


本文由特工自制 Agent 翻译,宇宙编辑部精校而成。
原文:https://menlovc.com/perspective/2025-mid-year-llm-market-update/
去年 11 月,Menlo Ventures 发布了《2024 企业生成式 AI 现状报告》。彼时,关于这一基础层仍有诸多关键问题悬而未决:
-
大语言模型的 API 需求是否能与消费级应用的增长节奏保持一致?
-
模型将变得多智能?进化速度又将如何?
-
开源模型是否会在性能上赶超闭源的前沿模型?如果会,这将如何影响企业的采用路径?
-
最关键的是,长期价值究竟会沉淀在哪里?
六个月过去,从数据维度来看,这些问题目前已经较为清晰:
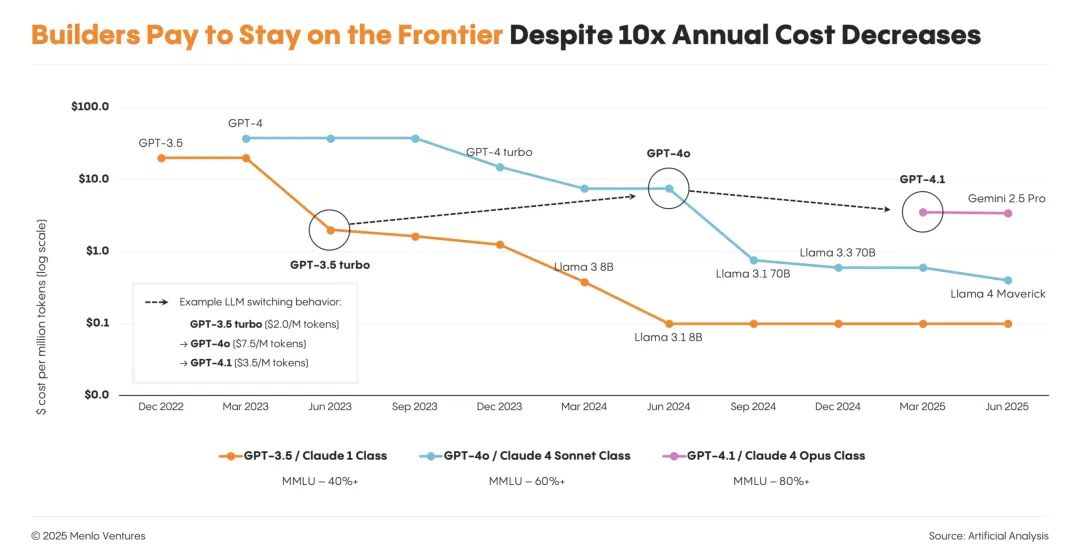
在这段时期内,模型 API 支出增长了一倍多,从 35 亿美元跃升至 84 亿美元。企业的重心已从模型的训练微调转向模型推理,这标志着一个重要的阶段性转折。
