

在数字化进程飞速推进的当下,图形用户界面(GUI)已成为人机交互的关键枢纽,其应用广泛渗透于各个领域。从日常的移动应用操作到专业的桌面软件使用,高效、精准的 GUI 交互至关重要。然而,将用户自然语言指令精准映射至界面元素始终是一大难题。传统依赖 HTML 或 AXTree 等辅助输入的方法,受困于效率低、信息缺失及兼容性差等弊端,严重阻碍自动化进程。在此背景下,香港大学与 Rhymes AI 联合推出的 Aria – UI 应运而生,宛如一颗划破夜空的流星,为 GUI 智能交互带来全新曙光,开启智能交互新篇章。
一、项目概述
Aria – UI 作为一款专为 GUI 智能交互精心打造的大型多模态模型,凭借其开创性的纯视觉理解方案,彻底颠覆传统。它无需后台数据支持,仅通过直接观察用户界面,即可流畅完成自然语言理解、元素定位、语义对齐及任务执行等全流程操作,极大简化部署流程,为跨平台自动化树立全新标杆。在 AndroidWorld 和 OSWorld 等权威基准测试中,Aria – UI 表现卓越,分别斩获第一名和第三名的佳绩,充分彰显其强大的跨平台自动化能力,有力证明其在 GUI 智能交互领域的领先地位。
二、技术原理深度剖析
1、创新架构奠定基础
Aria – UI 基于先进的 MoE(Mixture of Experts)架构构建,通过智能动态激活机制,将模型参数需求精妙压缩至仅 3.9B,在确保性能的同时,大幅降低计算资源消耗。这一突破性设计使模型在资源受限场景下仍能高效部署,如在移动设备或低配置计算机上也能稳定运行,为其广泛应用于各类实际场景奠定坚实基础。
2、多模态数据处理引擎
-
多源数据采集与融合:在数据处理方面,Aria – UI 展现出强大的整合能力。它能无缝融合来自网页、桌面和移动端的多源数据,全面覆盖不同平台的 GUI 特征。通过先进的图像识别与文本提取技术,精准捕捉界面元素的视觉与文本信息,为后续处理提供丰富素材,确保模型对各类 GUI 环境有全面深入的理解。
-
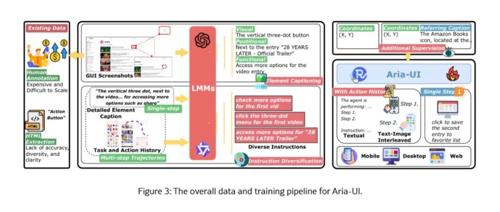
智能指令适配引擎:其核心的智能指令适配引擎通过自动合成海量高质量训练样本,赋予模型卓越的指令理解能力。该引擎先利用顶尖多模态语言模型(如 GPT – 4o 或 Qwen2 – VL – 72B)生成精确元素描述,输入包含元素截图、HTML 文本及屏幕位置坐标,并优化视觉输入(独立截图与放大视图)获取多维度特征。再基于此,借助 LLM 生成多样操作指令,每个元素生成 3 种不同表达,有效提升模型对复杂指令的泛化能力,使其能从容应对各种任务场景。
3、动态上下文感知机制
为应对动态任务执行挑战,Aria – UI 创新性地融合文本记录和图文操作历史,构建强大的多模态上下文理解机制。在处理多步骤任务时,模型能全方位综合分析先前操作记录与当前元素特征,精准生成操作指令。如在复杂软件操作流程中,可依据历史操作准确判断下一步操作目标,极大提高任务执行准确性与稳定性,确保在复杂多变的操作环境中稳定发挥。
4、高分辨率图像处理突破
随着显示技术迈向高分辨率时代,Aria – UI 积极应对挑战。通过智能分块策略,将图像处理能力从 980×980 大幅提升至 3920×2940,实现超高分辨率支持。同时,采用基于 NaViT 的优化方案,在处理过程中保持原始宽高比的智能填充技术,有效规避图像变形导致的精度损失,确保在高分辨率场景下精准定位界面元素,为高清 GUI 应用提供可靠技术保障。

三、核心功能全解析
1、精准GUI元素定位
