

今天是2025年8月5日,星期二,北京,晴
我们继续来看多模态RAG进展,看一个将RAPTOR引入多模态文档检索问答的的思路,MMRAG-DocQA,其跟GraphRAG的思路也很像。
一、MMRAG-DocQA多模态RAG思路
先来看多模态RAG进展,有个多模态长文档问答(Multi-modalLong-contextDoc-QA)任务,需要在包含文本、表格、图表、图片、版式等多模态信息的超长PDF中,跨页定位并融合证据,回答用户问题。
但是,从技术方案上看,基于多模态的方案的方法容易产生幻觉,基于RAG的方案则在跨模态连接和跨页碎片化方面还不太行,需要连起来。

1、先看两个问题
核心就是两个问题。
一个是文档内部多模态的关联以及跨页的依赖问题。多模态长文档问答需要整合多模态信息以合成准确答案,而非仅依赖文本或视觉线索。

例如,针对问题“5% 的拉丁裔如何看待子女经济向上流动?”,由于问题与这些文本内容共享关键词和语义,相对容易检索到若干文本证据,如纯文本和基于布局的图像描述。然而,实际答案“较差”却隐藏在视觉图像中,由于饼图缺乏直接的文本重叠和语义线索,导致其检索得分难以提高。
一个是多模态证据连接和长距离证据整合与推理的问题,其实是在解码阶段的范畴。多模态长文档问答中的另一大难题是分散在不同页面上的证据孤立性,这要求模型能够进行长距离跨页证据的推理与整合。
例如:针对问题“我是在墨西哥使用Macbook Air 的用户。根据本指南,我应该拨打哪个号码寻求 AppleCare 服务与支持?”,相关证据跨越了多种模态,包括纯文本和表格,并分布在不同的页面上。
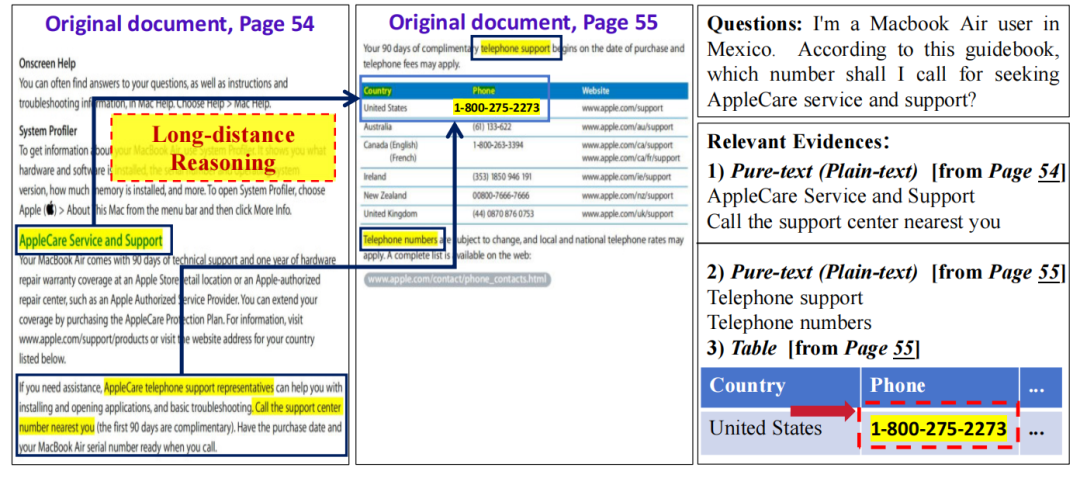
实际电话号码“1-800-275-2273”出现在第 55页的表格中,而说明性指示“拨打离您最近的支持中心号码”则位于第 54 页。这要求模型能够关联跨页证据,并在文档的多个部分间进行多步推理,而这一能力在现有大多数模型中尚不具备.