“代码生成”成为第一个大规模爆发的 AI 应用场景。在预训练之外,基础模型正在沿着另一条轴线升级能力——结合验证器的强化学习(RLHF with verifiers)。
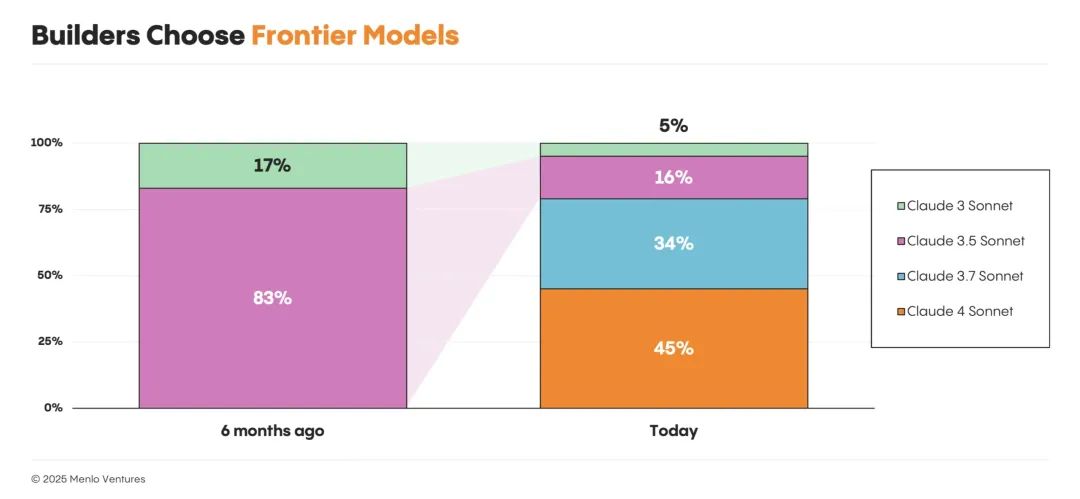
与此同时,尽管开源模型持续取得进展,但西方实验室在前沿模型突破上的放缓,也在一定程度上抑制了企业侧的开源采用趋势。过去大家看到模型天天突破,企业纷纷入场;现在模型进展没那么猛了,企业开始“更理性消费”,不再四处尝试,而是抱紧那些成熟好用的闭源大模型。结果是,企业的投入正集中流向少数几个高性能的闭源模型,而 Anthropic 也因此跃升为新的市场领跑者。
为了全面捕捉当前 LLM 市场的状态,我们调研了 150 多位来自初创公司和大型企业的技术负责人,聚焦于当下 AI 技术栈的基础层:谁在赢得市场份额?哪些模型已投入生产?又是哪些选择标准正在影响整个技术栈的构建?
