


AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
而在 3D 生成模型的世界里,这一问题根本不是问题 —— 它天然支持多视角一致性。基于这一洞察,南洋理工大学 S-Lab 的研究者们提出了一种全新的框架:CityDreamer4D。它突破了现有视频生成的局限,不再简单地「合成画面」,而是直接建模城市场景背后的运行规律,从而创造出一个真正无边界的 4D 世界。
如果世界模型的终极目标是打造一个真实、可交互的虚拟城市,那么我们真的还需要依赖视频生成模型吗?不妨直接看看 CityDreamer4D 如何突破现有方案,构建出一个真正无边界、自由探索的 4D 城市世界——请欣赏它的生成效果!
想深入了解 CityDreamer4D 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

-
论文链接:https://arxiv.org/abs/2501.08983 -
项目链接:https://haozhexie.com/project/city-dreamer-4d/ -
GitHub链接:https://github.com/hzxie/CityDreamer4D
-
基于视频生成的方法(如 StreetScapes [1] 和 DimensionX [2]):依托 Video Diffusion Models(视频扩散模型),这些方法能够直接生成高质量的视频场景。然而,尽管扩散模型的能力惊人,帧间一致性仍然是一个长期未解的挑战,使得多视角的连贯性难以保证。 -
基于图像生成的方法 (如 WonderJourney [3] 和 WonderWorld [4]):利用 Image Outpainting 和 Depth 估计,这些方法可以扩展场景,但受限于仅能生成小范围区域,缺乏全局一致性。例如,在面对一条河流时,转身 180 度可能会看到毫不相关的景象,影响场景的连贯性。 -
基于程序化生成的方法(如 SceneX [5] 和 CityX [6]):通过结合大语言模型与程序化建模,这些方法能够生成结构化的城市场景。然而,场景的多样性受限于现有素材库,使得生成结果的丰富度有所局限。 -
基于 3D 建模的方法(如 CityDreamer [7] 和 GaussianCity [8]):这些方法采用显式 3D 建模,直接从数据中学习 3D 表征,从而生成空间一致的城市场景。尽管它们已解决了多视角一致性问题,但仍未突破时间维度,无法生成 4D 场景,即缺乏动态演化能力。
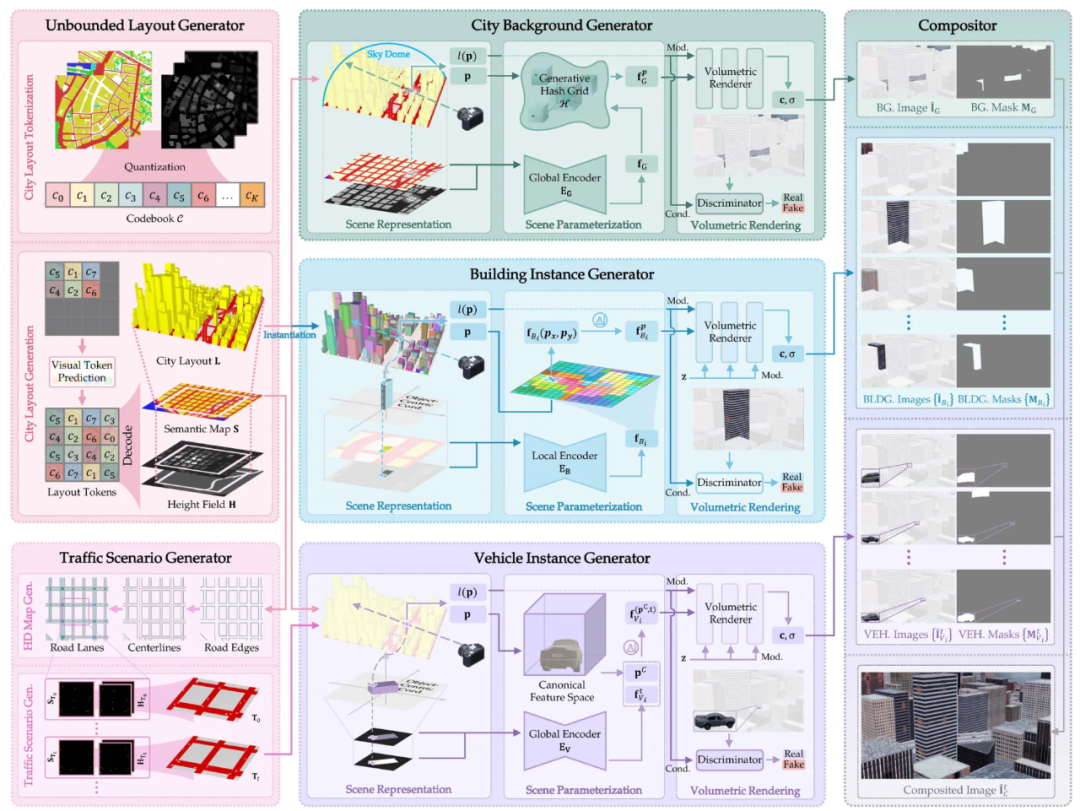
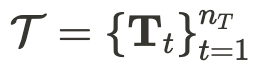 ,其中
,其中  由语义图(Semantic Map)和高度场(Height Field)共同描述:语义图