Aria – UI 的核心功能之一是将自然语言指令精准映射至 GUI 中的目标元素,其定位精度极高。无论是在复杂的软件界面、网页布局还是移动应用中,都能迅速准确识别各类元素,如按钮、文本框、菜单选项等,为后续自动化操作筑牢根基,确保任务执行的准确性与可靠性。/2
2、多模态输入无缝协同
模型能够流畅处理 GUI 图像、文本指令、动作历史等多模态输入,实现各模态信息的深度融合与协同。例如,在处理图像编辑软件操作指令时,可结合界面图像、用户输入的文本指令及历史操作记录,准确理解用户意图,如“将选中图片裁剪为特定尺寸并添加滤镜效果”,精准执行相应操作,显著提升用户交互体验。
3、多样化指令灵活应对
凭借大规模多样化数据合成生成的丰富指令样本,Aria – UI 对不同表达方式、语义结构和应用场景的指令具有高度适应性。无论是简洁明了的指令,还是模糊、隐喻性的表达,都能准确洞察用户意图并做出恰当响应。如面对“让这个界面更美观些”的模糊指令,能根据不同应用场景智能推荐合适的操作,如调整颜色主题、优化排版布局等,充分满足用户多样化需求。
4、动态上下文智能适应
通过整合动态动作历史信息,Aria – UI 在多步任务场景中展现强大的动态上下文理解能力。在诸如多步骤软件安装、复杂游戏操作等场景中,能依据前序操作步骤和结果,结合当前指令,准确把握任务目标变化,实时调整元素定位策略和操作方式,确保任务流程的连贯性与高效性,有效提升复杂任务的完成质量。
四、性能评测结果
1、自动化操作能力评估表现
在AndroidWorld和OSWorld这两个权威的AI自动化操作能力基准测试中,Aria – UI与GPT – 4o协同合作,展现出了极为出色的性能。于AndroidWorld榜单上,Aria – UI脱颖而出,荣登榜首,其任务成功率高达44.8%(由Aria – UI_TH变体实现)。在该测试环境中,Aria – UI能够流畅地应对各类任务,如在不同应用间迅速切换、精准地进行数据输入操作等,充分彰显了其在Android系统下卓越的自动化操作能力。
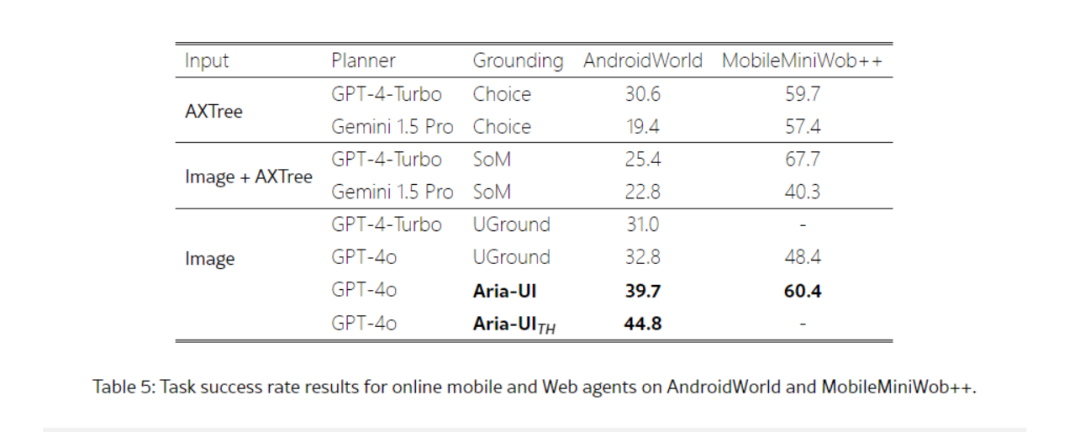
在OSWorld榜单中,Aria – UI同样表现优异,取得了第三名的佳绩,任务成功率达到15.15%(以GPT – 4o作为规划器,Aria – UI_TH为定位模型)。这一成绩使其成功超越了诸如Claude 3.5 Sonnet computer – use接口等传统方案。在面对系统级的文件管理任务,如创建、移动和删除文件,以及软件的安装、卸载与更新等复杂操作时,Aria – UI都能高效且准确地执行,有力地证明了其在桌面操作系统环境下模拟人类操作的强大实力。
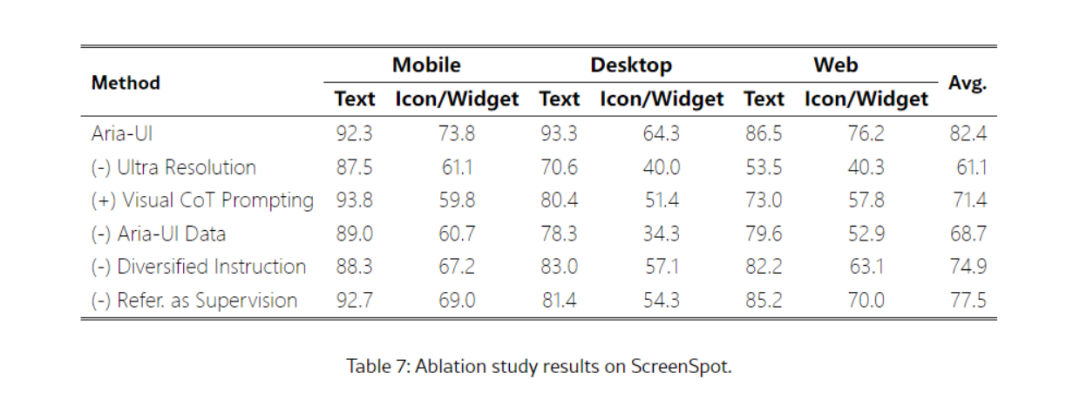
在ScreenSpot基准测试里,Aria – UI的定位准确率表现堪称惊艳。其平均准确率达到82.4%,在全部测试子集上均展现出了极高的准确性。尤其是在文本元素定位任务方面,Aria – UI优势显著。当面对学术论文编辑界面、法律文档阅读界面等包含复杂文本信息的场景时,它能够凭借先进的自然语言处理与图像识别融合技术,深入剖析文本语义,并与图像中的元素实现精准匹配。
五、广泛应用场景展示
1、自动化办公高效赋能
在办公领域,Aria – UI 可实现办公软件自动化操作。如在文档处理软件中,能根据用户语音或文本指令自动完成文档排版、内容编辑、格式转换等任务;在电子表格软件中,可快速执行数据输入、公式计算、图表生成等操作,大幅提高办公效率,减轻办公人员繁琐工作负担,使他们能将更多精力投入到创造性和决策性工作中。
2、智能移动应用交互