以下是我们观察到的关键信息:
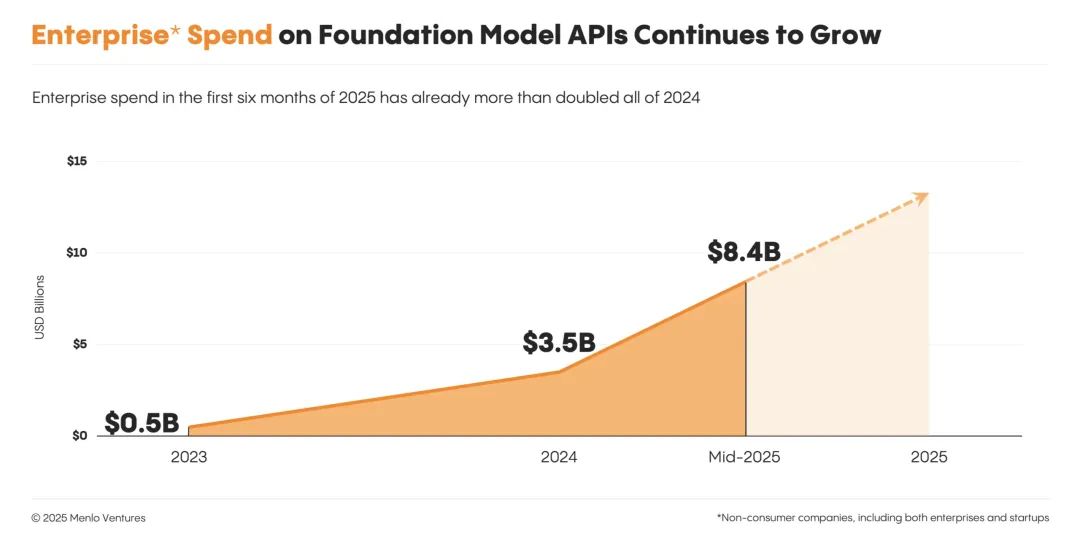

Anthropic 在企业使用率上超越 OpenAI
到 2023 年底,OpenAI 曾占据企业级大模型市场 50% 的份额,是当之无愧的第一。但这一领先优势如今已经明显缩水。现在,OpenAI 的企业使用率只剩 25%,是两年前的一半。
最新的市场头号玩家是 Anthropic,它在企业 AI 市场的占比达 32%,超过了 OpenAI 和最近增长迅猛的 Google(20%)。Meta 的开源模型 Llama 占 9%,而尽管 DeepSeek 在年初高调发布,目前的企业使用占比却只有 1%。
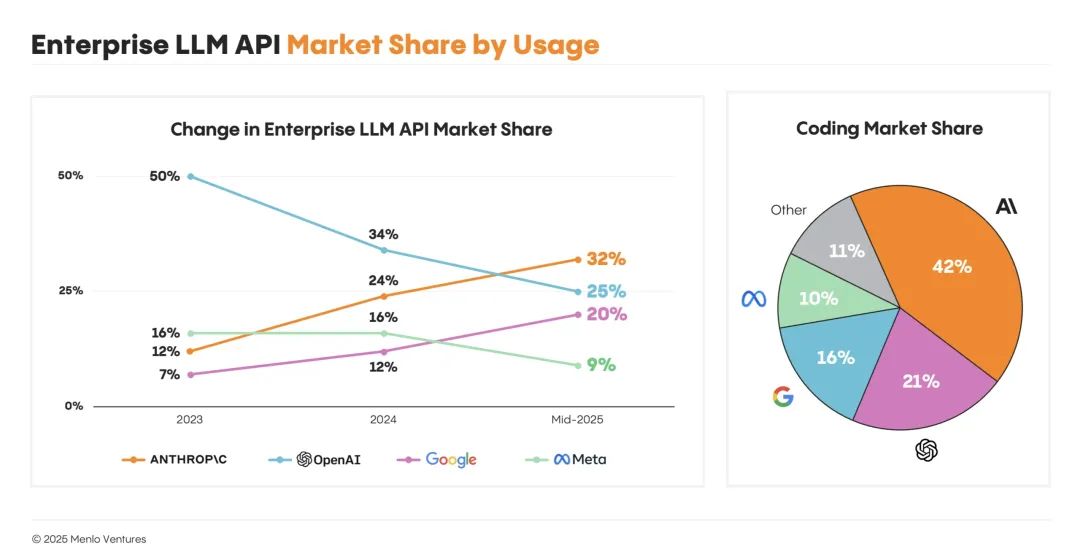
2. 带验证器的强化学习成为智能扩展的新路径。
