


随着AI绘画进入Flux时代,广大小显存用户都遇到了同一个痛点:慢。
尽快众多开发者通过各种优化和量化,把Flux的使用门槛降到了8G甚至更低显存,但很显然速度是非常缓慢的。
SDXL、SD1.5时代的几秒出图变成了奢望。
最近有开发者放出一个插件,叫TeaCache,可以让Flux提速1.7倍,同时也有提速混元视频模型的效果。
TeaCache是一种免训练的缓存方法,可估计和利用跨时间步的模型输出之间的波动差异,从而加速推理。TeaCache 适用于图像扩散模型、视频扩散模型和音频扩散模型。
TeaCache现已集成到ComfyUI中,并与ComfyUI原生节点兼容。ComfyUI-TeaCache 易于使用,只需将 TeaCache 节点与 ComfyUI 原生节点连接即可无缝使用。
要使用编译模型节点,只需将Compile Model节点添加到工作流程中的 TeaCache 节点之后即可。编译模型用于torch.compile通过将模型编译为更有效的中间表示(IR)来增强模型性能。此编译过程利用后端编译器生成优化的代码,这可以显着加快推理速度。
第一次运行工作流时,编译可能需要很长时间,但是一旦编译完成,推理速度就会非常快。
也就是说,这个插件在批量跑图的时候非常好用,第一次速度慢一点,之后就是风一样的速度!

整体来说,和普通的Flux工作流唯一的区别就是增加了TeaCache节点,按插在绘画模型和模型采样Flux节点之间。

做一下速度对比。
配置:3060 12G。
模型:麦橘超然。
30步,768*1024
使用TeaCache,41.92秒:
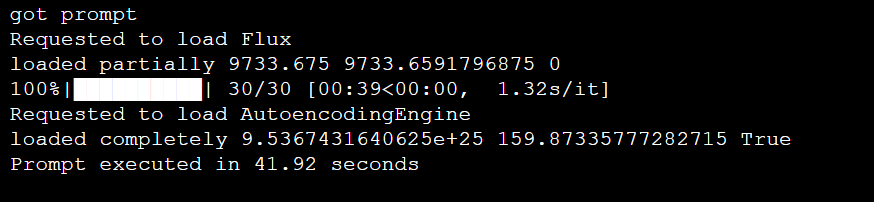
跑图:

不使用TeaCache,耗时97.89秒。

跑图效果:

在画质基本不变的情况下,实际速度提高了一倍多。
插件地址:
https://github.com/welltop-cn/ComfyUI-TeaCache
工作流:
https://pan.quark.cn/s/746b9eda890e
(文:路过银河AI)