

“Qwen3-SmVL”是一个基于阿里Qwen3-0.6B与SmolVLM2-256M视觉编码器,通过特征对齐+指令微调构建的中文超小多模态大模型,可在1 GB显存设备完成推理,同时具备看图回答、OCR、视觉推理等能力,面向端侧中文场景开源发布。
一、技术原理
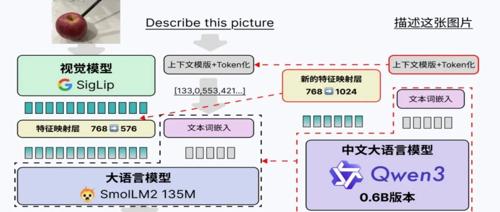
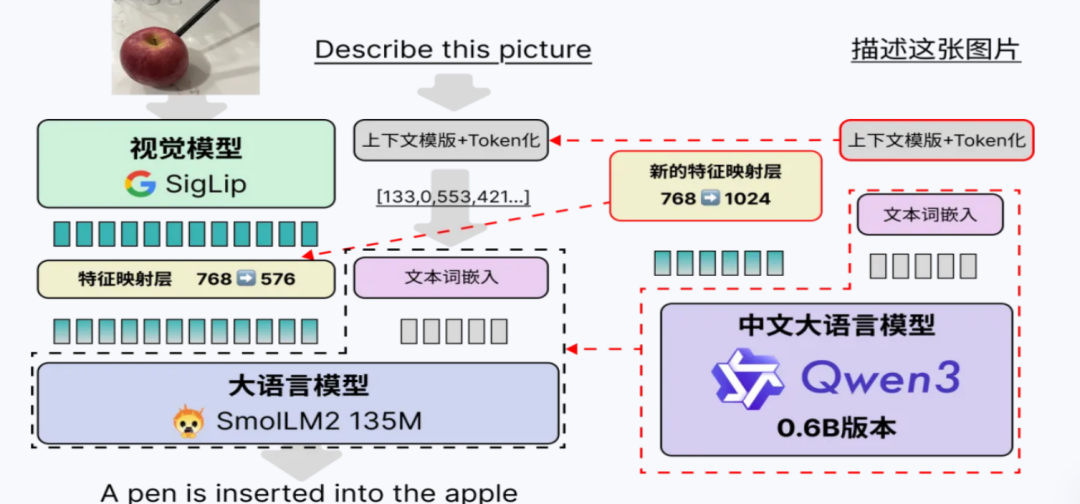
(一)模块化架构设计
-
视觉模块:采用轻量级视觉Transformer(如SmolVLM2-256M中的SigLip-93M),提取图像特征后通过**Pixel Shuffle**降采样,减少Token数量。
-
文本模块:使用Qwen3-0.6B作为语言模型基座,保留其函数调用、推理等能力。
-
融合模块:通过轻量级MLP将视觉特征(768维)映射到文本空间(576维),实现跨模态对齐。
(二)上下文格式设计
为兼容Qwen3原有结构,图像特征以如下格式插入上下文:
“`
<|im_start|>user
<vision_start><row_1_col_1><|image_pad|>(图像)<|image_pad|><vision_start>
(用户提问)
<|im_end|>
<|im_start|>assistant
<think></think>
(回答)
<|im_end|>
“`
该格式保留了Qwen3的函数调用与推理能力,同时支持图像输入。
(三)中文优化策略
-
中文适配器:在文本模块中加入轻量级中文语义增强模块,提升对汉字、成语、文化语境的理解。
-
中文数据增强:使用同义词替换、汉字重叠度计算等方式增强训练数据,提升泛化能力。
-
场景化数据:训练数据涵盖街景、书法、商品广告等中文场景,增强实用性。
(四)训练与微调策略
-
两阶段训练:
1. 图文对齐预训练;
2. 中文场景微调(含14%纯文本数据保留语言能力)。
-
渐进式解冻:先训练融合层,再逐步解冻适配器,最后微调少量语言模型层,降低训练成本。
(五)推理与部署优化
-
支持**INT4量化,模型体积压缩至700MB,适配移动端;
-
可导出为**ONNX格式,在安卓端实现320ms响应的商品图像描述。
二、主要功能
(一)看图问答
Qwen3 – SmVL具备强大的看图问答能力,能够精准应对各种中文开放问答需求。无论是询问“图中文字写了什么?”这类对图像文字信息提取的简单问题,还是如“这张图讽刺了什么?”这类需要深入理解图像内涵和社会现象的复杂问题,模型都能基于图像内容给出准确且有针对性的回答。
(二)OCR与结构化输出
在光学字符识别(OCR)及输出结构化信息方面,Qwen3 – SmVL表现出色。它不仅能够准确识别图像中的文字内容,还能将这些文字以特定的结构化格式输出,如Markdown表格和LaTeX数学公式。这一功能在试卷拍照解析等场景中具有极高的实用价值。
(三)多图与多轮对话
Qwen3 – SmVL支持在同一上下文环境中插入多张图像,并实现跨图指代的多轮对话。用户可以在对话过程中依次展示多张相关图像,并提出诸如“上一张图里的价格是多少?”这样的问题。模型能够精准定位到指定的图像,并结合之前的对话内容进行准确回答。
(四)函数调用与Agent流程实现
继承了Qwen3的MCP协议,Qwen3 – SmVL具备强大的函数调用和Agent流程实现能力。它可以结合外部工具链,完成一系列复杂的任务。例如,当用户提供一张图像时,模型可以先对图像进行分析,然后调用搜索引擎获取相关的背景信息,最后根据这些信息生成一份详细的报告。这种智能的工作流程,使得模型不仅仅是一个简单的问答工具,而是能够像一个智能助手一样,为用户提供全方位、深层次的服务。
三、应用场景
(一)、端侧教育
Qwen3 – SmVL在端侧教育领域展现出了巨大的优势。学生可以使用Pad进行拍照搜题,无需依赖网络连接,因为该模型仅需本地1 GB显存即可运行。当学生遇到不会的题目时,只需用Pad拍下题目,Qwen3 – SmVL就能快速识别题目内容,并给出详细的解答思路和答案
(二)、智能零售
