

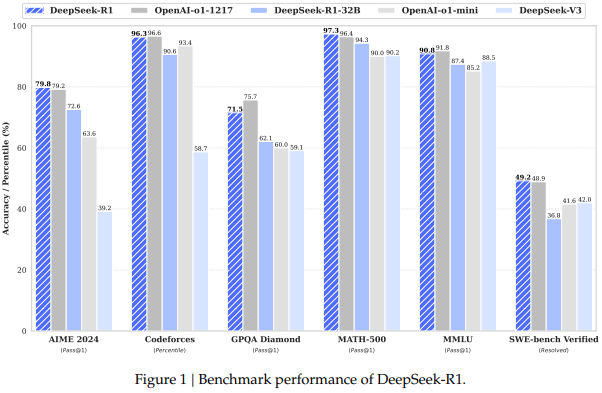
论文概述:这篇论文介绍了两种推理模型:DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero 是通过大规模强化学习(RL)训练的模型,在没有监督微调(SFT)的初步步骤下,展现出卓越的推理能力。通过强化学习,DeepSeek-R1-Zero 能够自然地展现出多种强大且有趣的推理行为,但它也面临一些问题,如可读性差和语言混杂。为了解决这些问题并进一步提升推理性能,研究者提出了 DeepSeek-R1,它结合了多阶段训练和冷启动数据,在强化学习之前进行了优化。DeepSeek-R1 在推理任务中的表现与 OpenAI 的 o1-1217 相当。

参考文献:
[1] https://arxiv.org/pdf/2501.12948
(文:NLP工程化)