在移动应用场景下,Aria – UI 为用户带来更加智能便捷的交互体验。以地图导航应用为例,用户可通过自然语言指令“查找附近的餐厅并导航过去”,Aria – UI 能迅速解析指令,在地图应用中精准定位餐厅位置并规划最优导航路线;在社交应用中,用户可通过语音指令快速完成信息发送、好友查找、动态发布等操作,提升移动应用操作效率与便捷性,优化用户体验。
3、网页浏览智能辅助
在网页浏览方面,Aria – UI 可作为智能助手助力用户高效浏览网页。当用户在购物网站上搜索商品时,可通过指令“筛选价格在 500 元以内且好评率高于 90%的商品”,Aria – UI 能自动在网页上执行筛选操作,快速呈现符合要求的商品信息;在新闻资讯网站上,用户可通过指令“查找关于人工智能最新进展的文章并朗读出来”,Aria – UI 可定位相关文章并调用语音功能为用户朗读,方便用户获取信息,提升网页浏览效率与体验。
4、软件测试自动化革新
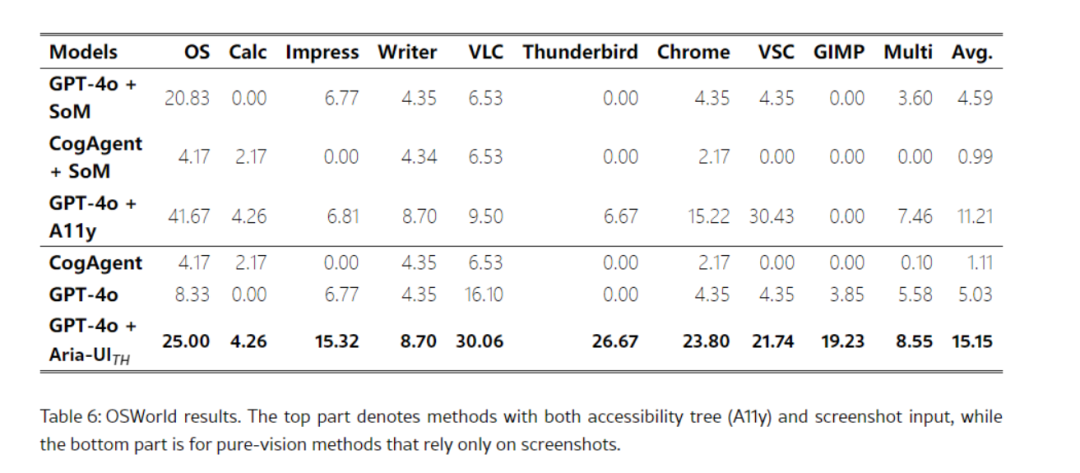
在软件测试领域,Aria – UI 发挥着关键作用。它可模拟用户操作,自动执行软件测试流程,如在软件功能测试中,能按照预设测试用例自动点击界面按钮、输入测试数据、检查输出结果,快速发现软件功能缺陷和界面交互问题;在兼容性测试中,可在不同操作系统和设备上自动运行软件,检测软件在各种环境下的运行情况,有效提高软件测试效率和覆盖率,保障软件质量。
六、快速上手教程
1、在线Demo体验指南
Aria – UI 为用户提供了便捷的在线体验方式,方便用户快速感受其强大功能。
用户可访问 Hugging Face 在线 demo:https://huggingface.co/spaces/Aria-UI/Aria-UI 。在该页面,用户能够直观地与 Aria – UI 进行交互。例如,用户上传一张 GUI 图像,并输入相应的操作指令,如 “点击界面中的登录按钮” 或 “查找并选中设置菜单中的语言选项” 等,Aria – UI 会迅速处理输入信息,在图像中定位目标元素,并返回该元素的相对坐标或执行相应的模拟操作,用户可在页面上实时查看结果展示。
2、环境搭建与安装指南
-
依赖库安装:在命令行执行以下安装命令,确保各依赖库正确安装。这些依赖库是 Aria – UI 运行的基础,需保证版本兼容性和安装完整性。
pip install transformers==4.45.0 accelerate==0.34.1 sentencepiece==0.2.0 torchvision requests torch Pillowpip install flash-attn --no-build-isolation为提升推理性能,可安装 grouped-gemm(安装可能耗时 3 - 5 分钟)pip install grouped_gemm==0.1.6
-
模型权重与数据准备:从官方指定渠道下载 Aria – UI 的模型权重文件和训练数据,并按照规定目录结构存放。确保数据完整性和准确性,避免因数据缺失或错误导致模型运行异常。
3、模型推理操作步骤
1)基于 vllm 的推理(推荐)
首先确保安装最新版 vLLM 以支持 Aria – UI:
pip install https://vllm-wheels.s3.us-west-2.amazonaws.com/nightly/vllm-1.0.0.dev-cp38-abi3-manylinux1_x86_64.whl以下是使用 vllm 进行推理的示例代码。在运行前,需确保图像路径正确,模型权重文件已正确加载,根据实际需求调整指令和参数设置,如更改图像文件名、修改定位精度要求等。
