
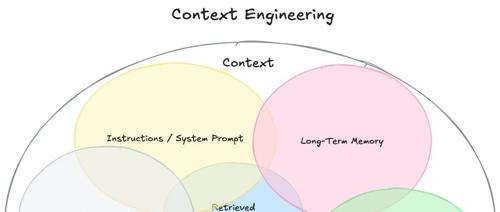
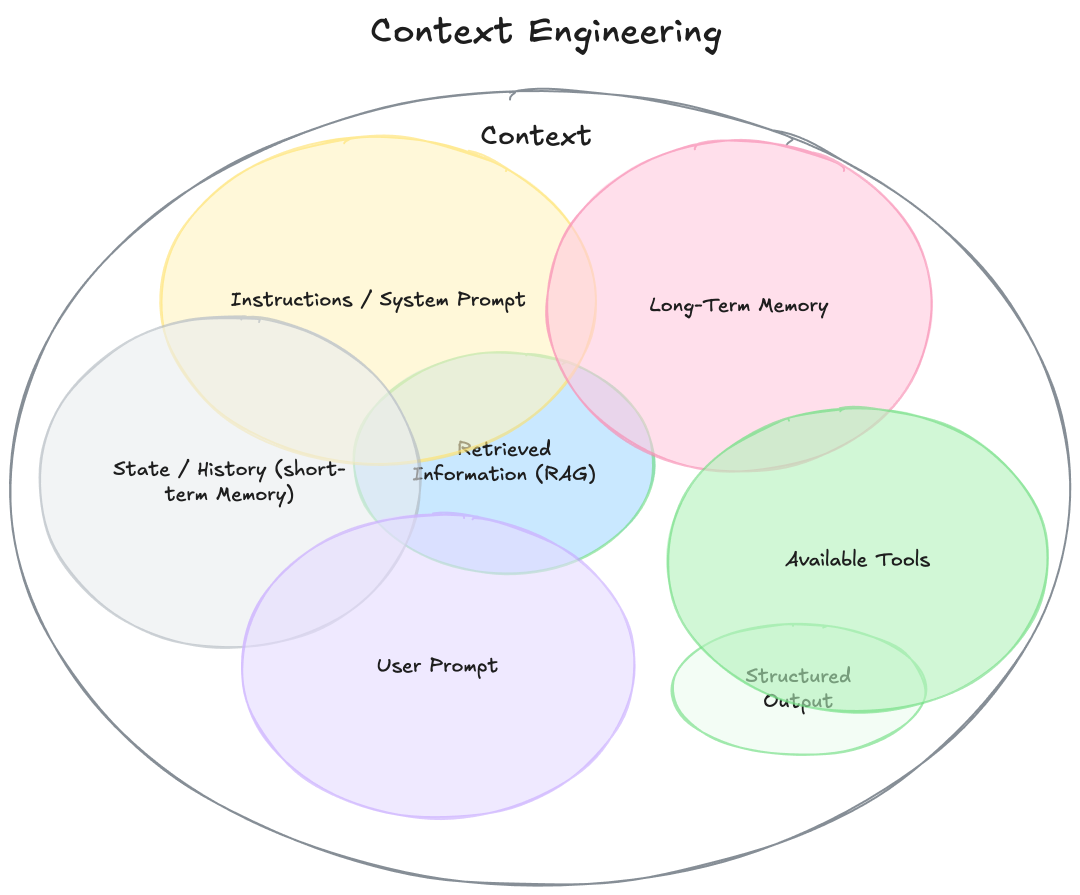
上下文工程可以形式化为一个优化问题,目标是找到一组理想的上下文生成函数,以最大化LLM输出的预期质量。给定任务的分布,目标是:


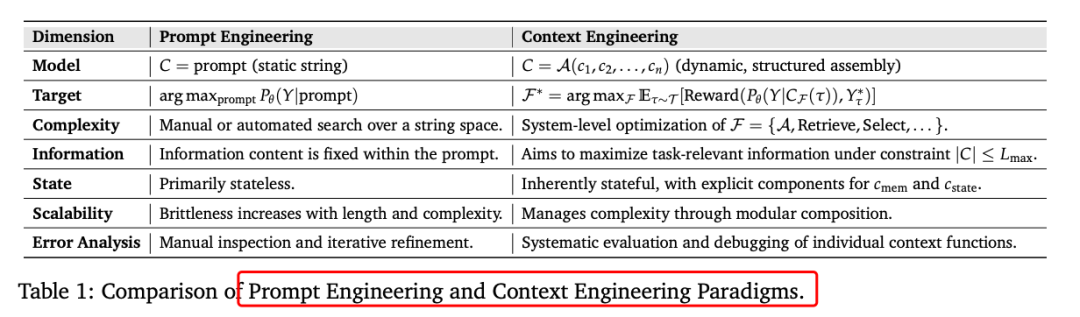
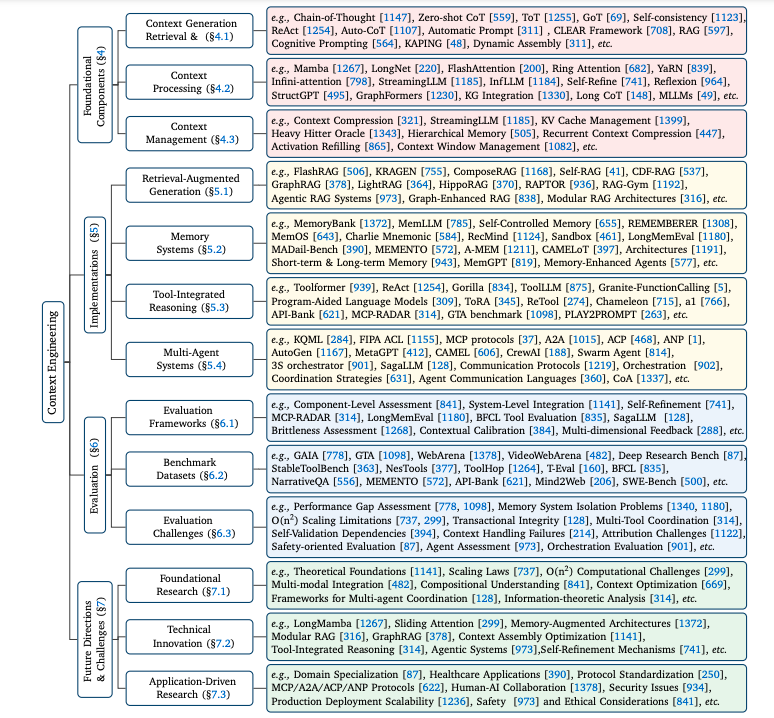
