

克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
只需一句话,就能生成可实时交互的3D世界。
刚刚,谷歌DeepMind发布了新一代通用世界模型Genie 3。
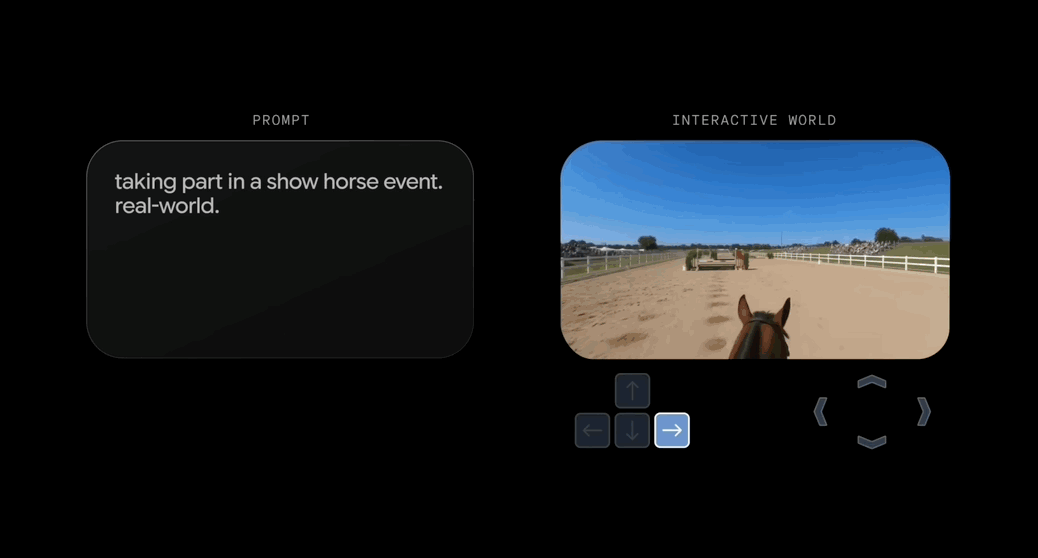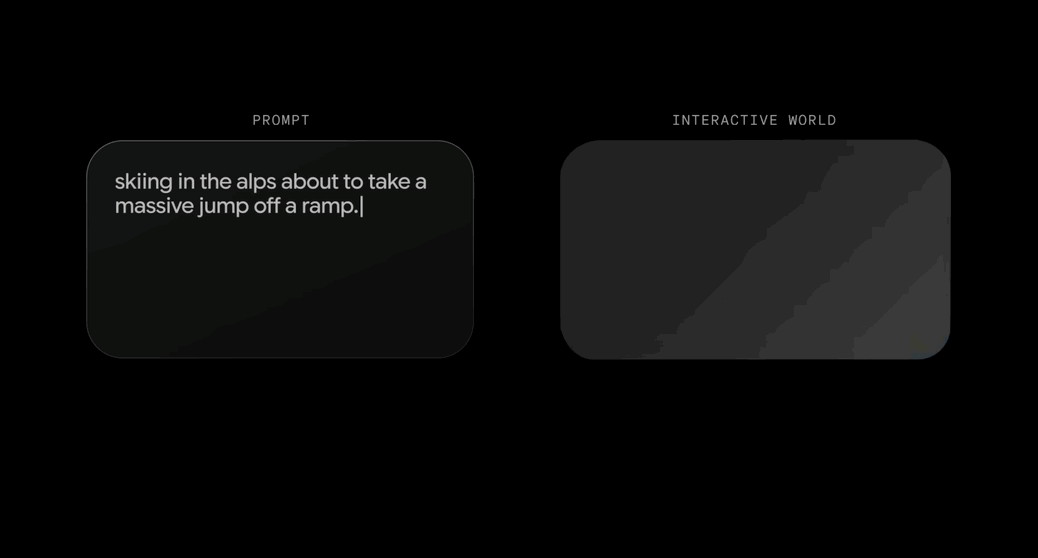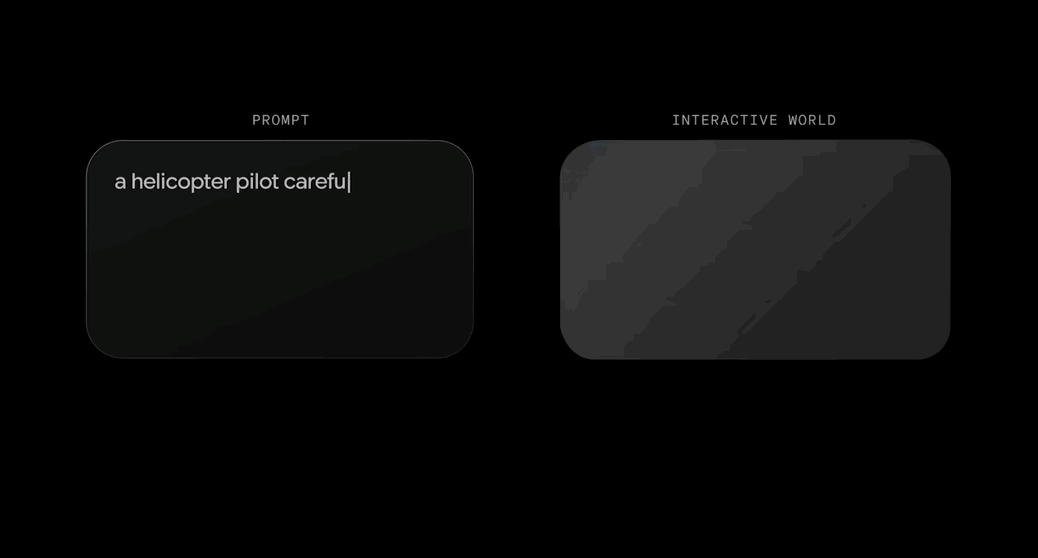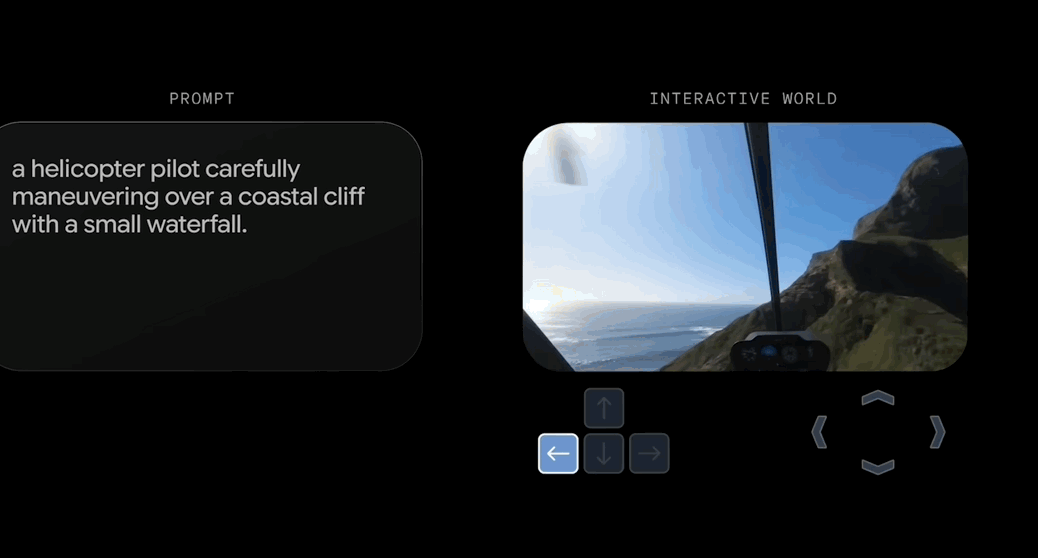