from PIL import Image, ImageDrawfrom transformers import AutoTokenizerfrom vllm import LLM, SamplingParamsimport astmodel_path = "Aria-UI/Aria-UI-base"def main():llm = LLM(model=model_path,tokenizer_mode="slow",dtype="bfloat16",trust_remote_code=True,)tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)instruction = "Try Aria."messages = [{"role": "user","content": [{"type": "image"},{"type": "text","text": "Given a GUI image, what are the relative (0-1000) pixel point coordinates for the element corresponding to the following instruction or description: " + instruction,}],}]message = tokenizer.apply_chat_template(messages, add_generation_prompt=True)outputs = llm.generate({"prompt_token_ids": message,"multi_modal_data": {"image": [Image.open("examples/aria.png"),],"max_image_size": 980, # [可选] 最大图像块大小,默认 980"split_image": True, # [可选] 是否分割图像,默认 True},},sampling_params=SamplingParams(max_tokens=50, top_k=1, stop=["<|im_end|>"]),)for o in outputs:generated_tokens = o.outputs[0].token_idsresponse = tokenizer.decode(generated_tokens, skip_special_tokens=True)print(response)coords = ast.literal_eval(response.replace("<|im_end|>", "").replace("```", "").replace(" ", "").strip())return coordsif __name__ == "__main__":main()
2)基于 Transformers 的推理(可选)
也可使用原始 Transformers API 进行推理,但性能可能相对较低。示例代码如下,同样需注意环境配置、图像路径和模型加载等问题,根据硬件资源和实际需求合理调整代码中的参数,如设备选择、生成令牌数量等。
