

编辑:冷猫
不知道大家是否还记得,人工智能先驱、强化学习之父、图灵奖获得者 Richard S. Sutton,在一个多月前的演讲。
Sutton 认为,LLM 现在学习人类数据的知识已经接近极限,依靠「模仿人类」很难再有创新。
未来人工智能的发展需要从经验中学习,而这一路径始终是「强化学习」。
这也是 Sutton 一以贯之的观点,不论是过去的文章《苦涩的教训(Bitter Lesson)》还是近期的研究工作,都能够显示出这位 AI 领域的核心人物,对于建立一个简单通用的,面向下一个「经验时代」的强化学习算法的热情。

近些天,Sutton 再发新论文,在强化学习领域再次发力,将他在 2024 年的时序差分学习新算法 SwiftTD 拓展到控制领域,在与一些更强大的预处理算法结合使用时,能够展现出与深度强化学习算法相当的性能表现。

-
论文标题:Swift-Sarsa: Fast and Robust Linear Control
-
论文链接:https://arxiv.org/abs/2507.19539v1
Sutton 在 2024 年提出了一种用于时序差分(TD)学习的新算法 ——SwiftTD。该算法在 True Online TD (λ) 的基础上进行了增强,融合了步长优化、对有效学习率的约束以及步长衰减机制。在实验中,SwiftTD 在多个源自 Atari 游戏的预测任务中均优于 True Online TD (λ) 和传统的 TD (λ),且对超参数的选择具有较强的鲁棒性。
在这篇论文中,作者将 SwiftTD 的核心思想与 True Online Sarsa (λ) 相结合,提出了一种基于策略的强化学习算法 ——Swift-Sarsa。
此外,还提出了一个用于线性基于策略控制的简单基准测试环境,称为「操作性条件反射基准」(operant conditioning benchmark)。
问题与方法
控制问题
本论文的控制问题由观测(observations)和动作(actions)构成。智能体在每一个时间步 t 接收到一个观测向量 x_t ∈ ℝⁿ,并输出一个动作向量 a_t ∈ ℝᵈ。观测向量中包含一个特殊的分量,即奖励 r_t。该奖励所在的分量索引在整个智能体生命周期中是固定不变的。
控制问题的性能通过生命周期平均奖励(lifetime average reward)来衡量,定义如下:
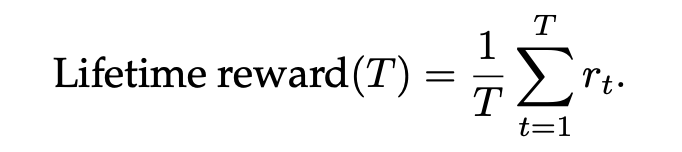
在控制问题中,智能体所选择的动作将决定其未来所能感知到的观测,因此智能体的目标是通过控制未来的观测序列来最大化其生命周期奖励。
Swift-Sarsa
SwiftTD 能够比以往的 TD 学习算法更准确地学习预测值。使其具备更优预测能力的核心思想,同样也可以应用于控制算法中。将 SwiftTD 的关键思想与 True Online Sarsa (λ)(Van Seijen 等,2016)结合,是将其应用于控制问题最直接的方式。
在控制问题中,智能体在每一个时间步的输出是一个具有 d 个分量的向量。Swift-Sarsa 限于动作数量离散的问题。如果动作向量的每个分量只能取有限个数值,那么整个动作空间就可以表示为一个有限的离散动作集合。
Swift-Sarsa 使用 SwiftTD 来为其 m 个离散动作中的每一个学习一个价值函数。在每个时间步,它会计算所有动作的价值,并将它们堆叠起来形成一个动作 – 价值向量。一个策略函数 π: ℝᵐ → {1, …, m} 接收该动作 – 价值向量作为输入,并返回一个离散动作。
当前时间步所选动作的价值被用于构建 bootstrapped target,而前一时间步所选动作的价值则作为预测值用于估计 TD 误差。只有当前所选动作对应的价值函数的资格迹(eligibility trace)向量会被更新。
可以用一些记号对该算法进行更具体的描述。设 wiₜ 是在时间步 t 时,第 i 个动作对应的价值函数的权重向量,ϕₜ 是当前时间步的特征向量。那么,第 j 个动作的价值为:
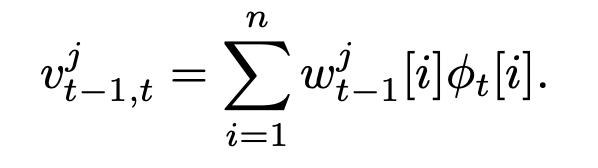
所有动作对应的价值被堆叠形成一个动作 – 价值向量 v_t−1,t ∈ ℝᵐ,其中:
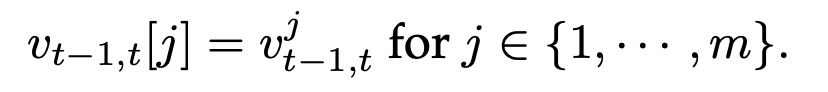
设 a_t 和 a_t-1 分别为时间步 t 和 t-1 选择的动作。Swift-Sarsa 中的 TD 误差为:
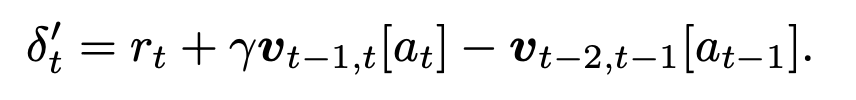
除这些修改外,Swift-Sarsa 与 SwiftTD 是一致的。算法 1 给出了 Swift-Sarsa 的伪代码。

