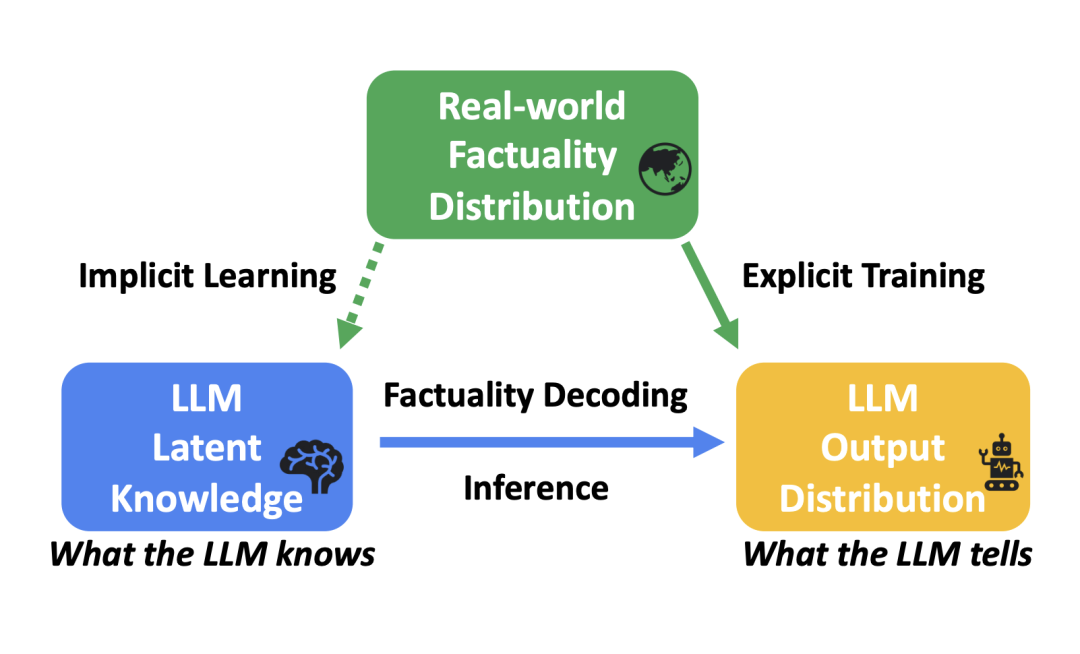 图一:Factuality Decoding 的 “三体问题”
图一:Factuality Decoding 的 “三体问题”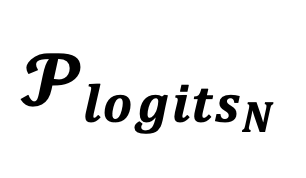 和真实事实分布
和真实事实分布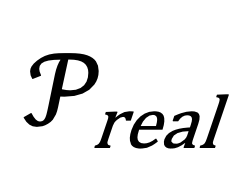 之间的差距。
之间的差距。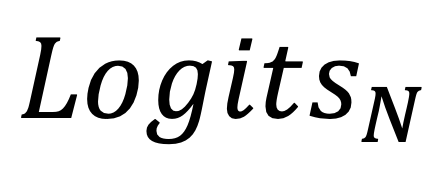 和前面几层的
和前面几层的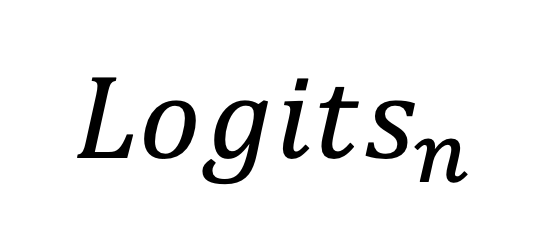 ,有效地挖掘了 LLMs 内部的潜在知识。 进行 “梯度下降” 的操作,将其整合到原始输出中,从而有效地平衡了两者,避免了过拟合等潜在的风险。
,有效地挖掘了 LLMs 内部的潜在知识。 进行 “梯度下降” 的操作,将其整合到原始输出中,从而有效地平衡了两者,避免了过拟合等潜在的风险。
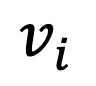 , 在输出分布
, 在输出分布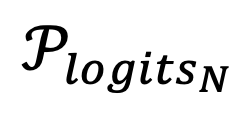 中获得更高的概率。这一过程可以通过优化以下损失函数 L 来描述
中获得更高的概率。这一过程可以通过优化以下损失函数 L 来描述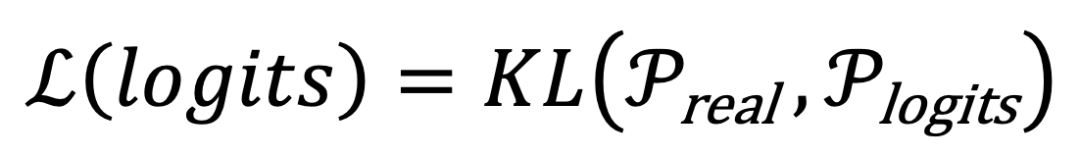 ,其中
,其中 。
。-
