


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 – 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。尽管这些方法已取得令人瞩目的成果,但由于 SMPL 在衣物表现上的局限性,以及缺乏大规模真实交互数据的支持,它们依然难以生成日常生活中的复杂交互场景。
相比之下,在 2D 生成模型中,由于大语言模型和海量文字 – 图片数据的支持,这一问题得到了有效的解决。2D 生成模型如今能够快速生成高度逼真的二维场景。而且,随着这些技术被引入到 3D 和 4D 生成模型中,它们成功地将二维预训练知识迁移到更高维度,推动了更精细的生成能力。然而,在处理 4D 人体 – 物体交互时,这些 3D/4D 生成的方法依然面临两个关键挑战:(1)物体与人体的接触发生在何处?又是如何产生的?(2)如何在人体与物体的动态运动过程中,保持它们之间交互的合理性?
为了解决这一问题,南洋理工大学 S-Lab 的研究者们提出了一种全新的方法:AvatarGO。该方法不仅能够生成流畅的人体 – 物体组合内容,还在有效解决穿模问题方面展现了更强的鲁棒性,为以人为核心的 4D 内容创作开辟了全新的前景。
想深入了解 AvatarGO 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

-
论文地址:https://arxiv.org/abs/2410.07164
-
Project Page:https://yukangcao.github.io/AvatarGO/
-
GitHub:https://github.com/yukangcao/AvatarGO
-
触区域定义不准确:虽然 LLM 擅长捕捉物体间的关系,但在与扩散模型结合时,如何准确定义物体间的接触区域,特别是复杂的关节结构如人体,仍然是一个难题。尽管 InterFusion [13] 构建了 2D 人体 – 物体交互数据集,旨在从文本提示中提取人体姿势,但它们仍在训练集之外的情况下,无法准确识别人体与物体的最佳接触部位。
-
4D 组合驱动的局限性:尽管 DreamGaussian4D [7] 和 TC4D [8] 利用视频扩散模型对 3D 静态场景进行动作驱动,但这些方法通常将整个场景视为一个统一主体进行优化,从而导致不自然的动画效果。尽管像 Comp4D [9] 这类项目通过轨迹为每个 3D 对象单独生成动画,但物体之间的接触建模仍然是一个巨大挑战。
-
LLM 引导的接触区域重定向(LLM-guided contact retargeting):该方法通过利用 Lang-SAM [10] 从文本中识别出大致的接触部位,并将其作为优化过程的初始化,从而解决了扩散模型在估计接触区域时的难题。
-
对应关系感知的动作优化(Correspondence-aware motion optimization):基于对静态合成模型中穿模现象较少发生的观察,AvatarGO 提出了对应关系感知的运动优化方法。该方法将物体的运动分为主动和从动部分,并利用 SMPL-X 作为中介,确保人体和物体在交互过程中保持一致的对应关系。这一创新显著提高了在运动过程中对穿模问题的鲁棒性。
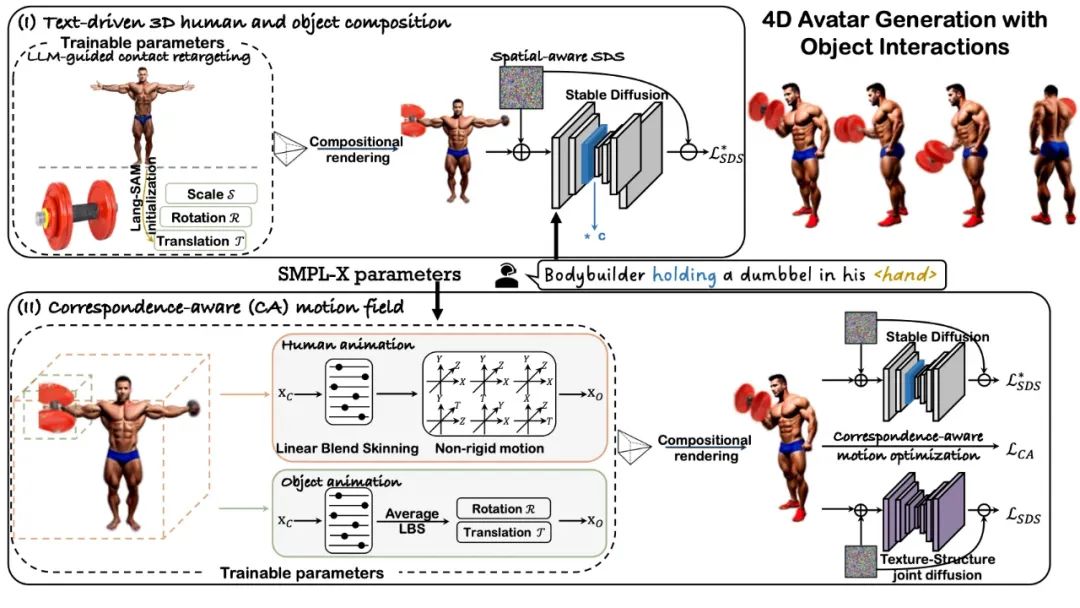
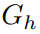 和物体
和物体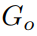 ,但 AvatarGO 的研究人员发现,即使进行手动调整,如重新缩放和旋转 3D 物体,仍然难以精确地绑定生成的 3D 人体和物体模型。为此,他们首先利用文本提示将人物和物体进行组合,通过优化其高斯属性来实现这一目标。同时,他们还优化了物体
,但 AvatarGO 的研究人员发现,即使进行手动调整,如重新缩放和旋转 3D 物体,仍然难以精确地绑定生成的 3D 人体和物体模型。为此,他们首先利用文本提示将人物和物体进行组合,通过优化其高斯属性来实现这一目标。同时,他们还优化了物体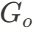 的三个可训练全局参数,包括旋转旋转
