


文章转载自「新智元」,略有调整。
01
简单出奇迹,
首创long2short思维链

1. 长上下文扩展
2. 改进的策略优化
3. 简化框架
02
短CoT模型的上下文压缩
模型合并
最短筛选采样
DPO
long2short强化学习
03
强化学习基础设施

长CoT强化学习的部分回滚技术
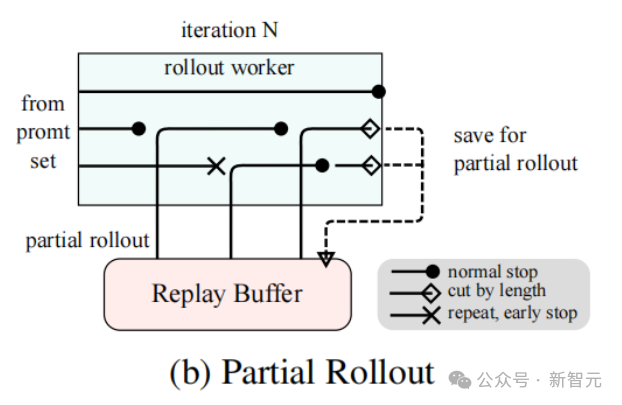
训练与推理的混合部署
-
促进了资源的高效共享与管理,避免了训练节点因等待推理节点而处于空闲状态(当两者部署在不同节点时) -