2、引入层级性多模态关联及细粒度检索的方案
因此,可以看一个思路《MMRAG-DocQA: A Multi-Modal Retrieval-Augmented Generation Method for Document Question-Answering with Hierarchical Index and Multi-Granularity》,https://arxiv.org/pdf/2508.00579,开源代码在:https://github.com/Gzy1112/MMRAG-DocQA,分别解决这两个问题。
对于问题1,思路就是先把PDF拆成页内chunk+跨页摘要树,也就是做层次化索引,结合页面内扁平化块和跨页面拓扑块。
这里的逻辑是:由于语义相关的文本和视觉元素往往在同一页面中共现,父页面包含了与答案相关的多模态检索内容,这有助于桥接不同模态。
对于问题2,思路就是多粒度语义检索,包括页面级父页面检索和文档级摘要检索, 然后让LLM带着CoT把图文证据拼成答案,这里的逻辑在于;结合拓扑跨页索引策略与文档级摘要检索的方法。通过聚类将不同页面上语义相关的内容分组,并由大模型进行摘要**,从而将检索范围扩展到跨越多页。
如下图所示:
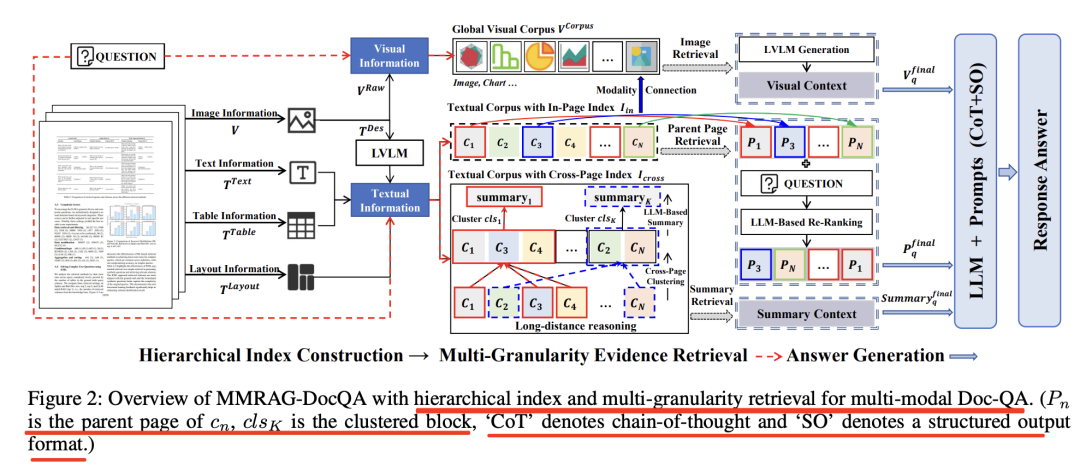
