


新智元报道
新智元报道
【新智元导读】AI界的「赤壁之战」!OpenAI开源惨遭谷歌、Anthropic新模型狙击。最绝的是,Anthropic卡点发布Claude Opus 4.1,代码甩OpenAI新模型几条街。
昨日,OpenAI、谷歌和Anthropic等发布了不同的新模型:
谷歌推出「G」字号第三代世界模型Genie 3,号称「宇宙模拟器」,视频生成更加符合物理定律。
Anthropic正式推出Claude Opus 4.1,在智能体任务、现实世界编程和逻辑推理三大核心领域全面升级了Claude Opus 4。
OpenAI再次Open,兑现了开源承诺,放出了OpenAI-OSS系列模型,手机、电脑本地可跑。

Anthropic称Claude Opus 4.1提升了编码性能,同时在深度研究和数据分析能力上实现突破,特别强化了细节追踪和智能体搜索功能。
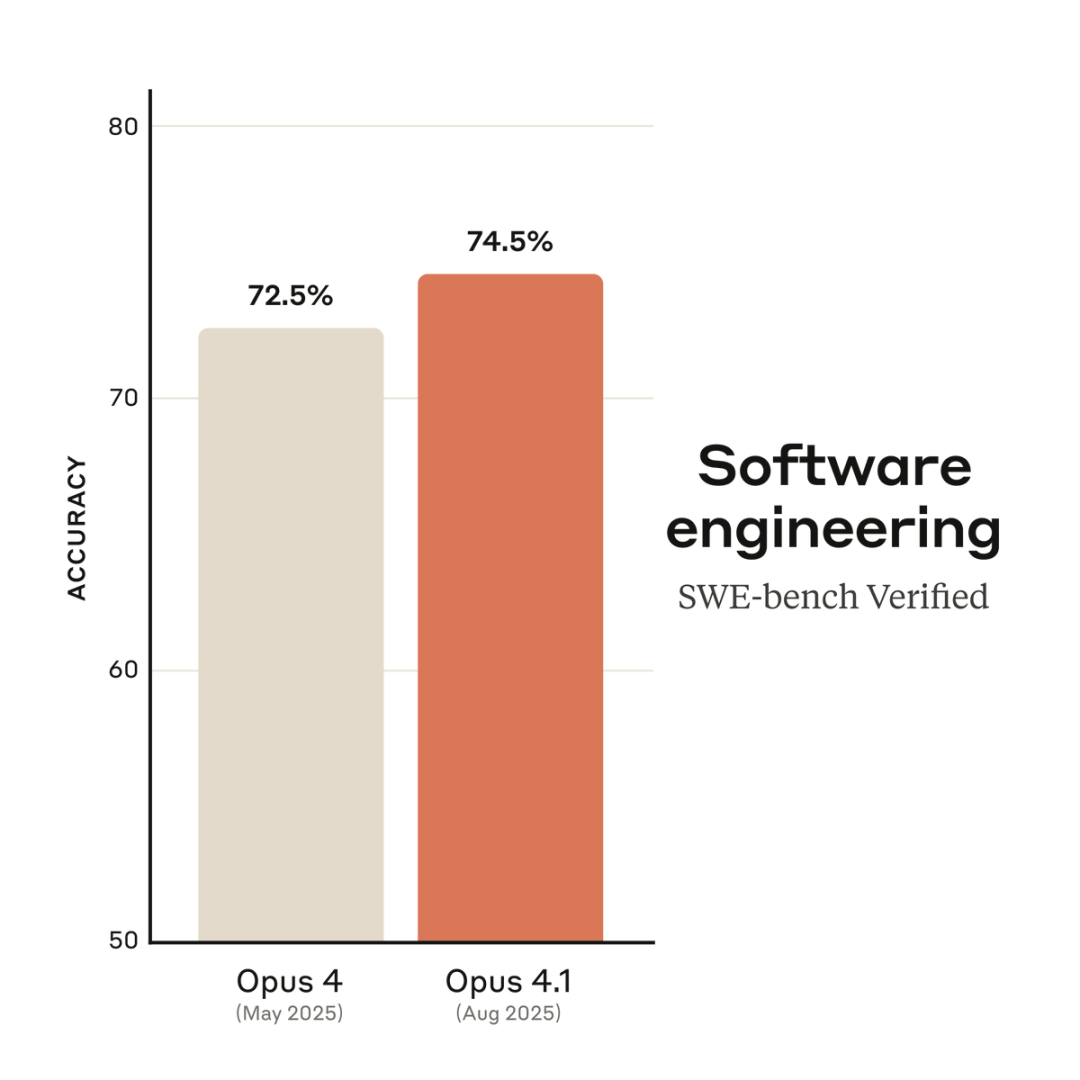
实话是,在编程基准SWE-bench Verified上,从Opus 4.0的72.5%提升到了Opus 4.1的74.5%准确率。
