

大型语言模型(LLMs)在代码理解和生成领域取得了长足进步,能够跨越多种编程语言提供智能反馈、检测潜在bug并基于人类指令更新代码片段。代码反思(Code Reflection)作为LLM检查并修改其先前响应的能力,显著提升了开发效率和编程可访问性。
尽管HumanEval、LiveCodeBench等基准测试评估了代码生成和现实相关性,但现有工作忽略了在代码仓库中修改代码的实际场景。考虑到提高反思能力和避免动态基准中数据污染的挑战,本文提出了LiveRepoReflection,一个挑战性基准,用于评估多文件仓库上下文中的代码理解和生成能力,包含跨6种编程语言的1,888个经过严格筛选的测试案例,确保多样性、正确性和高难度。我们创建了RepoReflection-Instruct,一个大规模、质量过滤的指令调整数据集,用于训练RepoReflectionCoder,通过涉及代码生成和错误驱动修复的两轮对话过程。我们的排行榜评估了超过40个LLMs,综合反映了模型在基于仓库的代码反思方面的表现。
Part.1/ 背景——仓库级代码反思任务
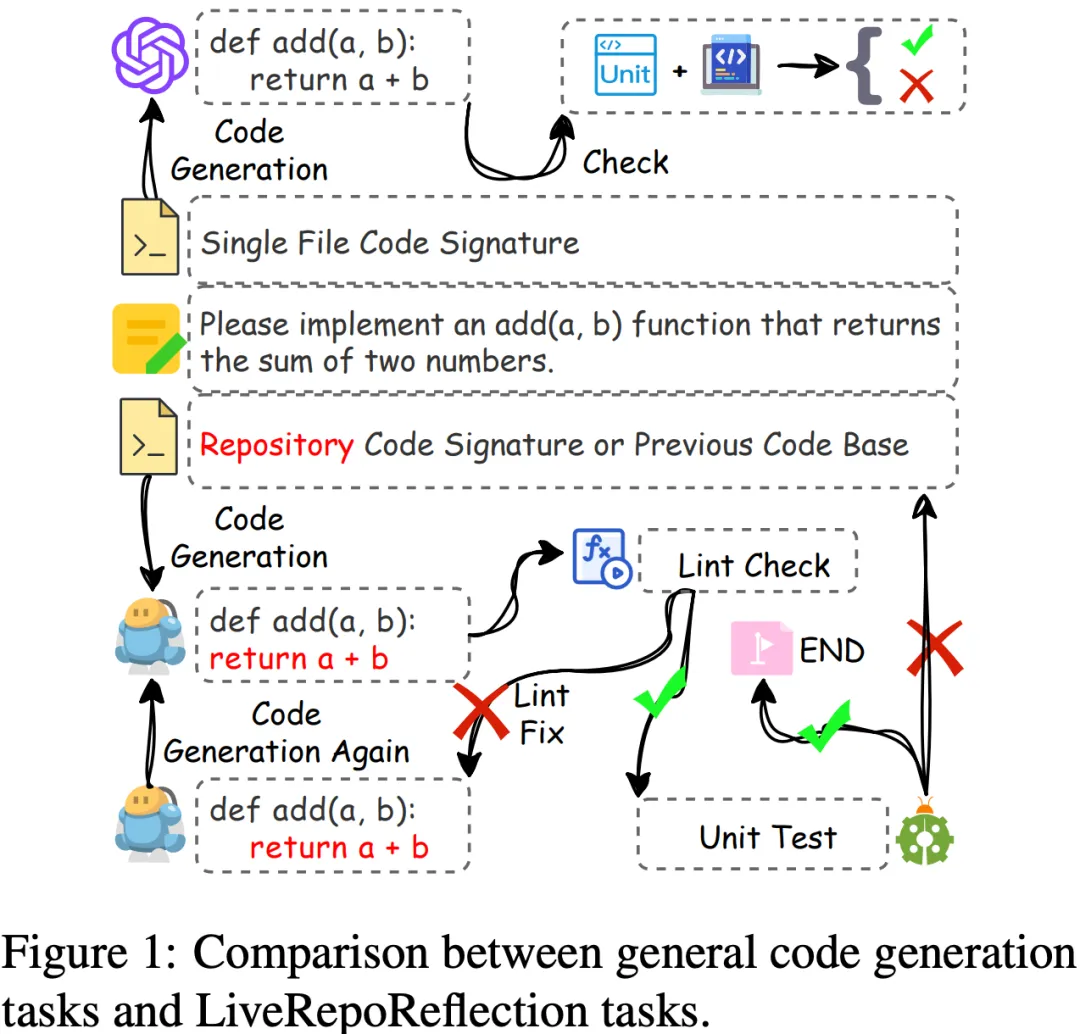