由语义图(Semantic Map)和高度场(Height Field)共同描述:语义图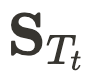 标记动态物体的位置,高度场
标记动态物体的位置,高度场  定义它们的高度范围。这种表示方式确保了动态物体能在 3D 体素空间中准确渲染,并与静态场景保持一致。
定义它们的高度范围。这种表示方式确保了动态物体能在 3D 体素空间中准确渲染,并与静态场景保持一致。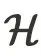 ,将场景特征
,将场景特征 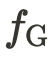
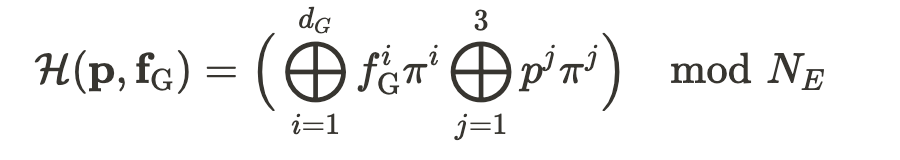
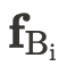 和空间坐标 p 映射到一个高维空间,以增强建筑立面的结构一致性:
和空间坐标 p 映射到一个高维空间,以增强建筑立面的结构一致性:
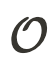 被定义为
被定义为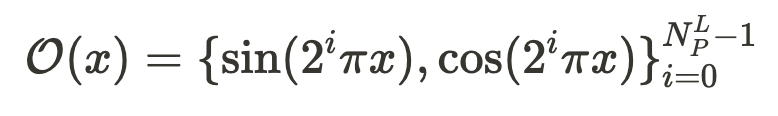
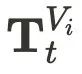 进行实例建模。该窗口包含 语义图
进行实例建模。该窗口包含 语义图 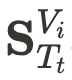 和 高度场
和 高度场 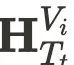 ,用于描述车辆的位置与三维形态,同时移除其他动态物体,以确保生成过程专注于单个实例。
,用于描述车辆的位置与三维形态,同时移除其他动态物体,以确保生成过程专注于单个实例。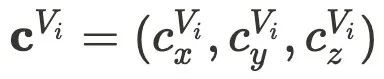 和 旋转矩阵R 共同定义,使得相同类型的车辆能够共享结构特征。对于给定的空间点 p ,其标准化表示为:
和 旋转矩阵R 共同定义,使得相同类型的车辆能够共享结构特征。对于给定的空间点 p ,其标准化表示为: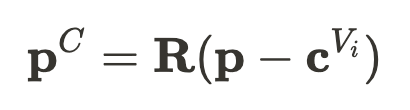
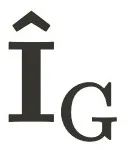 和
和  表示) 、建筑实例的图像和掩膜的集合( 分别用
表示) 、建筑实例的图像和掩膜的集合( 分别用  和
和 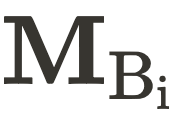 表示)以及车辆实例的图像和掩膜的集合(分别用
表示)以及车辆实例的图像和掩膜的集合(分别用 和
和 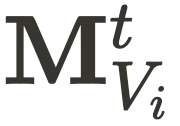 ,CityDreamer4D 使用如下方式得到第 t 时刻融合后的图像
,CityDreamer4D 使用如下方式得到第 t 时刻融合后的图像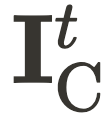 .
.