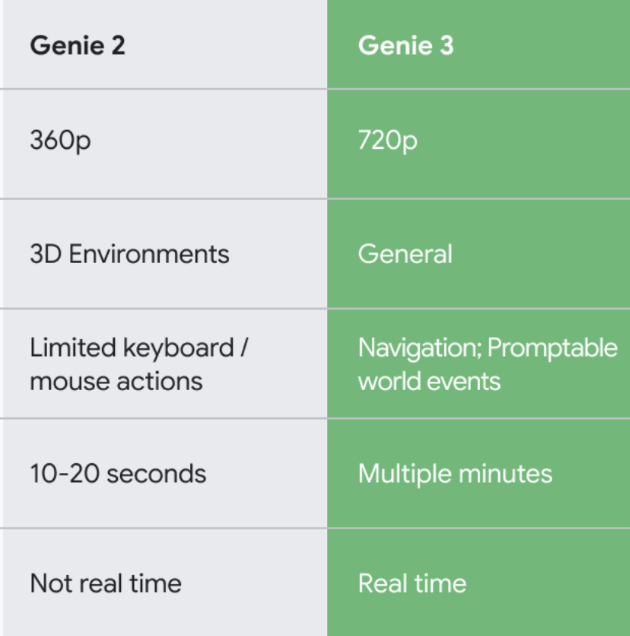
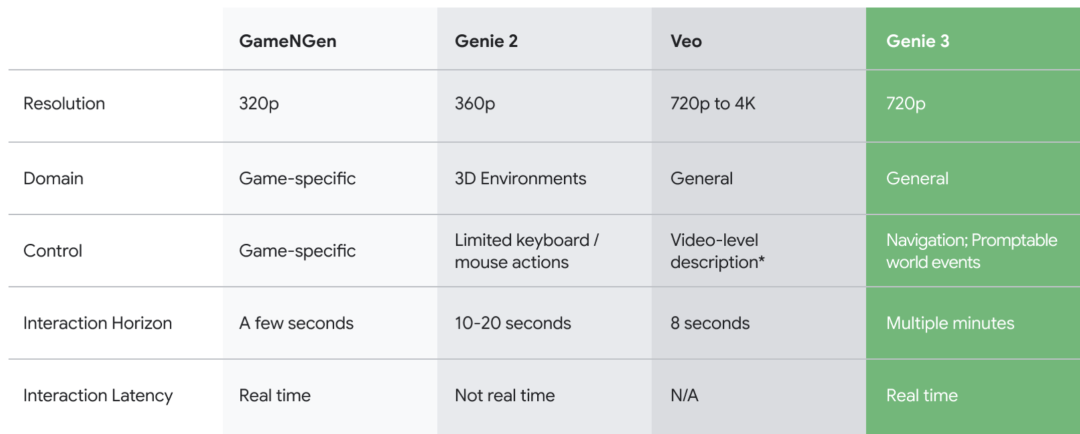
性能上,Genie 3相比上一代大幅升级,支持720P画质,每秒24帧实时导航,以及分钟级的一致性保持。
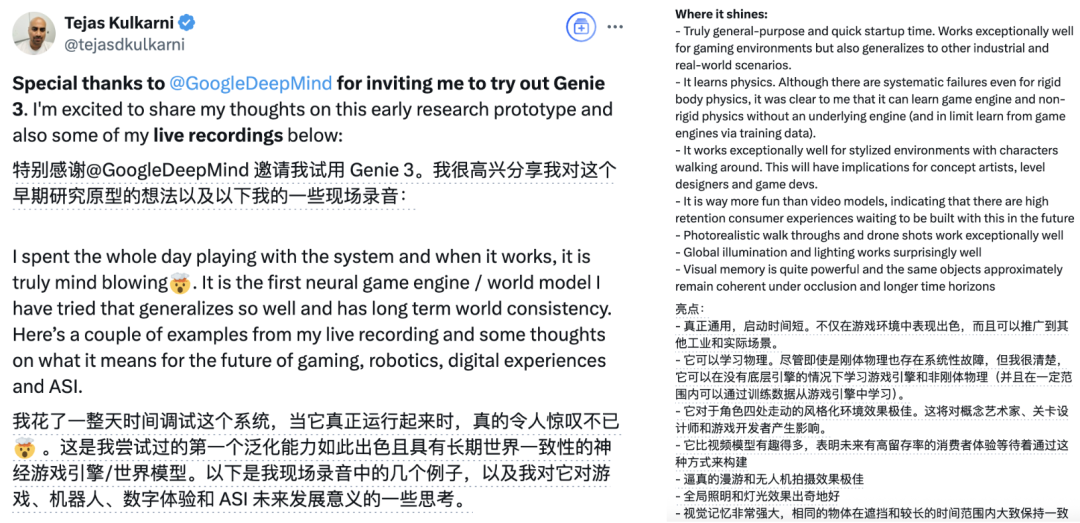
前DeepMind科学家、AI 3D生成创业者Tejas Kulkarni受邀体验了Genie 3。
他使用Genie 3,生成了长达57秒的城市高空漫游场景(下图为节选):