的三个可训练全局参数,包括旋转旋转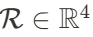 、缩放因子
、缩放因子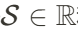 和平移矩阵
和平移矩阵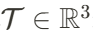 :
: 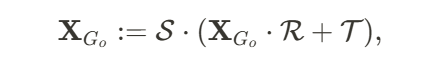
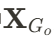 是组成物体
是组成物体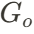 的高斯点云。
的高斯点云。  出发,AvatarGO 从正面视角渲染该模型生成图像𝐼。然后,将此图像与文本输入一起,输入到 Lang-SAM 模型中,以推导出 2D 分割掩码
出发,AvatarGO 从正面视角渲染该模型生成图像𝐼。然后,将此图像与文本输入一起,输入到 Lang-SAM 模型中,以推导出 2D 分割掩码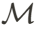 :
: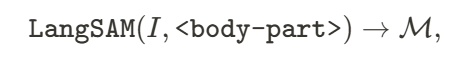
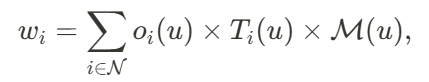
 表示第𝑖个高斯点的权重,
表示第𝑖个高斯点的权重, 是可以投影到像素 𝑢上的高斯点的集合。
是可以投影到像素 𝑢上的高斯点的集合。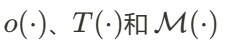 分别表示不透明度、透射率和分割掩码值。在权重更新后,他们通过将高斯点的权重与预定义的阈值𝑎进行比较,来判断一个高斯点是否对应于人体部位的分割区域。然后,AvatarGO 根据以下公式初始化平移参数
分别表示不透明度、透射率和分割掩码值。在权重更新后,他们通过将高斯点的权重与预定义的阈值𝑎进行比较,来判断一个高斯点是否对应于人体部位的分割区域。然后,AvatarGO 根据以下公式初始化平移参数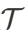 :
: 
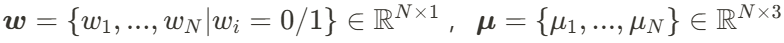 ,𝑁是人体模型
,𝑁是人体模型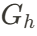 中高斯点的数量。
中高斯点的数量。 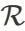 )和平移(
)和平移(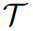 ),以提高人体与物体之间穿模问题的鲁棒性。首先,SMPL-X 的线性混合蒙皮函数(𝐿𝐵𝑆)可表达为:
),以提高人体与物体之间穿模问题的鲁棒性。首先,SMPL-X 的线性混合蒙皮函数(𝐿𝐵𝑆)可表达为: 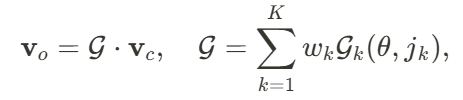
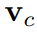 和
和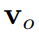 分别表示 SMPL-X 在标准空间和观察空间下的顶点。
分别表示 SMPL-X 在标准空间和观察空间下的顶点。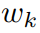 是蒙皮权重,
是蒙皮权重,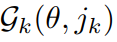 是仿射变形,可将第𝑘个关节
是仿射变形,可将第𝑘个关节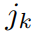 从标准空间映射到观察空间,
从标准空间映射到观察空间,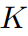 表示邻近关节的数量。