与传统代码生成任务相比,代码仓库反思面临更为复杂的挑战。如上图所示,相较于从头生成代码的简单任务,仓库反思要求模型理解多文件的依赖关系,并能根据编译或运行时错误进行系统性的代码修改。 LiveRepoReflection基准通过设计严格的评估流程,测试模型是否能够:
-
理解完整仓库结构和多文件依赖关系 -
根据错误信息进行有针对性的代码修改 -
在不同编程语言间保持一致的高性能
Part.2/ 自动动态管道构建
为避免数据污染和基准过拟合问题,作者提出了一套自动动态的数据构建流程:
-
从Exercism等来源提取仓库代码,优化仓库文件结构 -
从GitHub、Hugging Face和Stack Overflow等公开来源收集代码片段 -
按编程语言过滤数据 -
使用随机选择的”创意型”LLM从种子数据生成程序主题和定义 -
使用多个”推理型”LLM生成单元测试和参考解决方案 -
交叉执行验证每个单元测试-解决方案对,筛选异常,保留通过率最低的测试和通过率最高的解决方案 -
将所有内容打包为最终的仓库结构
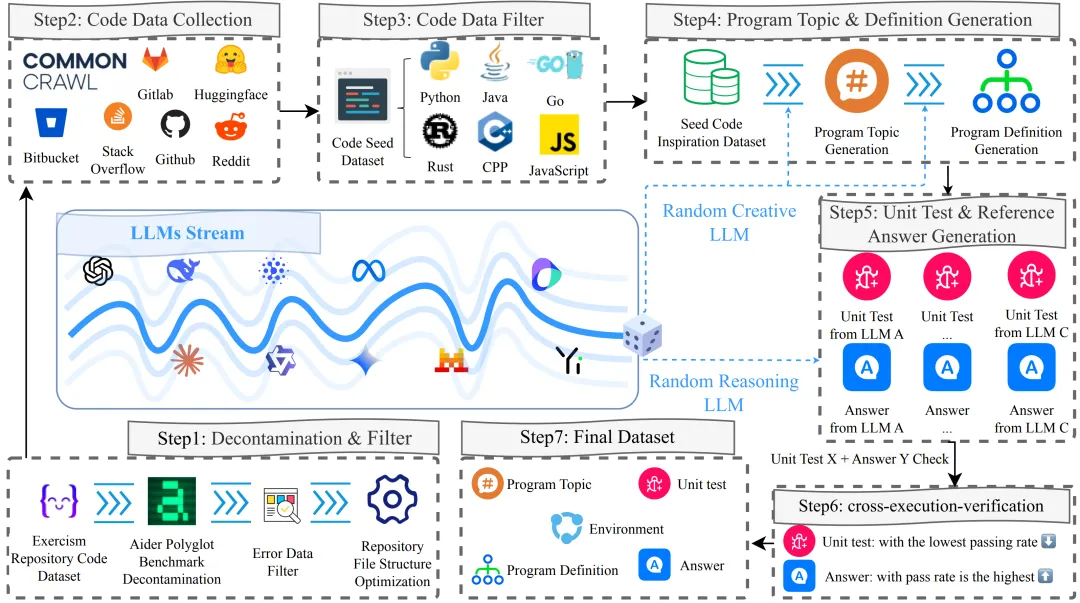
这一流程确保了基准的高质量和动态更新能力,有效防止了模型对特定数据集的过拟合。