Tejas评价,Genie通用性强,还能学习物理,而且拥有强大的记忆力。
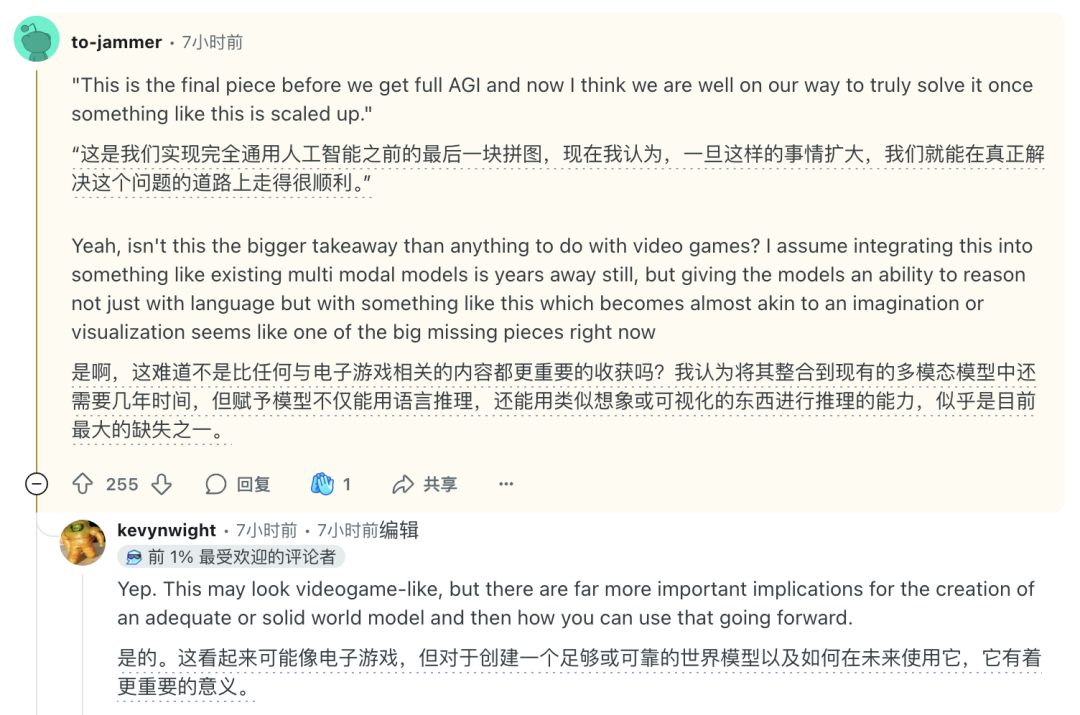
看了Tejas的测试,Reddit网友直言,这是通往AGI的最后一块拼图。
目前,Genie 3已经以研究预览的形式发布,邀请专业研究者和创作者进行测试。
长时间多角度物体依然一致
相比前一代Genie 2,Genie 3在画质、交互方式和时长,以及实时性方面均大幅提升。
Genie 3的生成结果具备3D空间一致性,并且由于是根据世界描述和用户操作逐帧创建的,Genie 3生成的世界更加丰富且更具动态。
而且Genie 3能够模拟世界的物理特性,处理水面等自然现象和复杂的环境相互作用。