Qwen3 – SmVL为智能零售带来了新的解决方案。通过对商超价签进行拍照,模型能够快速准确地识别价格信息,并将其与库存管理系统相结合,实现实时的库存更新。这大大降低了云端成本,因为不需要将大量的图像数据上传到云端进行处理。同时,提高了库存管理的准确性和及时性,避免了因库存信息不准确而导致的销售损失。
比如,当商品价格发生变化时,员工只需拍摄新的价签,Qwen3 – SmVL就能自动更新系统中的价格和库存信息,确保顾客能够获得准确的商品价格和库存情况。
(三)、工业巡检
Qwen3 – SmVL在工业巡检领域具有独特的优势。无人机可以搭载该模型进行拍照巡检,在本地完成缺陷检测。模型能够对拍摄的图像进行快速分析,识别出设备中的缺陷和异常情况,并生成详细的维修清单。这种方式不仅提高了巡检的效率和准确性,还保障了数据隐私,因为图像数据不需要上传到云端,避免了数据泄露的风险。
例如,在大型工厂的设备巡检中,无人机可以快速飞过各个设备,Qwen3 – SmVL实时分析图像,及时发现潜在的问题,为设备维修提供有力的支持。
(四)、移动办公
Qwen3 – SmVL为移动办公带来了便利。用户可以使用手机扫描合同,模型能够自动提取合同中的关键信息,如条款、金额、日期等,并生成摘要。这大大提升了外勤人员的工作效率,使他们能够在外出时快速处理合同和文档。
例如,销售人员在与客户签订合同后,只需用手机扫描合同,Qwen3 – SmVL就能迅速提取关键信息,生成摘要发送给上级领导,方便领导及时了解合同情况,做出决策。同时,这种方式也减少了人工输入的错误,提高了信息处理的准确性。
四、快速使用
目前,Qwen3-SmVL 并未提供直接可用的预训练模型供用户下载,需要用户自行进行微调训练。不过,Qwen3-SmVL 的相关代码和数据集已经开源,用户可以参考其提供的 GitHub 仓库(https://github.com/ShaohonChen/Qwen3-SmVL),在合适的硬件环境下(如沐曦 C500 或 Nvidia 40G 以上显卡)进行训练。以下是快速上手的步骤:
1. 克隆代码仓库
打开终端,运行以下命令,将 Qwen3-SmVL 的代码仓库克隆到本地:
git clone https://github.com/ShaohonChen/Qwen3-SmVL.gitcd Qwen3-SmVL
2. 安装依赖
在项目根目录下运行以下命令,安装所需的 Python 依赖:
pip install -r requirements.txt 3. 下载数据集
使用项目提供的脚本下载训练数据集。运行以下命令:
bash download_resource.sh该脚本会自动从 Hugging Face 或 ModelScope 下载所需的训练数据集。
4. 配置训练环境
确保你的硬件环境满足要求(推荐使用沐曦 C500 或 Nvidia 40G 以上显卡)。根据你的硬件配置,修改训练配置文件(如 `train.yaml`)中的参数,例如显存大小、批处理大小等。
5. 开始训练
根据你的需求选择训练模式。例如,使用单 GPU 训练可以运行以下命令:
CUDA_VISIBLE_DEVICES=0 python train.py ./train.yaml如果你有多个 GPU,可以使用 `accelerate` 工具进行分布式训练。例如,使用 8 张 GPU:
accelerate launch --num_processes 8 train.py ./train.yaml五、结语
从36 T token预训练的Qwen3,到0.09 B视觉编码器的SmolVLM2,再到社区驱动的Qwen3-SmVL,我们看到开源协作正把“大”模型做得“更小、更快、更懂中文”。如果你正在寻找一款可离线、可商用、1 GB显存即可跑的中文多模态大模型,Qwen3-SmVL值得立刻尝试。更多资料请查看:
• GitHub源码与权重:https://github.com/ShaohonChen/Qwen3-SmVL
• SwanLab训练看板:https://swanlab.cn/@ShaohonChen/Qwen3-SmVL/overview
• 沐曦AI芯片文档:https://www.metax-tech.com
• Qwen3官方技术报告:http://139.9.1.231/index.php/2025/05/17/qwen3-technical-report/
(文:小兵的AI视界)