同时,我们尽可能标准化仓库结构,提供了Python, Java, Rust, CPP, Go和JavaScript共六种编程语言的标准结构。

Part.3/ LiveRepoReflection评测基准
为确保LiveRepoReflection的质量和难度,研究团队采用了严格的筛选流程:
-
可执行程序筛选:从自动流程生成的10万个仓库案例中,在沙箱中运行,包括环境设置、编译和测试,剔除所有LLM都能通过或运行时间超过180秒的案例,保留1万个高难度、高正确性的案例。 -
难度筛选:10个主流强推理LLM对每个代码程序案例进行测试,每个LLM有一次修改机会。根据通过率将案例分为”简单”、”中等难度”和”高难度”,保留2300个高质量、高难度、高多样性的案例。 -
人工标注:8位研究生在完整代码运行沙箱环境中对每个案例进行检查,确认代码程序案例的合理性、环境配置、文件结构、参考答案和单元测试的正确性,最终保留1,888个测试案例。
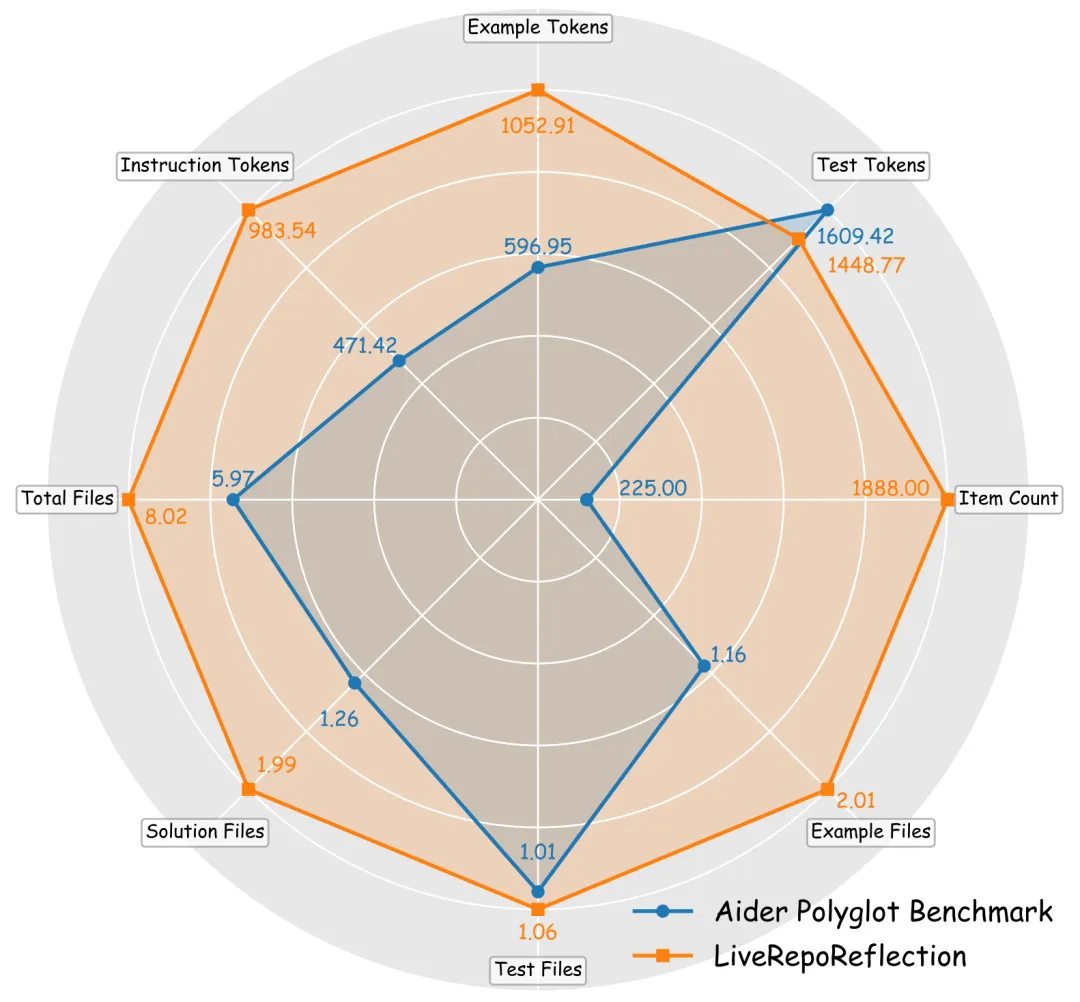
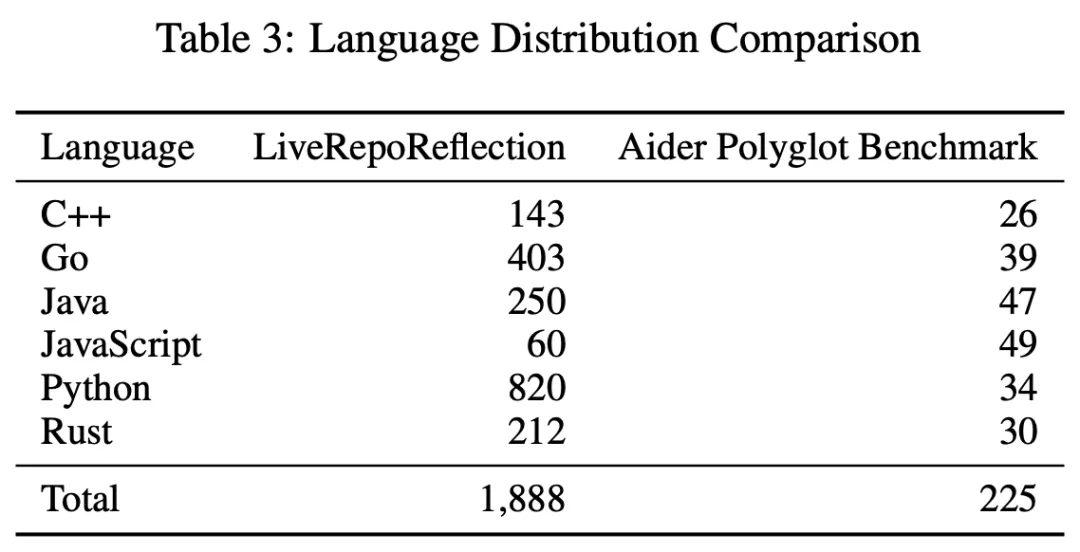