过去扩展大模型智能的主路径,是不断加大模型规模、喂入更多数据进行预训练。但到了 2024 年,互联网数据的增长已接近瓶颈,单靠“加量”难以持续提升。带可验证奖励的强化学习(RLVR) 成为新的突破口,尤其适用于代码这类结果明确、易于检验的任务领域。这一策略也正逐步成为模型后训练阶段的关键路径,用于提升可靠性与实际能力。
3. 训练模型成为“Agent”,让它们真正有用起来。
最初的大语言模型被设计为“一问一答”的形式,目标是在单轮对话中完成任务。而现在,更强的能力来自于赋予模型“多轮思考”的能力:一步步推理、持续交互、灵活调用工具——也就是所谓的 Agent。2025 年被称为“Agent 之年”,正是因为这一范式的爆发。Anthropic 是其中的领先者,它率先训练模型进行多轮自我优化,并通过 MCP 协议接入包括搜索、计算器、编程环境等外部工具,大幅提升了模型的执行力与用户粘性。

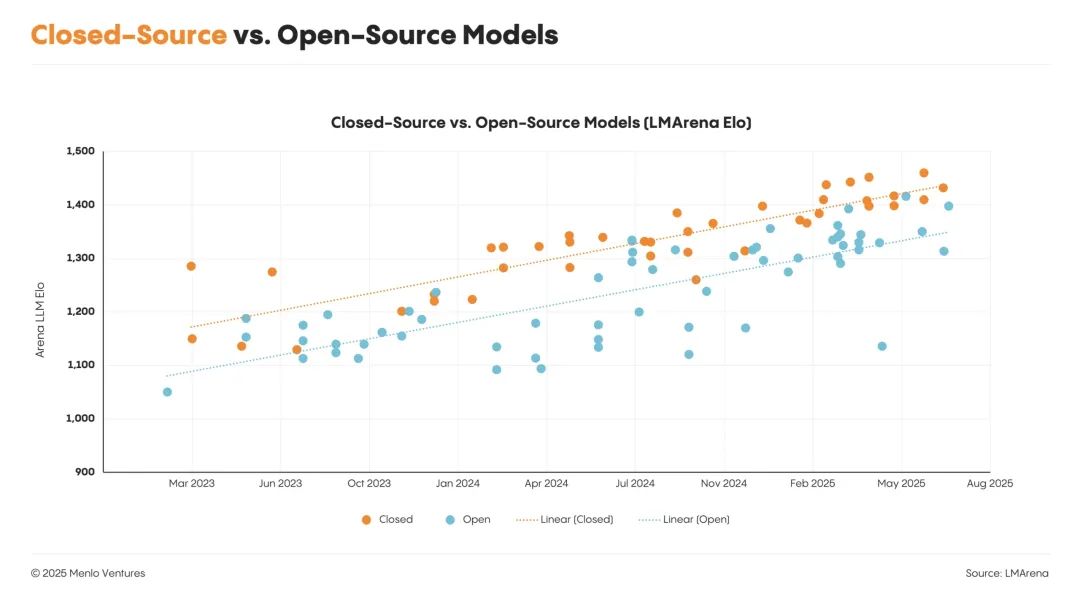
目前,我们 100% 的生产工作负载都在闭源模型上运行。我们最初使用 Llama 和 DeepSeek 进行 POC(概念验证),但随着时间的推移,它们的性能已经无法与闭源模型相媲美。
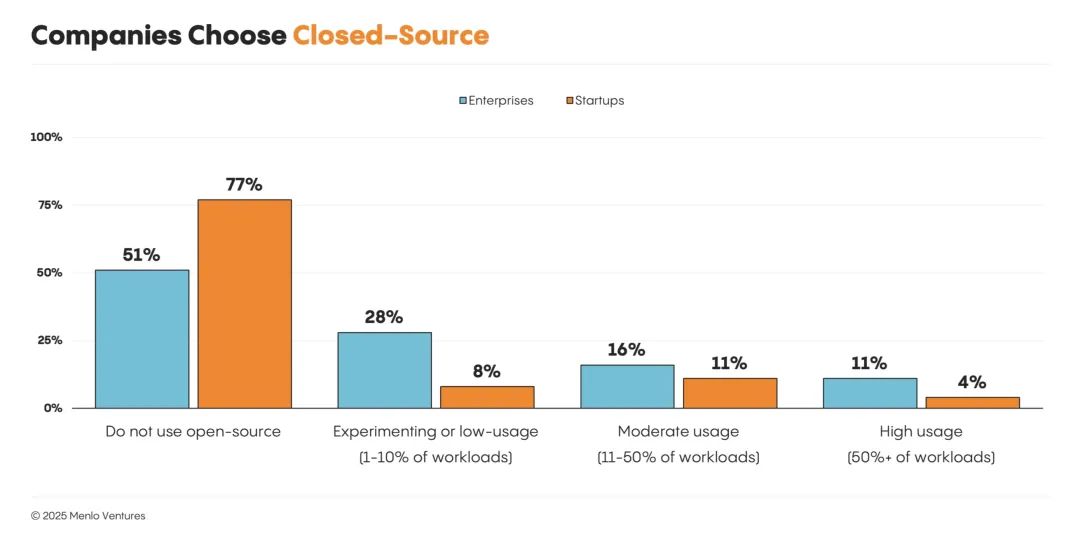

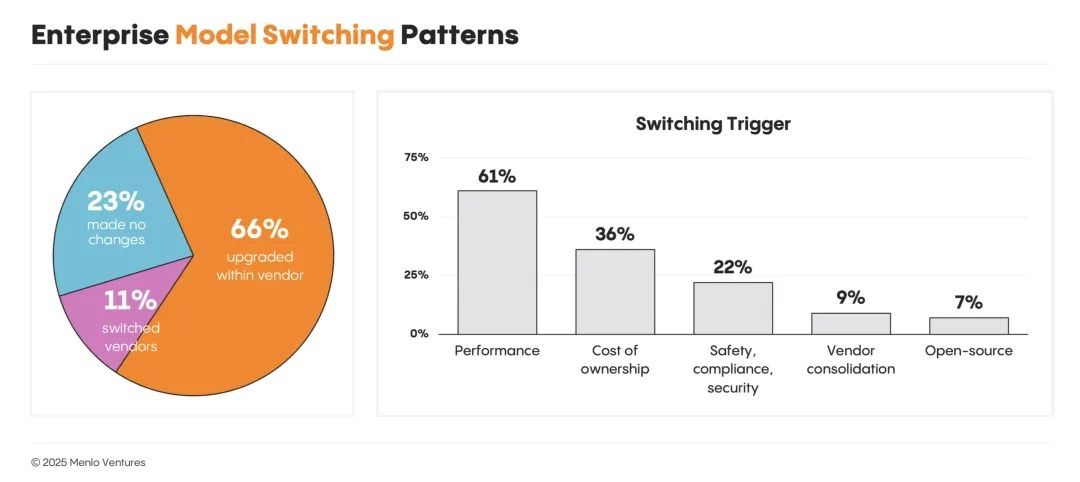

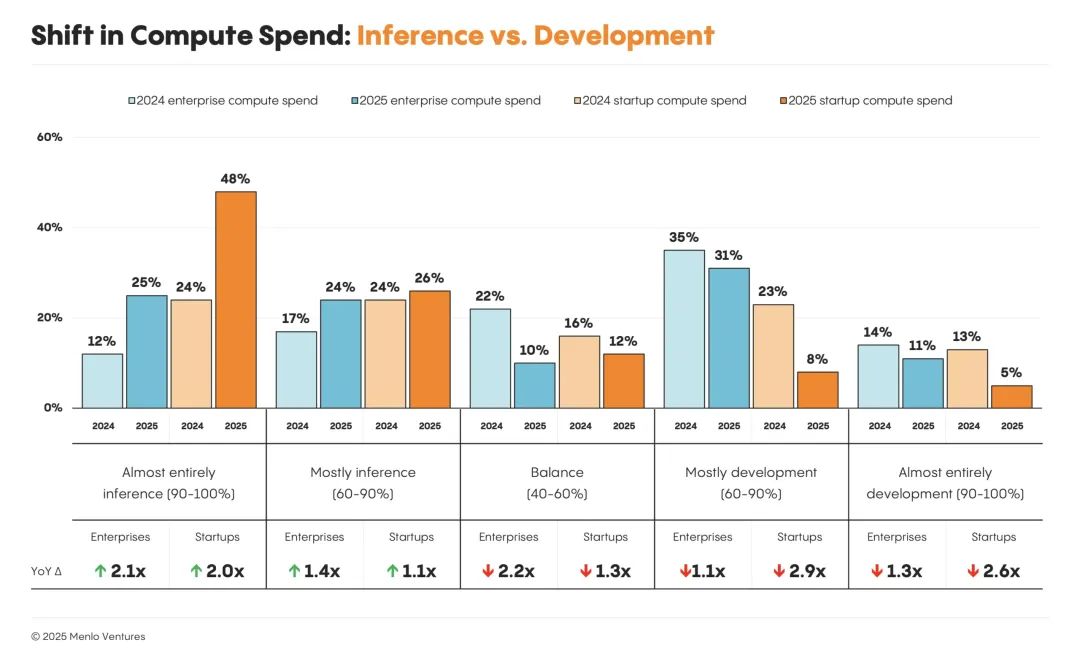
AI 支出正从训练转向推理
计算支出正稳步从模型构建和训练,转向推理。这种转变在初创企业中最为明显:74% 的模型开发者表示,他们的大部分工作任务都来自推理,高于一年前的 48%,大型企业也紧随其后。近一半(49%)的企业表示,他们的大部分或几乎所有计算任务都由推理驱动,高于去年的 29%。



(文:特工宇宙)