的确,编码性能提升了,但只有2%——老实说,Opus 4.1的性能提升并不大,毕竟定价都和Opus 4一样。
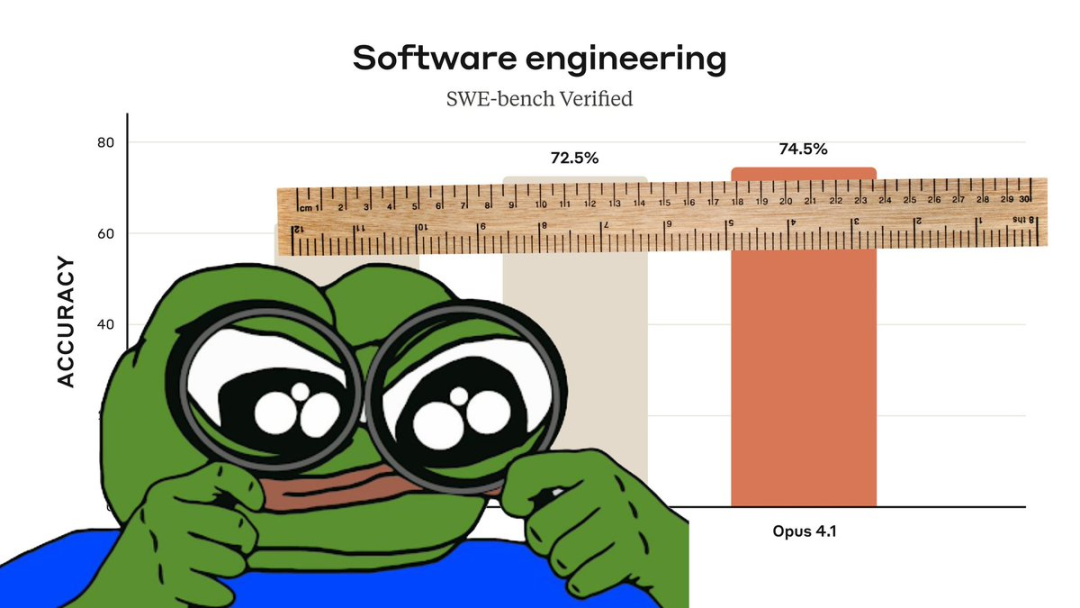
在其他基准测试上,部分性能提升甚至不足1%。👇
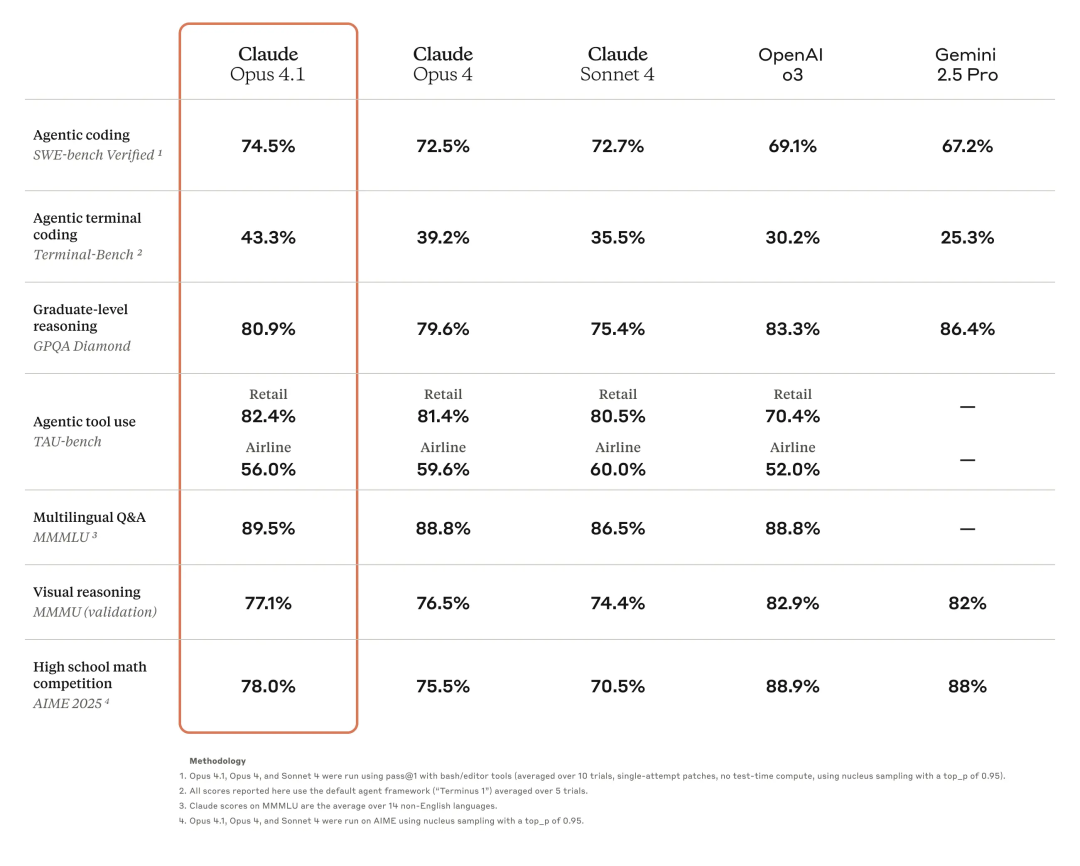
Claude Opus 4.1现已面向付费用户及Claude Code平台开放,同时登陆API服务、Amazon Bedrock和Google Cloud Vertex AI三大云平台,定价与Opus 4版本保持一致
至于,Anthropic为什么对如此小的改进还要发布?还在OpenAI官宣「再次开源」几分钟前?
我说就是巧了,Anthropic和OpenAI这是巧了,这是Anthropic在欢迎OpenAI「回归初心」,你信吗?
Palantir兼Cloudflare前员工、剑桥CS毕业生表示,2%性能提升对大部分人而言无足轻重,改天发布更有意义,这样就不会被OpenAI的新模型盖过风头。