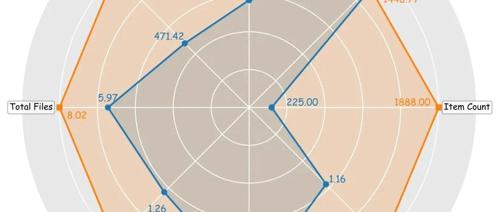
与现有Aider Polyglot基准相比,LiveRepoReflection在多个维度上实现了显著提升:问题数量增加了8倍以上,提供了更丰富的问题描述和示例上下文,平均每个仓库包含更多文件,更真实地模拟了实际代码库的复杂结构。
Part.4/ RepoReflectionCoder训练
为训练高性能的RepoReflectionCoder,研究团队构建了RepoReflection-Instruct指令语料库:
-
高质量数据筛选:从约50万个自动管道生成的代码示例中,通过严格的拒绝采样保留符合五项标准的高质量数据: -
至少一个单元测试文件 -
至少一个参考答案文件 -
代码签名文件数与参考答案文件数匹配 -
环境配置文件与声明的编程语言一致 -
文件命名和扩展名标准化 -
质量评分机制:使用加权评分函数评估每个代码程序,考虑执行能力、新颖性、难度、代码风格和困惑度的逆向指标。 -
数据去污染:通过MinHash算法和LSH索引高效过滤与测试集相似度高于0.8的候选文本,确保训练数据与测试集的纯净度。 -