策略函数可以是任意函数,通常会被设计为:价值越高的动作被选择的概率越大。两种常用策略是:
1. ϵ- 贪婪策略(ϵ-greedy policy):以 1 – ϵ 的概率选择具有最高价值的动作,以 ϵ 的概率随机选择一个动作;
2. Softmax 策略:将动作价值转化为离散概率分布。
关于 SwiftTD 算法,请参阅论文:

-
论文标题:SwiftTD: A Fast and Robust Algorithm for Temporal Difference Learning
-
论文链接:https://openreview.net/pdf?id=JdvFna9ZRF
操作性条件反射基准测试
作者设计了一个名为操作性条件反射基准(operant conditioning benchmark)的测试基准,用于评估 Swift-Sarsa 的性能。
该基准定义了一组控制问题,这些问题不需要复杂的探索策略,随机策略也能偶尔选择到最佳动作。这些问题的最优策略可以由线性学习器表示。
在该基准中的问题里,观测向量由 n 个二值分量组成,动作向量由 d 个二值分量组成。n 和 d 是超参数,只要 n > d,它们的任意组合都定义了一个有效的控制问题。
在某些特定的时间步,观测向量的前 m 个分量中恰好有一个为 1,其余时间步则全部为 0。当前 m 个分量中的第 i 个在某个时间步为 1 时,若智能体选择的动作向量中第 i 个分量为 1 且其余分量为 0,则该智能体将在之后获得一个延迟奖励。该奖励延迟 k_1 个时间步,其中 k_1 是一个变量,每次智能体选择该奖励动作时从区间 (ISI_1, ISI_2) 中均匀采样。在所有其他时间步,奖励为 0。
每隔 k_2 个时间步,观测向量的前 m 个分量中会随机有一个被置为 1,其中 k_2 是一个变量,每次从区间 (ITI_1, ITI_2) 中均匀采样。
在每一个时间步,观测向量中其余 n − m 个分量中每一个以概率 µ_t 被置为 1。初始时 µ_1 = 0.05,之后按如下规则递归更新。