也可以模拟自然世界,创造充满活力的生态系统。

当然也不局限于现实场景,Genie 3也可以发挥想象力,构建动画等虚拟场景。
比如让毛茸茸的小精灵在童话世界中玩耍奔跑。

或者跟着萤火虫的轨迹,探秘一片带有魔法色彩的原始森林。

还能超越地理和时间的界限,探索更多地方和更古老的时代,乘船漫游威尼斯的水上世界。

当然最让谷歌引以为傲的,还要属Genie 3的长期环境一致性。
为了使AI生成的世界具有沉浸感,画面中的物体必须在很长一段时间内保持物理一致性。
但自回归生成环境通常比生成完整视频更难,因为误差往往会随着时间的推移而累积。
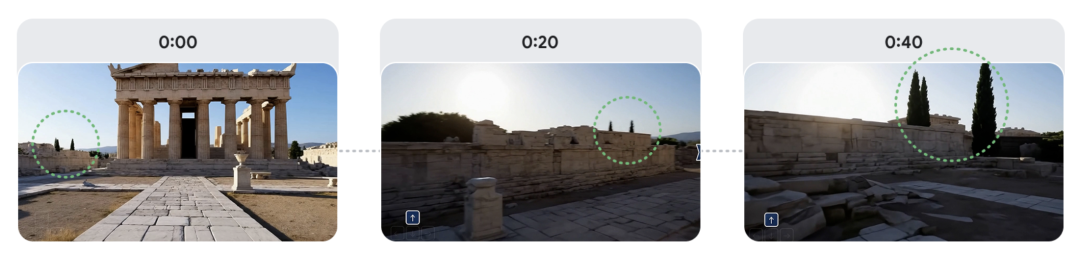
不过Genie 3的环境在几分钟内仍能保持基本一致,视觉记忆甚至可以追溯到一分钟前,谷歌专门展示了相关结果。
比如这是一组在雅典风格建筑中漫步的场景,先来看下完整视频:
谷歌特别展示了视频开始以及第20、50秒的截图,画面中建筑物左侧的树木反复进入和退出视野后始终保持一致。
还有这个刷油漆的场景,视角虽然不断变换,但每一步的涂刷操作和结果都被Genie 3准确记住。
此外,Genie 3还支持基于文本提示在世界当中生成事件。
比如给定一个草原的背景,可以让拖拉机从中开过,还可以把拖拉机换成一只棕熊。