总之,对用户来说,昨晚是AI界的圣诞节。

马斯克的Grok、OpenAI、谷歌轮番宣称「推出全球最强模型」,Anthropic说什么也要插一脚!
即便如此,论写代码Claude模型是真的强。
Anthropic拉上大客户表示:Claude Opus 4.1实现全方位能力跃升。
GitHub表示,Claude Opus 4.1相比Opus 4在多项功能上都有进步,尤其是在处理多文件代码重构时表现更为出色。
Rakuten Group发现,Opus 4.1能够在庞大的代码库中精准识别需要修改的部分,避免不必要的更动,也不会引入新的 Bug。他们的开发团队在日常调试中非常看重这种高精度的表现。
Windsurf也报告称,在他们用于评估初级开发者能力的基准测试中,Opus 4.1的表现比Opus 4提升了约一个标准差,这一提升幅度大致等同于从Sonnet 3.7升级到Sonnet 4时的进步。
KCORES 联合创始人「karminski-牙医」测试了OpenAI和Anthropic新模型写代码能力,结果OpenAI新模型写代码不太行。

「karminski-牙医」测试了4款模型:
OpenAI-OSS-120B
OpenAI-OSS-20B
Claude-Opus-4.1
Gemini-2.5-pro (Opus的主要对手)
这次快速测试结论如下:
Claude-Opus-4.1 > Gemini-2.5-pro > OpenAI-OSS-20B >? (存疑) OpenAI-OSS-120B
每个模型各运行至少6次, 取最好结果给大家展示。
从测试结果看Claude-Opus-4.1出乎意料的稳,对空间理解远超任何模型。
OSS-120B随机性非常大, 在这个测试里面OSS-120B甚至采样了8次, 还没有OSS-20B效果好.
可能原因是120B每次激活专家量很少,而总专家数量又多,导致每token随机到相同专家的概率会特别小,进而表现不是那么稳定。而20B则好一些,4/128 VS 4/32专家。
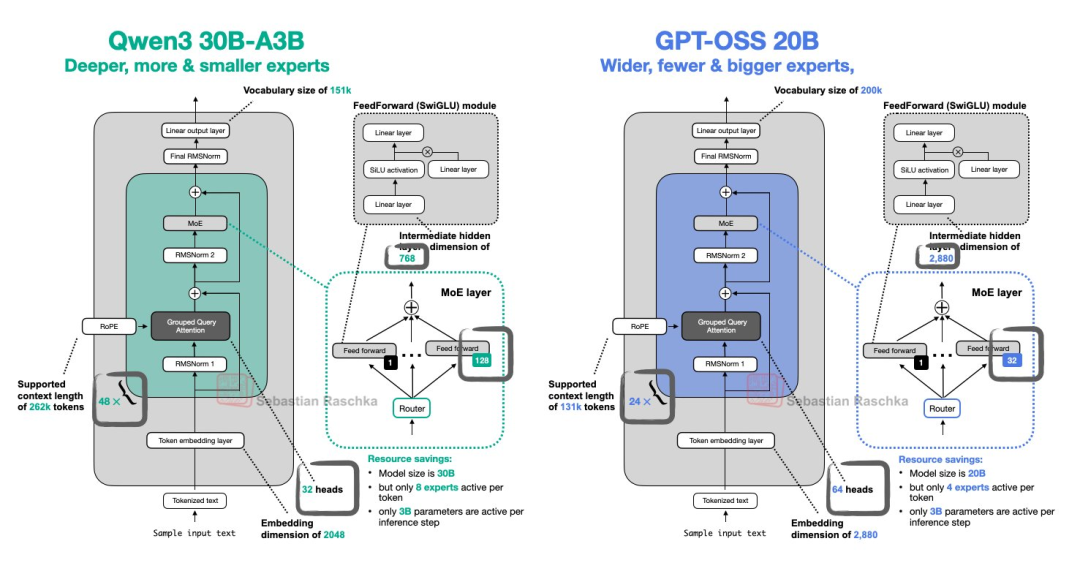
总之,OpenAI-OSS-120B用起来要谨慎,写代码特别不稳定。OpenAI-OSS-20B在这个参数量大小下反而挺好。
最后,他提醒大家AI写代码需谨慎:不要用不太行的模型写代码,只会浪费时间去调试并且积累屎山。
(文:新智元)