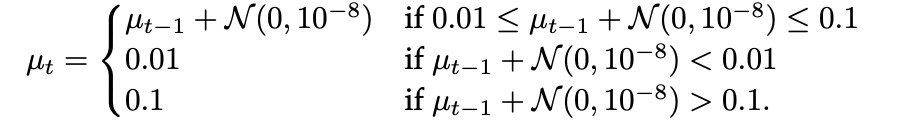
操作性条件反射基准的灵感来源于 Rafiee 等人(2023)提出的动物学习基准。动物学习基准的设计灵感来自行为主义者在动物身上进行的经典条件反射实验,而操作性条件反射基准则是受到了操作性条件反射实验的启发。两者的关键区别在于:
-
在操作性条件反射实验中,动物所选择的行为会影响奖励的出现频率;
-
而在经典条件反射实验中,动物无法控制奖励的出现,只能学习去预测即将到来的奖励(如巴甫洛夫的狗实验)。
实验结果
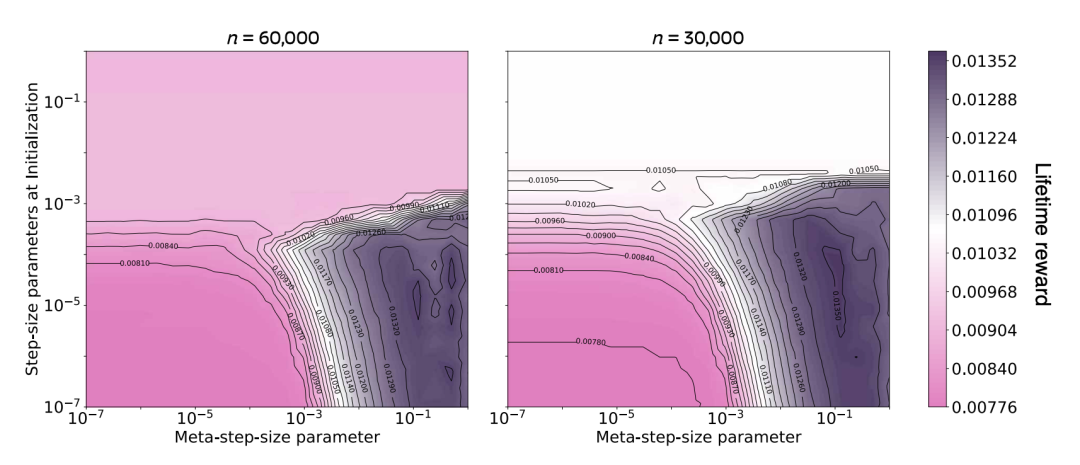
本论文在操作性条件反射基准上针对不同的 n 值对 Swift-Sarsa 进行了实验。
图 1 展示了在两种不同 n 值下,元步长参数(meta-step-size)和初始步长参数对平均奖励的影响。类似于 SwiftTD 的表现,Swift-Sarsa 的性能随着元步长参数的增大而提升,表明步长优化带来了明显的好处。在较宽的参数范围内,Swift-Sarsa 实现的生命周期奖励接近最优生命周期奖励(约为 0.014)。当干扰特征数量增加时,问题变得更具挑战性,Swift-Sarsa 的表现也随之下降。
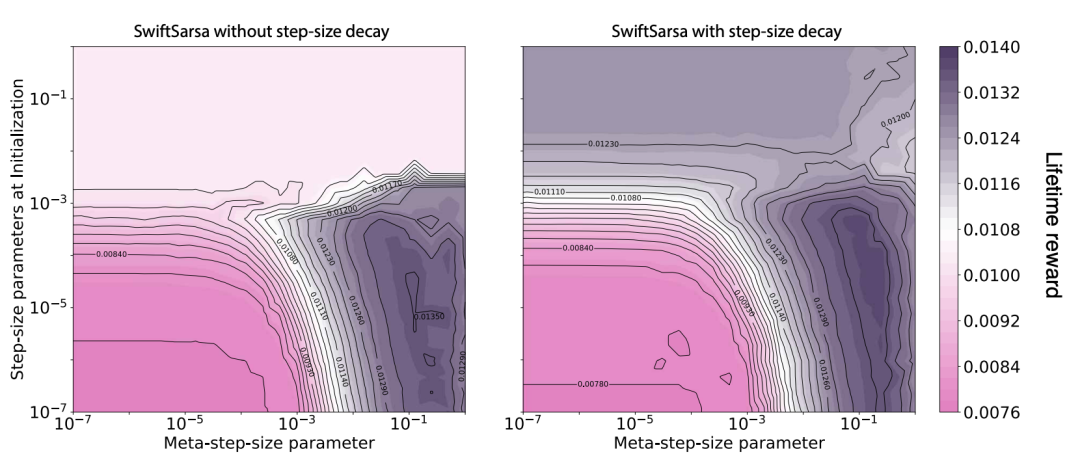
在第二组实验中,我们比较了步长衰减(step-size decay)对 Swift-Sarsa 性能的影响,结果如图 2 所示。与其在 SwiftTD 中的作用类似,当初始步长参数设置过大时,步长衰减能够提升 Swift-Sarsa 的性能。
值得注意的是,若将 Swift-Sarsa 与更强大的预处理方法结合使用,它在更复杂的问题上(如 Atari 游戏)可能也能达到与深度强化学习算法相当的性能水平。
更多信息,请参阅原论文。
©
(文:机器之心)