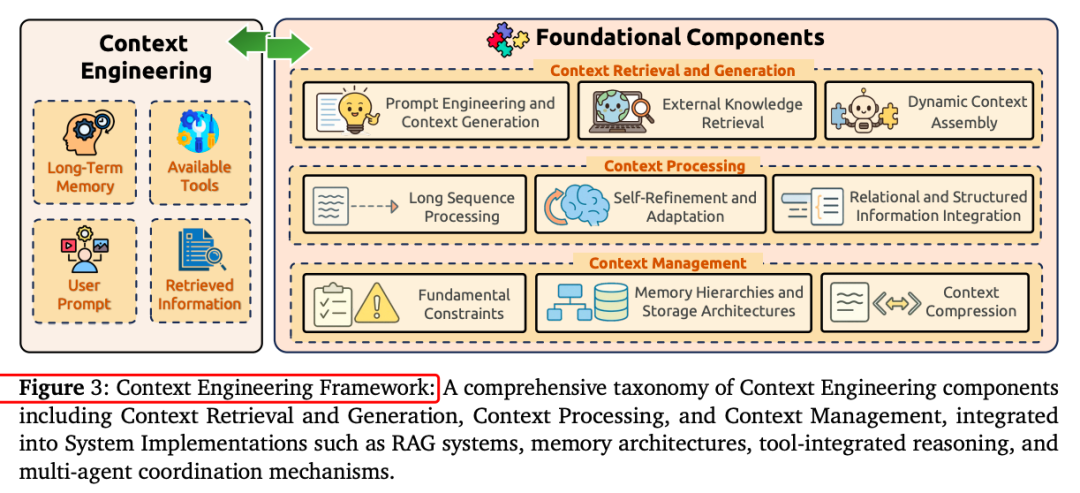
一、上下文工程的基础组件
-
上下文检索与生成:包括基于提示的生成、外部知识检索和动态上下文组装。例如,提示工程通过设计有效的指令和推理框架来引导模型输出;外部知识检索通过RAG等技术结合模型内部知识和外部信息。
-
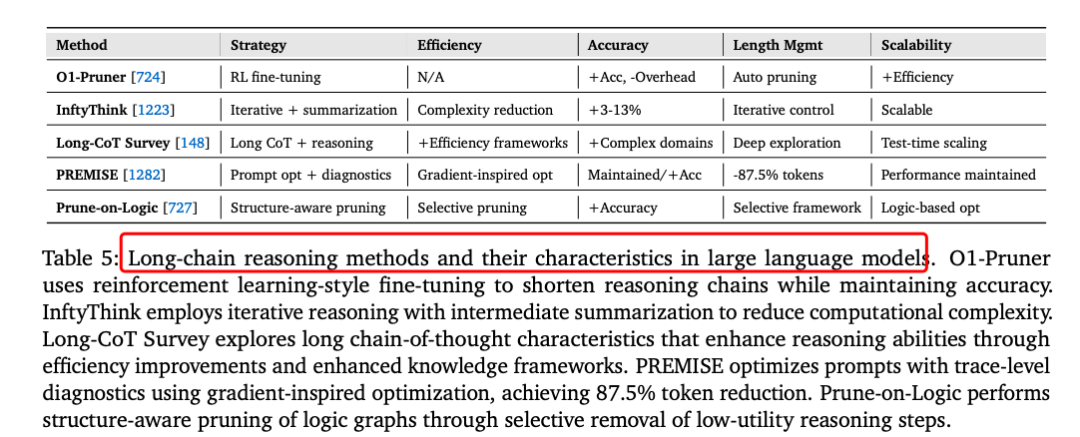
上下文处理:涉及长序列处理、自我优化机制和结构化信息集成。例如,长上下文处理技术如LongNet将Transformer复杂度从二次降至线性,支持百万级标记。