通过使用不同的部署镜像,训练和推理可以独立迭代,从而实现更好的性能 -
架构并不限于vLLM,还可以方便地集成其他框架

04
实验结果
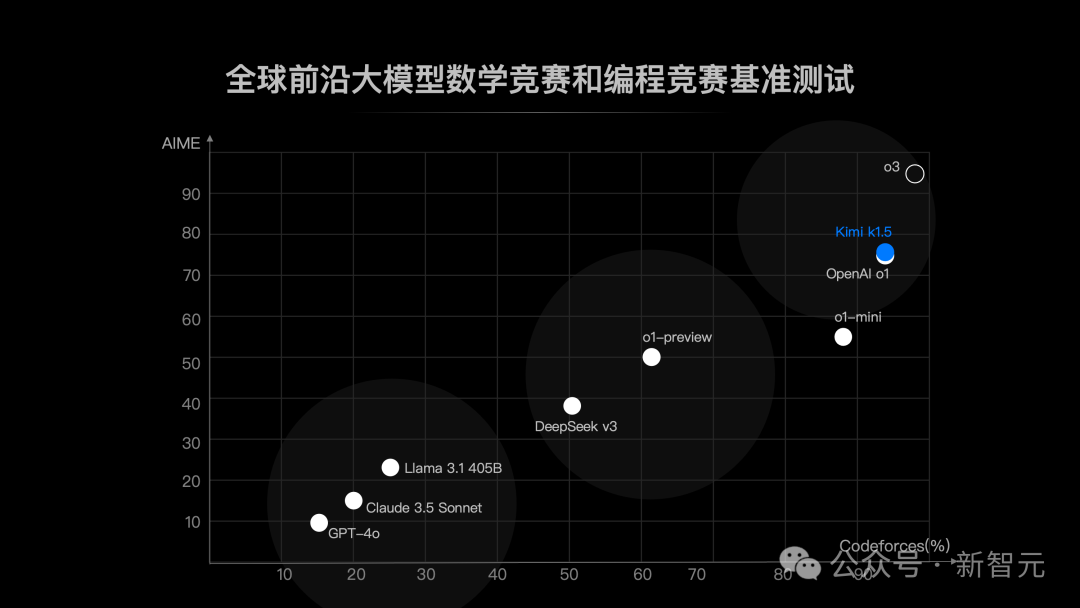
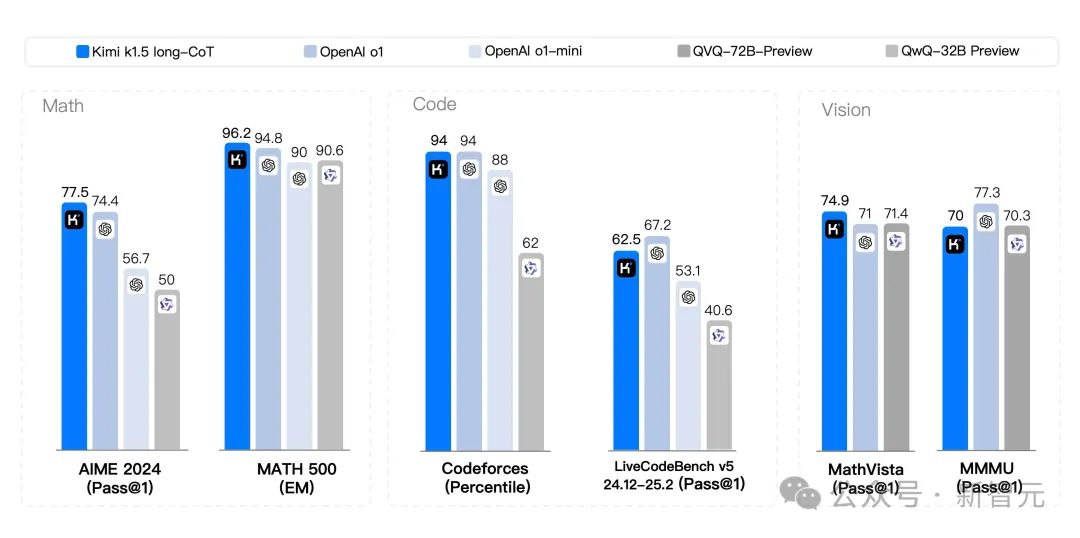
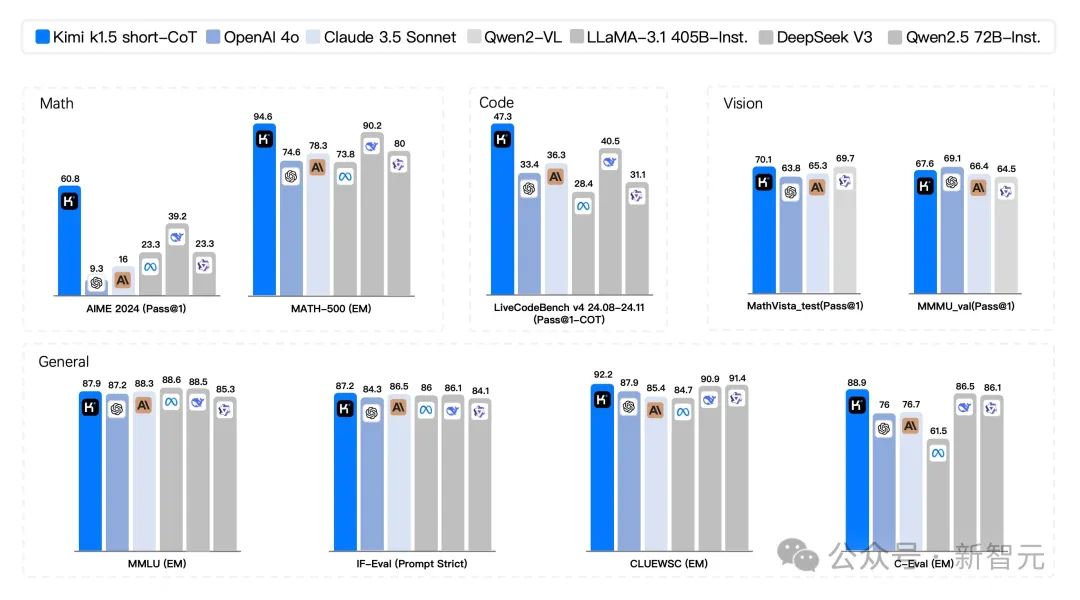
由于k1.5是一个多模态模型,研究者对不同模态的各种基准进行了综合评估。基准测试主要包括以下三类:
-
Text Benchmark:MMLU, IF-Eval, CLUEWSC, C-EVAL
-
Reasoning Benchmark:HumanEval-Mul, LiveCodeBench, Codeforces, AIME 2024, MATH500
-
Vision Benchmark:MMMU, MATH-Vision, MathVista
k1.5长CoT模型
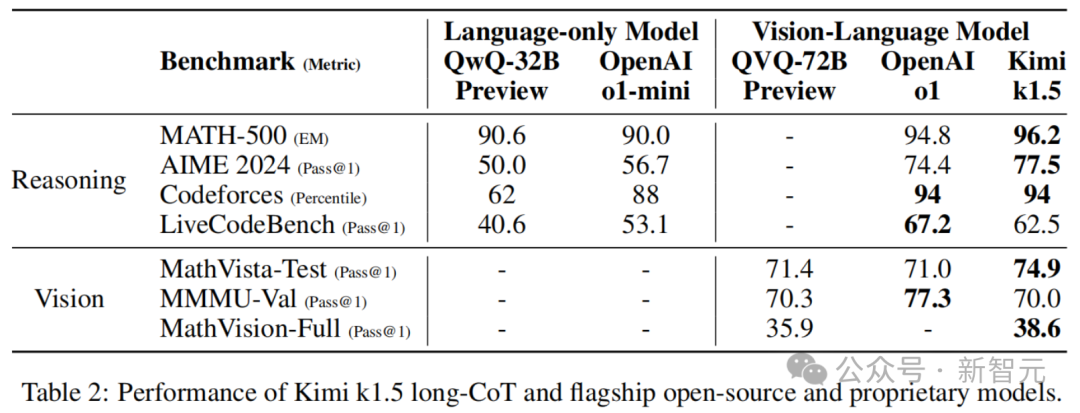