其中,Pn是cn的父页面,clsK为聚类块,‘CoT’ 表示思维链,‘SO’ 代表结构化输出格式。
1)两级层次索引Hierarchical Index Construction
第一级是扁平化页内索引,将每页的文本、表格、版式文字切成统一大小的chunk,并用语言模型编码,后面可以用于检索,也就是上面的cn,这里还涉及到文档解析,把其中的图片元素、表格元素等都做分离,使用的是Docling,用于解析PDF文件。
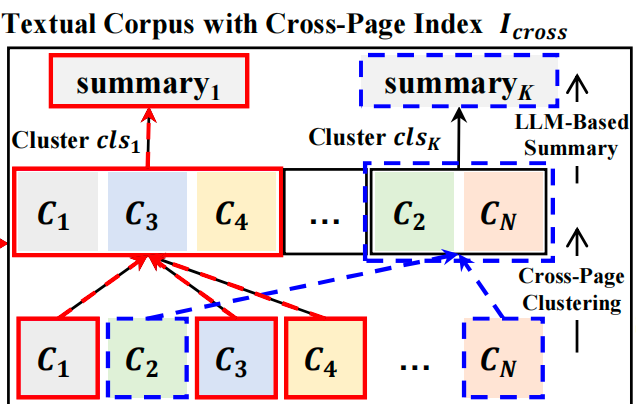
第二级是拓扑跨页索引,先把全文档的文本块做高斯混合聚类(cross-page cluster),再用大模型为每个聚类生成摘要,层层向上形成树形结构,根节点即整篇文档的语义总览,这个其实就有了跨页的效果(分散在不同页面的chunk,通过聚类弄到了一起。)
2)多粒度语义检索Multi-Granularity Evidence Retrieval
检索上,包括两路召回:
一个是页面级父页检索,先找出与问题最相关的文本chunk,再回溯到其所属的“父页”,从而一次性取回该页内所有图文信息,解决“文本与图表不在同一chunk导致失联”的问题,这个很像RAPTOR,做的是一个回溯的操作。