import argparseimport torchimport osimport jsonfrom tqdm import tqdmimport timefrom PIL import Image, ImageDrawfrom transformers import AutoModelForCausalLM, AutoProcessorimport astos.environ["CUDA_VISIBLE_DEVICES"] = "0"model_path = "Aria-UI/Aria-UI-base"model = AutoModelForCausalLM.from_pretrained(model_path,device_map="auto",torch_dtype=torch.bfloat16,trust_remoteCode=True,)processor = AutoProcessor.from_pretrained(model_path, trust_remoteCode=True)image_file = "./examples/aria.png"instruction = "Try Aria."image = Image.open(image_file).convert("RGB")messages = [{"role": "user","content": [{"text": None, "type": "image"},{"text": instruction, "type": "text"},],}]text = processor.apply_chat_template(messages, add_generation_prompt=True)inputs = processor(text=text, images=image, return_tensors="pt")inputs["pixel_values"] = inputs["pixel_values"].to(model.dtype)inputs = {k: v.to(model.device) for k, v in inputs.items()}with torch.inference_mode(), torch.amp.autocast("cuda", dtype=torch.bfloat16):output = model.generate(**inputs,max_new_tokens=50,stop_strings=["<|im_end|>"],tokenizer=processor.tokenizer,# do_sample=True,# temperature=0.9,)output_ids = output[0][inputs["input_ids"].shape[1] :]response = processor.decode(output_ids, skip_special_tokens=True)print(response)coords = ast.literal_eval(response.replace("<|im_end|>", "").replace("```", "").replace(" ", "").strip())
七、结语
Aria – UI 作为香港大学与 Rhymes AI 在 GUI 智能交互领域的杰出创新成果,以其先进技术、强大功能和广泛应用前景,为智能交互技术发展注入磅礴动力。尽管目前可能存在一些技术挑战与应用优化空间,但随着研究深入与技术迭代,有望在更多领域大放异彩,重塑人机交互体验,推动智能应用迈向新高度。期待广大开发者积极探索应用,共同助力 Aria – UI 生态繁荣发展,开启智能交互新时代。
八、项目地址汇总
-
项目官网:https://ariaui.github.io/
-
GitHub 仓库:https://github.com/AriaUI/Aria – UI
-
HuggingFace 模型库:https://huggingface.co/Aria – UI
-
arXiv 技术论文:https://arxiv.org/pdf/2412.16256
(文:小兵的AI视界)