k1.5短CoT模型
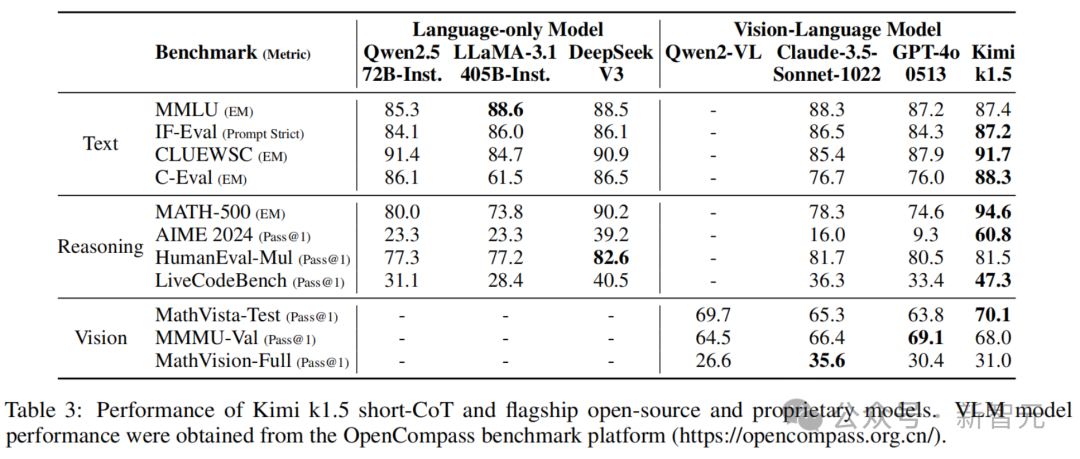
长上下文Scaling
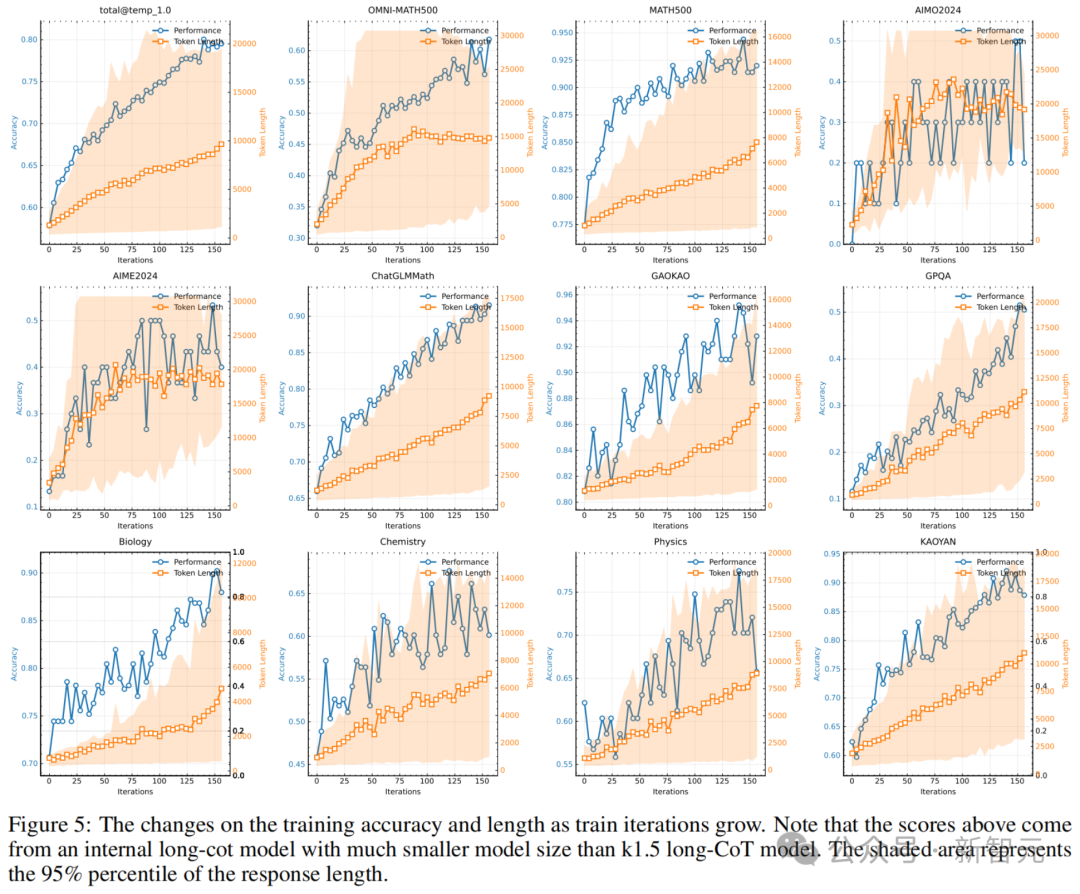
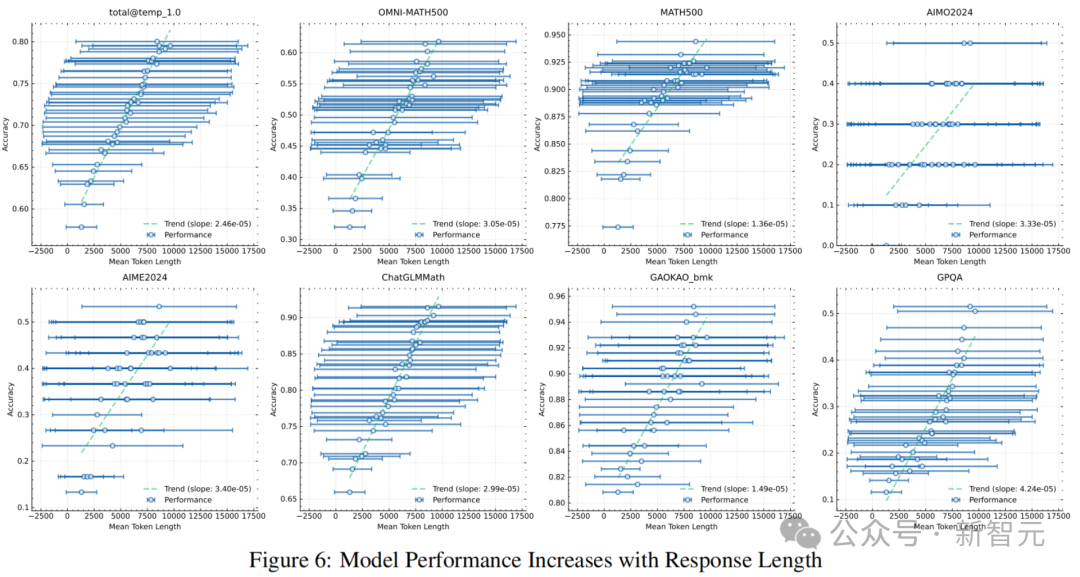
由长到短
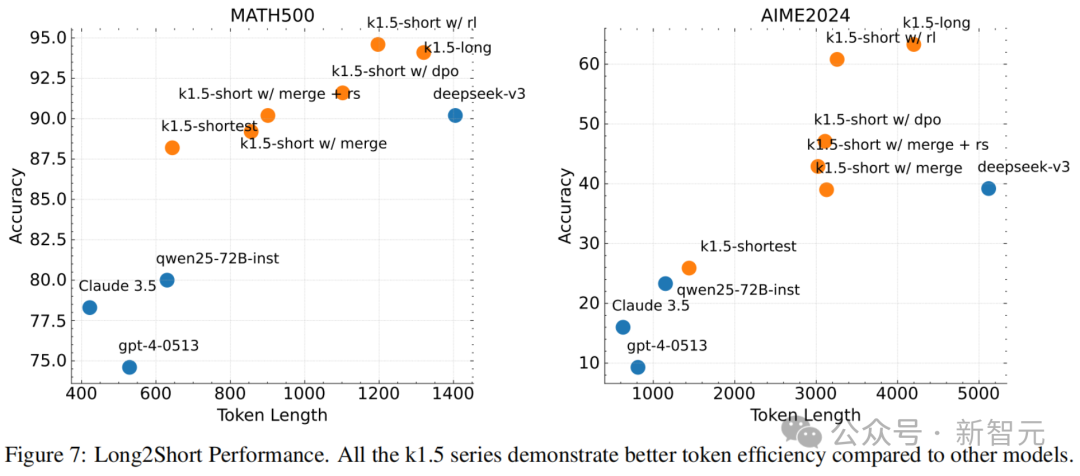
05
思考模型,
进入冲刺
(文:Founder Park)