表示邻近关节的数量。 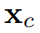 从标准空间变形到观察空间中的
从标准空间变形到观察空间中的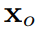 :
: 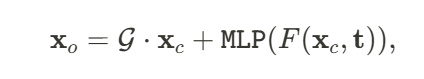
 表示基于 HexPlane 的特征提取网络, 𝑡表示时间戳。
表示基于 HexPlane 的特征提取网络, 𝑡表示时间戳。 则通过离
则通过离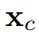 最近的标准 SMPL-X 的顶点推导得到。
最近的标准 SMPL-X 的顶点推导得到。 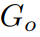 内的每个高斯点𝑥与其最近的标准 SMPL-X 顶点的变形矩阵
内的每个高斯点𝑥与其最近的标准 SMPL-X 顶点的变形矩阵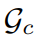 。物体的变形场则可初步被定义为:
。物体的变形场则可初步被定义为: 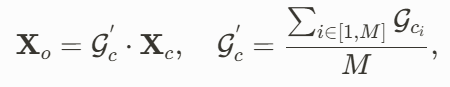
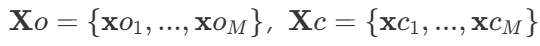 ,
,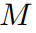 是
是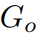 中的高斯点总数。
中的高斯点总数。 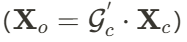 进行扩展,加入两个额外的可训练参数
进行扩展,加入两个额外的可训练参数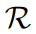 和
和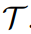 :
: 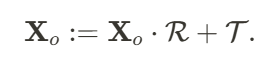
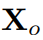 是原有运动场
是原有运动场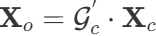 的输出。
的输出。 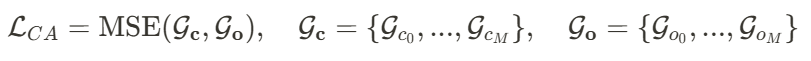
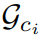 和
和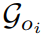 分别基于
分别基于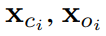 及其对应的 SMPL-X 模型得出。 除了应用 AvatarGO 提出的对应关系感知优化方法之外,作者还结合了空间感知 SDS 以及来自 HumanGaussian [12] 的纹理 – 结构联合 SDS,以增强整体质量:
及其对应的 SMPL-X 模型得出。 除了应用 AvatarGO 提出的对应关系感知优化方法之外,作者还结合了空间感知 SDS 以及来自 HumanGaussian [12] 的纹理 – 结构联合 SDS,以增强整体质量: 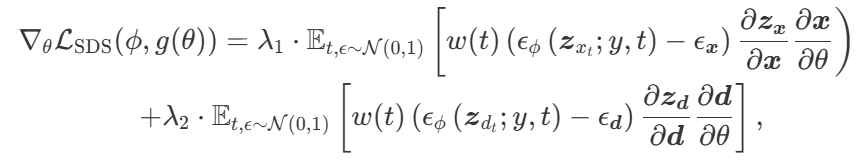
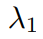 和
和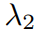 是超参数,用于平衡结构损失和纹理损失的影响,而𝑑表示深度信息。
是超参数,用于平衡结构损失和纹理损失的影响,而𝑑表示深度信息。 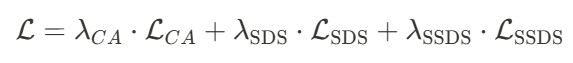
 分别表示用于平衡各自损失的权重。
分别表示用于平衡各自损失的权重。  不足以将物体移动到正确的位置。相比之下,AvatarGO 始终能够精确地实现人类与物体的交互,表现优于其他方法。
不足以将物体移动到正确的位置。相比之下,AvatarGO 始终能够精确地实现人类与物体的交互,表现优于其他方法。 
(文:机器之心)