多轮交互生成:使用四个顶级模型模拟84万多轮编码对话,包括直接生成(40%)、错误驱动修复(40%)、风格标准化(10%)和对话总结(10%)。
Part.5/ 实验结果
LiveRepoReflection提供了两种评估格式:全文件代码生成和基于补丁的增量编辑。

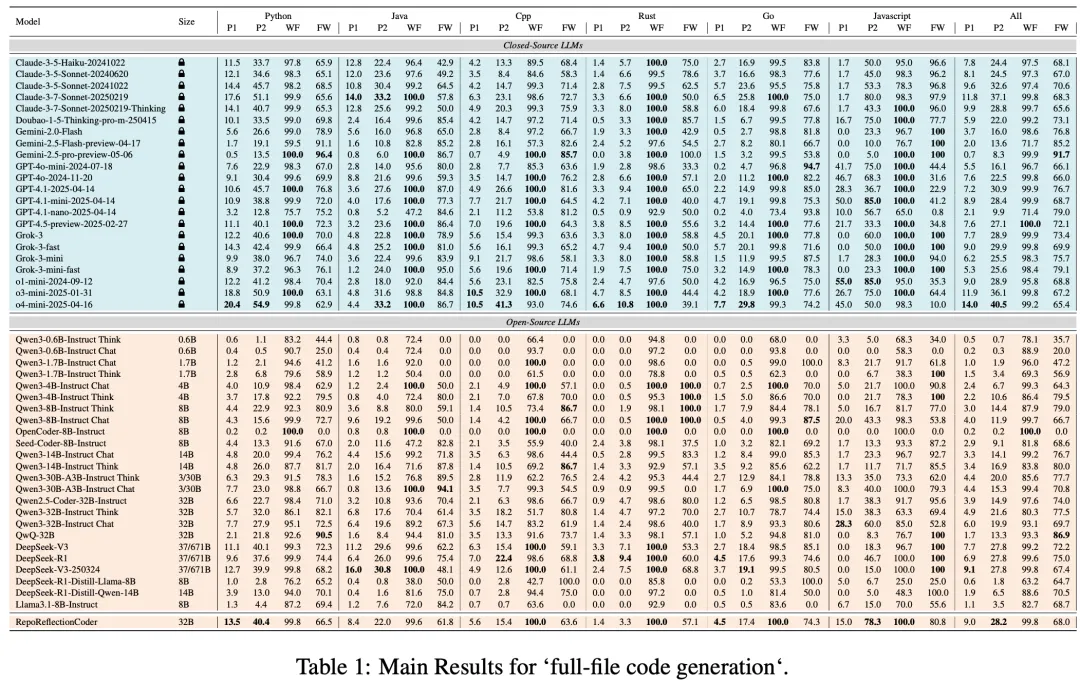
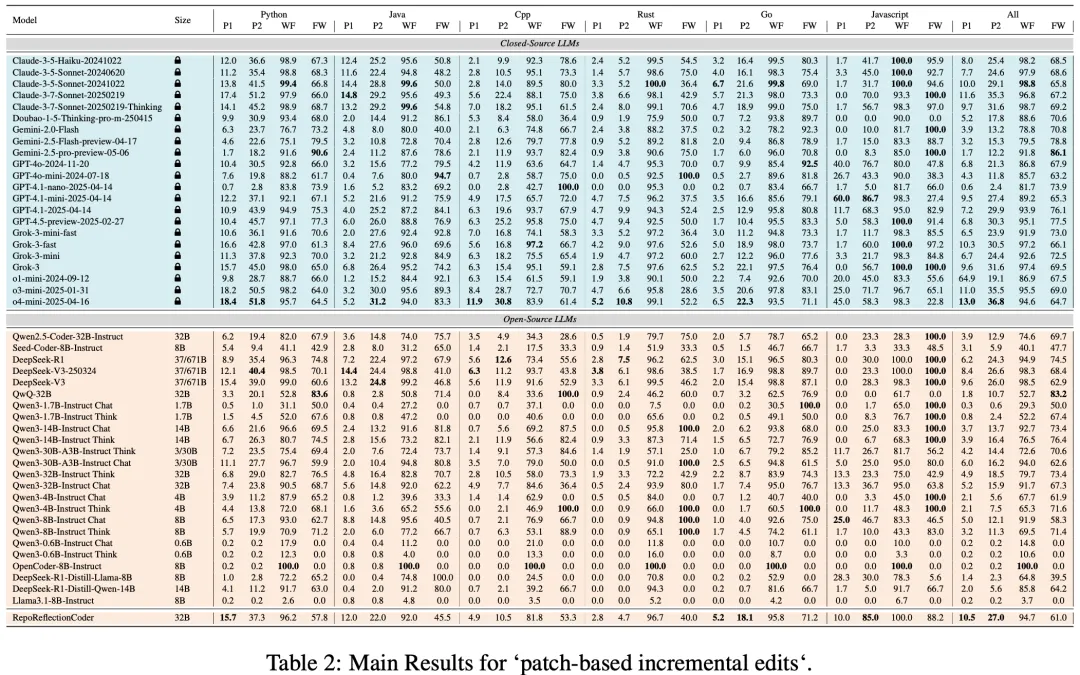
实验评估了GPT-4.5、Claude-3.7、OpenAI o系列/GPT4系列、Gemini、Qwen系列以及Grok等40多个LLM,采用四个关键指标:
-
Pass@1:LLM首次尝试完成的编码任务比例 -
Pass@2:查看失败代码和错误消息后二次尝试的成功率 -
修复权重(FW) :二次尝试成功中错误诊断和修正的相对贡献 -
格式合规(WF) :LLM严格遵循系统提示中指定编辑格式的百分比
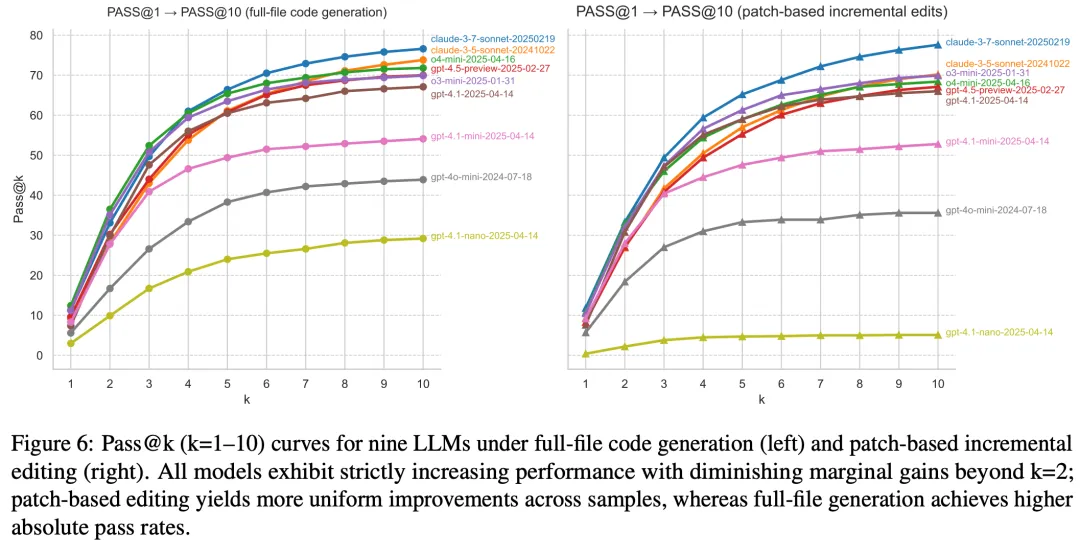
结果显示:
-
领先的闭源模型在一次性和反馈后准确率方面始终表现最佳 -
开源模型表现落后,但在允许二次尝试时显示类似的相对提升 -