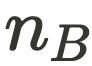 和
和 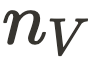 分别表示建筑和车辆实例的数量。
分别表示建筑和车辆实例的数量。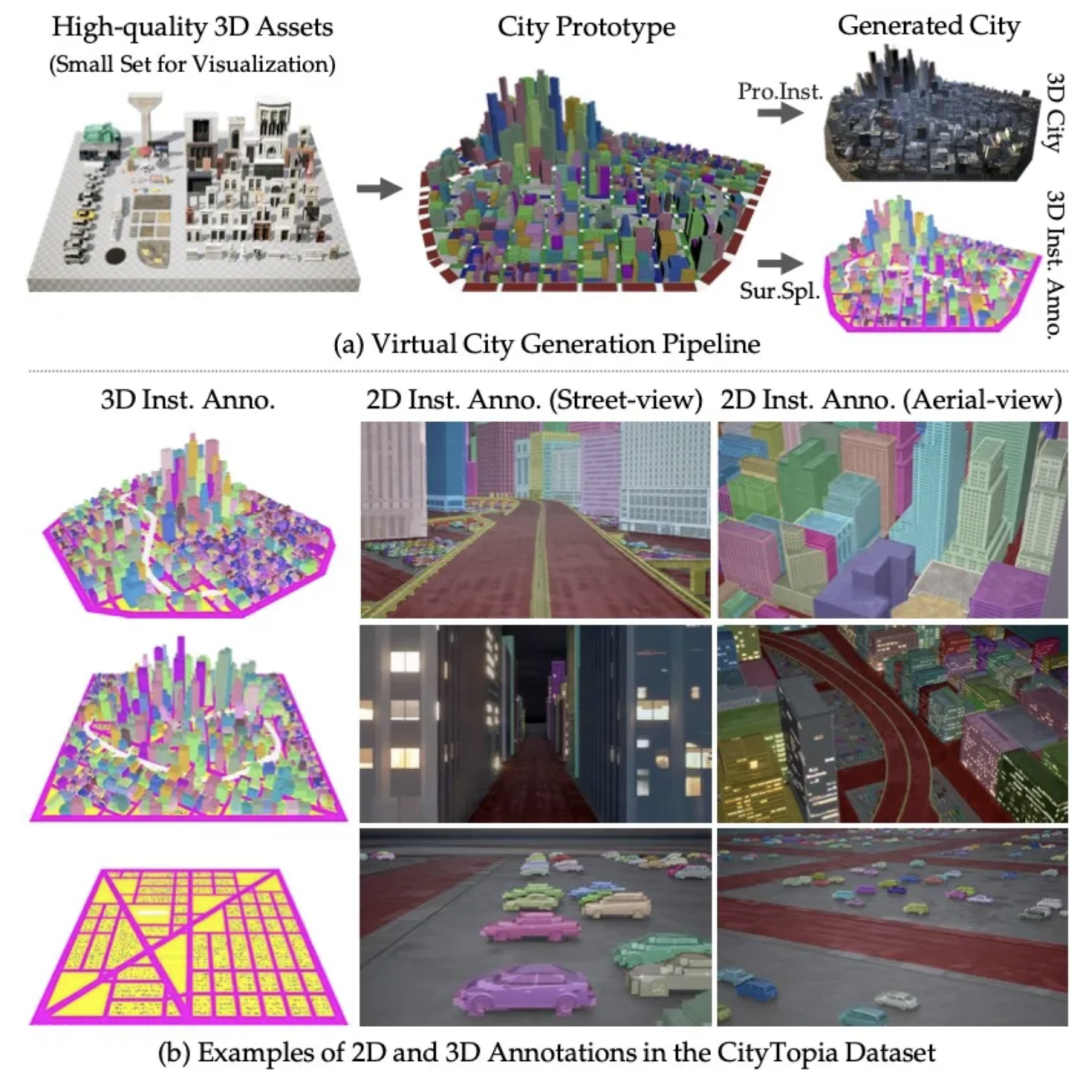
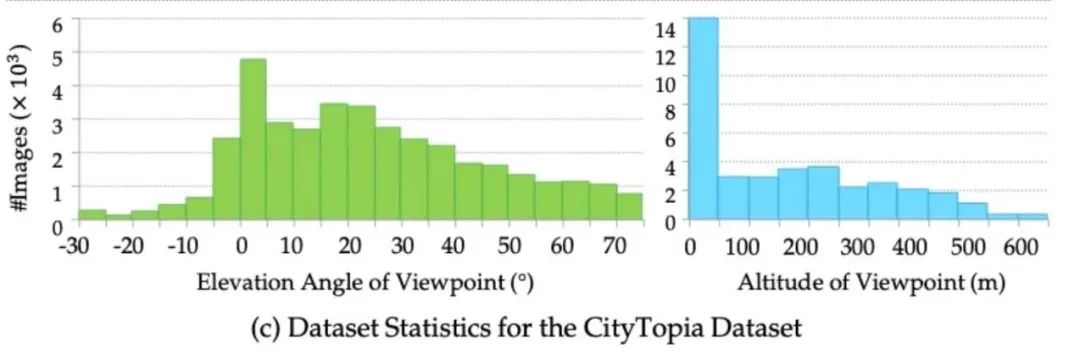

(文:机器之心)