
基于层次化强化学习(Hierachical Reinforcement Learning)思想,ReasonFlux 提出了一种更高效且通用的大模型推理范式,它具有以下特点:
-
思维模版:ReasonFlux 的核心在于结构化的思维模板,每个模版抽象了一个数学知识点和解题技巧。仅用 500 个通用的思维模板库,就可解决各类数学难题。
-
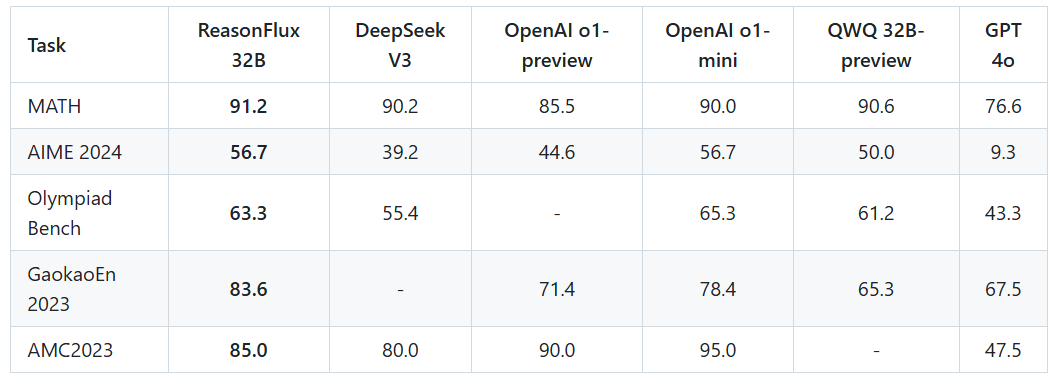
层次化推理和强可解释性:ReasonFlux 利用层次化推理(Hierarchical Reasoning)将思维模板组合成思维轨迹(Thought Template Trajectory)、再实例化得到完整回答。模型的推理过程不再是 “黑盒”,而是清晰的展现了推理步骤和依据,这为 LLM 的可解释性研究提供了新的工具和视角,也为模型的调试和优化提供了便利。与 DeepSeek-R1 和 OpenAI-o1 等模型的推理方式不同,ReasonFlux 大大压缩并凝练了推理的搜索空间,提高了强化学习的泛化能力,提高了 inference scaling 的效率。
-
轻量级系统:ReasonFlux 仅 32B 参数,强化训练只用了 8 块 NVIDIA A100-PCIE-80GB GPU。它能通过自动扩展思维模板来提升推理能力,更高效灵活。
参考文献:
[1] 文章链接:https://arxiv.org/abs/2502.06772
[2] 开源地址:https://github.com/Gen-Verse/ReasonFlux
[3] ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates:https://arxiv.org/abs/2502.06772
[4] https://huggingface.co/datasets/Gen-Verse/ReasonFlux_SFT_15k
(文:NLP工程化)