各系统发现Python任务最简单,而C++和Rust最具挑战性 -
几乎每个模型的格式合规率都超过90% -
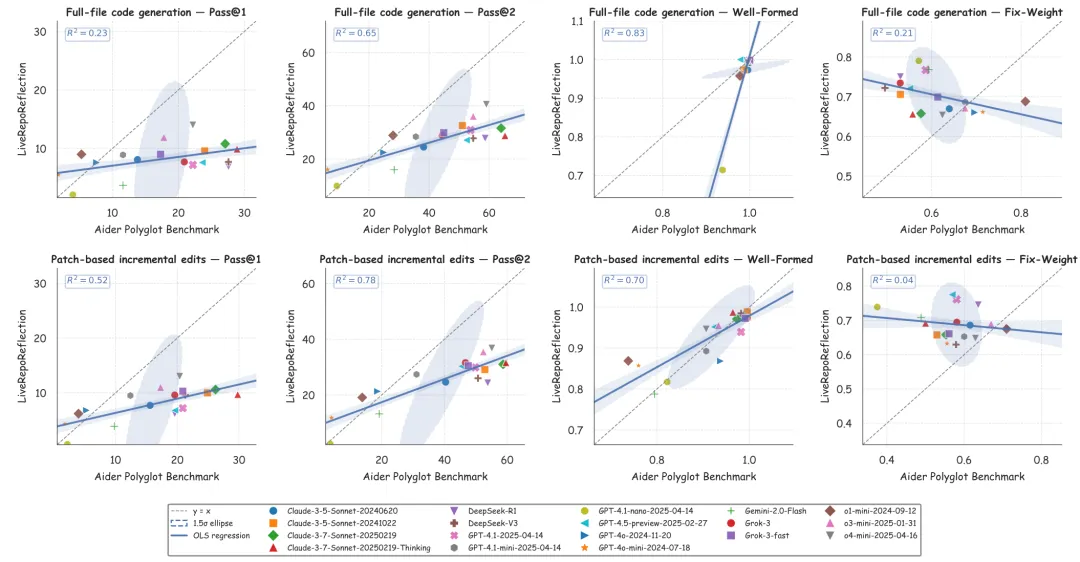
RepoReflectionCoder明显优于基础Qwen2.5-Coder,但仍落后于顶级闭源表现者。 与Aider Polyglot基准相比,LiveRepoReflection更具挑战性,几乎所有模型在新基准上的表现都低于老基准,证明了其更高的难度水平和对真实世界代码生成与修复能力的评估价值。
Part.6/ 结论与展望
本研究提出了LiveRepoReflection,一个针对多文件代码仓库理解和生成的高难度基准,通过自动化流程和人工验证确保了测试案例的多样性、正确性和挑战性。同时,研究团队构建了RepoReflection-Instruct指令集并训练了RepoReflectionCoder,在基于仓库的代码反思能力方面取得显著性能提升。 实验结果表明,LiveRepoReflection能够真实有效地测量模型在跨文件依赖和迭代修复场景中的反思和修复能力,为后续研究提供了坚实基础。尽管模型性能还有提升空间,但本研究为多文件仓库代码理解和生成树立了新的标准。
Part.7/ 作者与机构

张蔚,北京航空航天大学和上海人工智能实验室联合培养在读博士一年级,主要研究方向为代码智能,曾经在通义千问实习。

杨健,北京航空航天大学计算机学院副教授,在ICLR、NeurIPS、ACL等国际期刊/会议发表第一/通讯作者20余篇,谷歌学术引用8000+次,并担任NeurIPS、ACL 等国际会议的领域主席。曾作为阿里星入职Qwen,积极推动代码大模型开源。

李舟军,北京航空航天大学计算机学院教授,信息安全系主任,智能信息处理研究所副所长。国务院学位委员会首届网络空间安全学科评议组成员,中国人工智能学会语言智能专委会副主任委员,深圳智能思创创始人与首席科学家。
主页: http://livereporeflection.github.io/论文:https://arxiv.org/abs/2507.09866评测数据:https://github.com/LiveRepoReflection/LiveRepoReflection代码:https://github.com/LiveRepoReflection/LiveRepoReflection-Project
(文:PaperAgent)