LLM 的训练实际上一个是由训练数据集作为外部驱动的 Logits 进化过程; -
LLM 的训练为这个优化过程找到的解就是最后一层的输出 。
对应的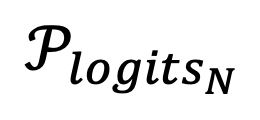 ,通常要比前面几层的输出 对应的
,通常要比前面几层的输出 对应的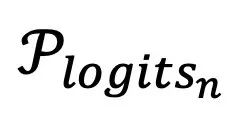 要更接近训练时的
要更接近训练时的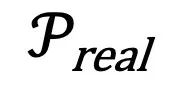 。这一点也在图三中得到了验证。
。这一点也在图三中得到了验证。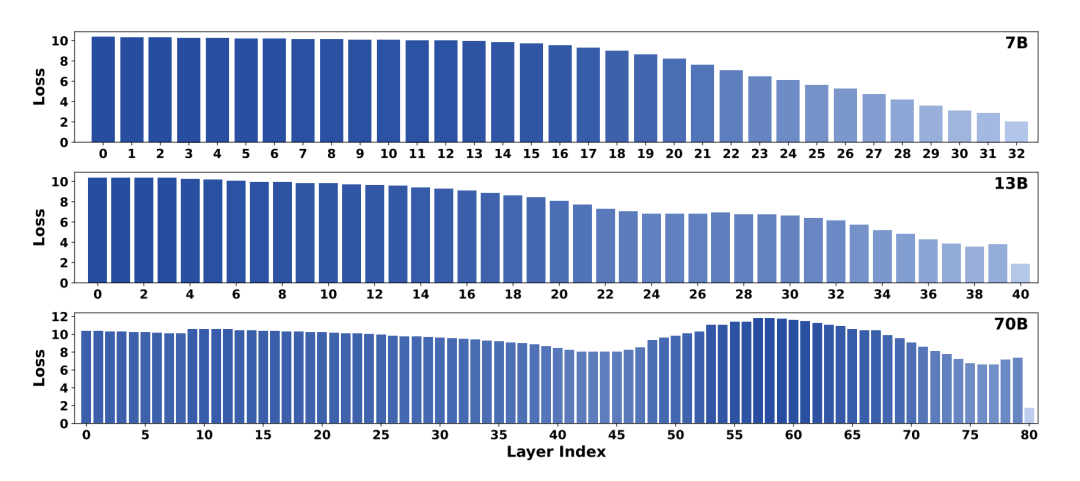
 的估计,实际上也就是之前提到的潜在知识,因此用
的估计,实际上也就是之前提到的潜在知识,因此用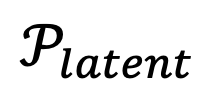 来表示。在此基础上,研究者通过类似梯度下降的方式,用估计出来的潜在知识,实现了对 自驱动进化,
来表示。在此基础上,研究者通过类似梯度下降的方式,用估计出来的潜在知识,实现了对 自驱动进化,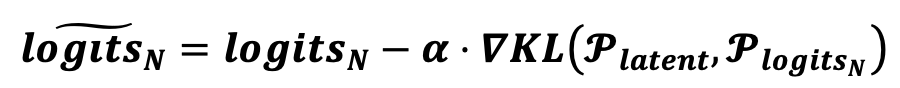
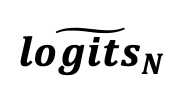 。更细节的方法设计和讨论,请参考原文。
。更细节的方法设计和讨论,请参考原文。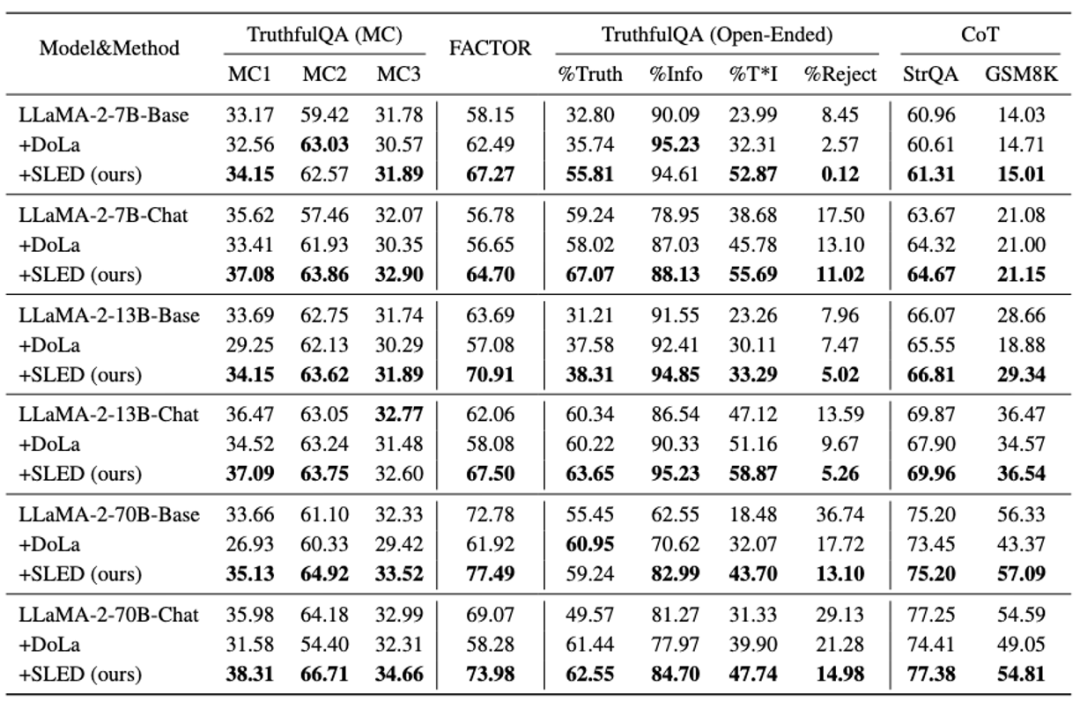


(文:机器之心)