一个是文档级摘要检索,直接在跨页拓扑树上匹配问题语义,召回跨页摘要节点,解决“远距离证据整合”与多跳推理。
3)多模态混合生成
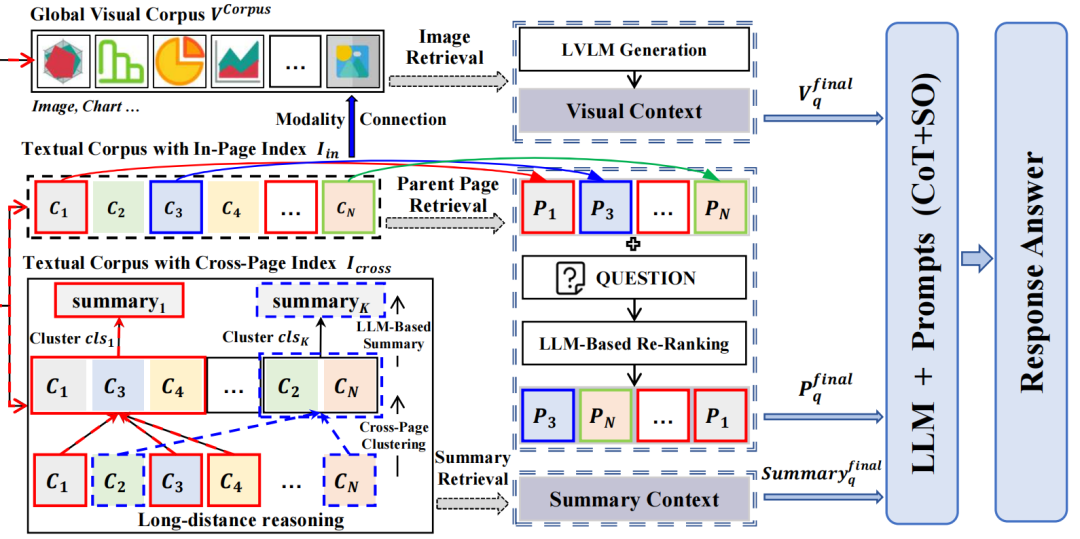
针对上面的这两路召回,分别拿到了父页和摘要,先对父页做一个rerank操作,用大模型按与问题的相关性打分并重排序,过滤噪声;
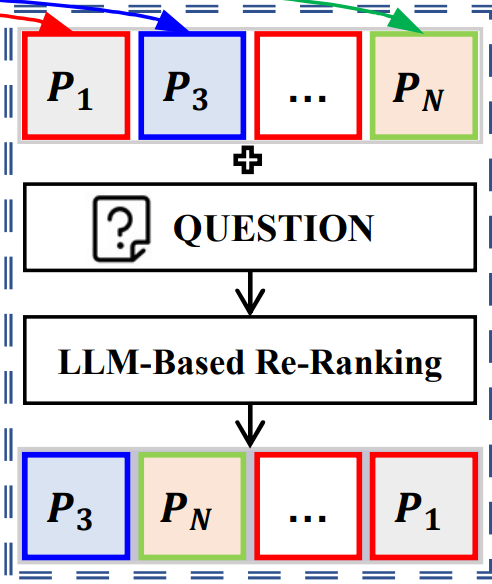
在最终答案生成时,使用图片视觉的信息visual Context+页面的信息PN+摘要的信息summary content,然后加入CoT提示,引导模型逐步整合多模态、跨页的证据,然后生成答案。
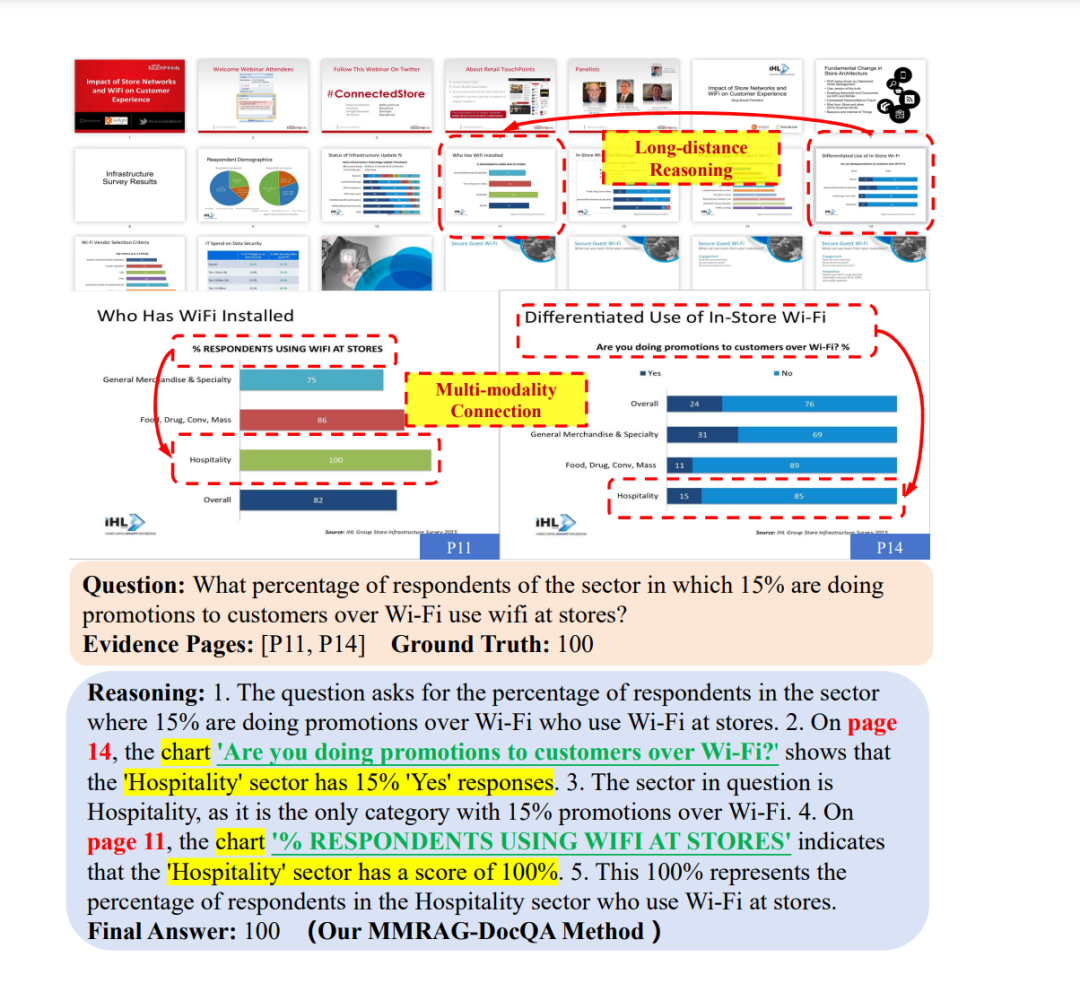
最后看下效果,在数据集上的一个具体体现:
在实际测试集上的效果对比:
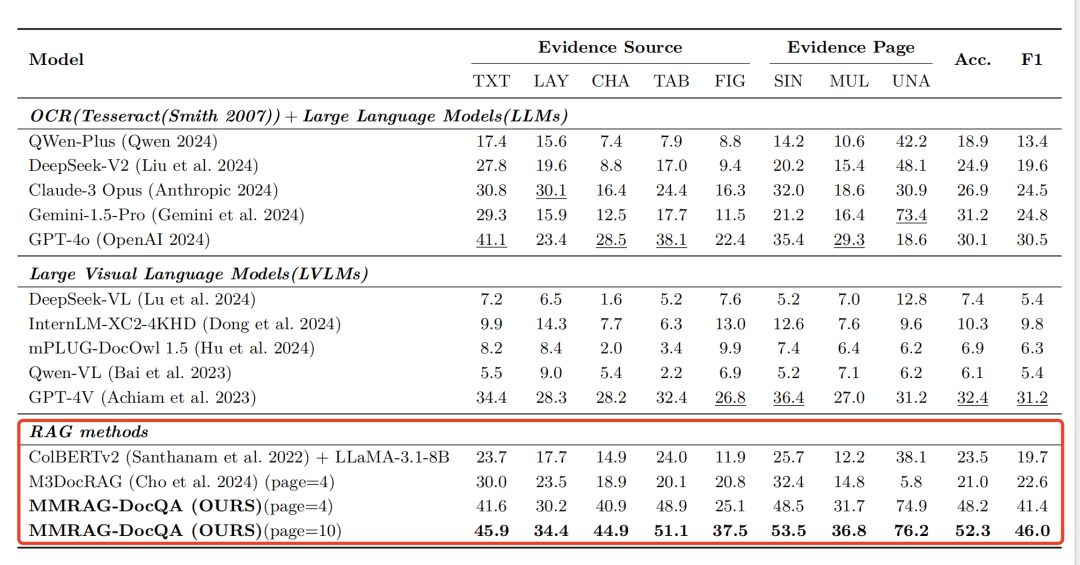
其中主流的方案,Colpali、DSE 和 VisRAG 直接对文档页面的图像进行编码以进行检索。MDocAgent则分别使用基于文本和基于图像的智能体来处理文本和视觉信息,从而在检索阶段获取各自模态内的关键信息并生成答案。
参考文献
1、https://github.com/Gzy1112/MMRAG-DocQA
(文:老刘说NLP)