又如在伦敦的河畔,可以让快艇从水面驶过,也可以让穿着奇装异服的人在岸上奔跑,还能让一只恐龙从天而降。
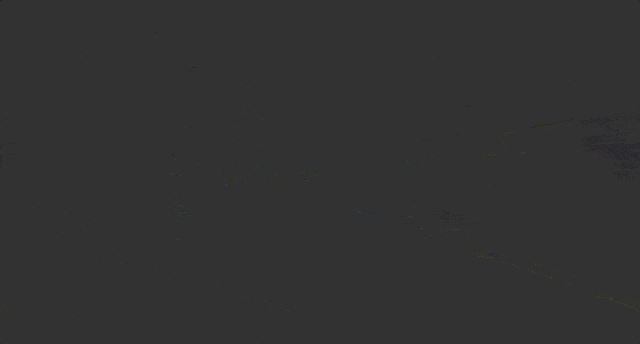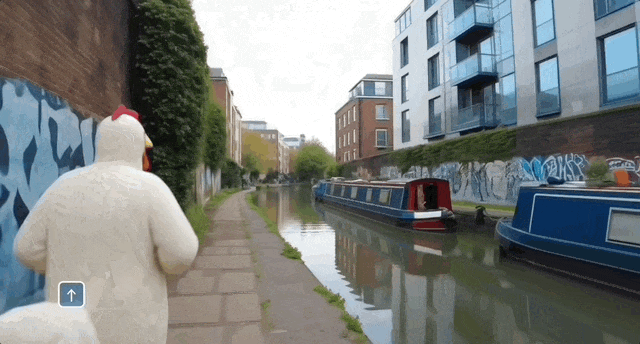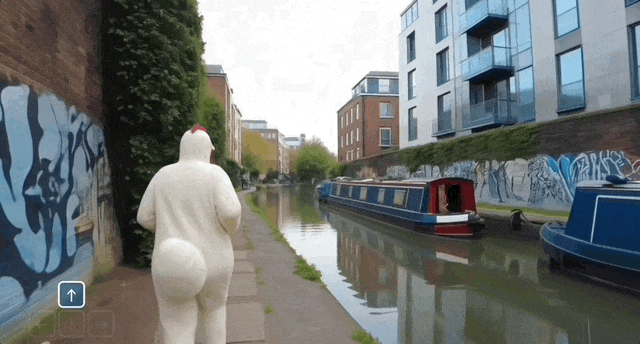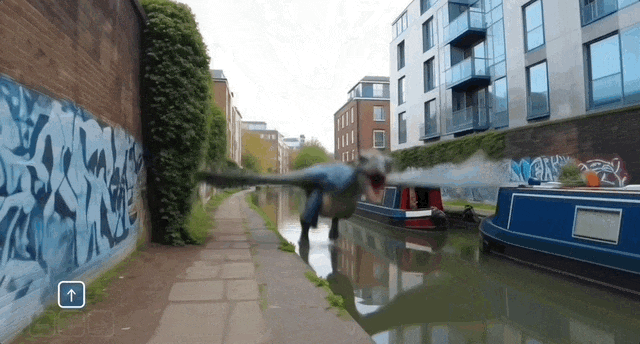
推动具身智能体研究
DeepMind介绍,Genie 3也将进一步推动具身智能体研究。
实际上,DeepMind十多年来一直在关注模拟环境领域的研究,从训练智能体掌握实时战略游戏, 到开发用于开放式学习和机器人技术的模拟环境。
去年,DeepMind推出了Genie 1和Genie 2这两个基础世界模型,它们同样可以为智能体生成新的环境。
这次的Genie 3,则是DeepMind第一个允许实时交互的世界模型。
为了测试Genie 3创建的世界与未来智能体训练的兼容性,DeepMind为SIMA智能体(用于3D虚拟场景的通用智能体)的最新版本生成了世界。
Genie 3并不知道智能体的目标,而是根据其操作来模拟未来事件。
比如在面包店中,走向搅拌机、冷却架或者玻璃柜。

或者在农贸市场中走向面包摊、花摊和蔬菜摊位。

总之,Genie 3相比过去可以执行更长的操作序列,从而实现更复杂的目标。
谷歌期待这项技术在人类迈向AGI的过程中发挥关键作用,并使智能体进一步走进现实世界。
(文:量子位)