-
上下文管理:包括内存层次结构、压缩和优化。例如,MemGPT通过虚拟内存管理实现超长对话,LLMLingua实现20倍压缩,保持任务性能。
二、上下文工程的系统实现
-
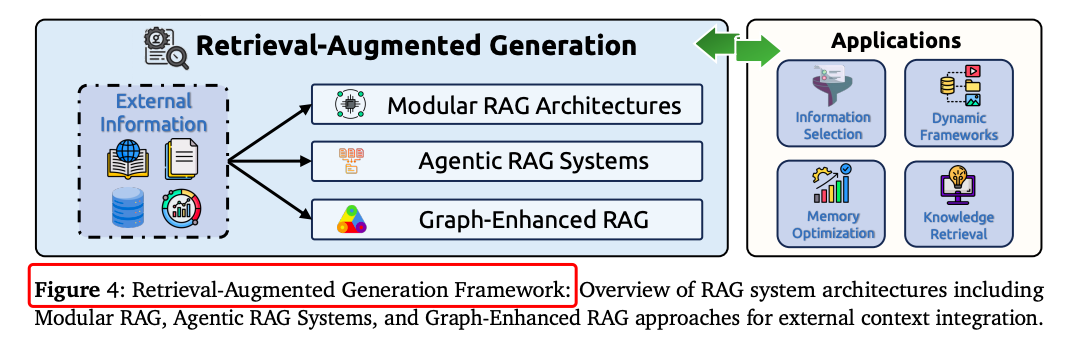
检索增强生成(RAG):通过模块化架构、智能体化和图增强架构实现动态知识注入。例如,知识图谱增强的RAG在问答任务中显著提升了性能。
-
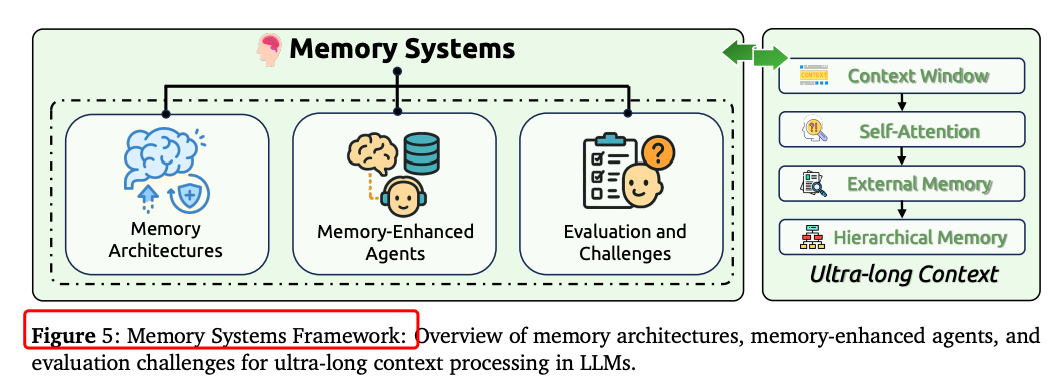
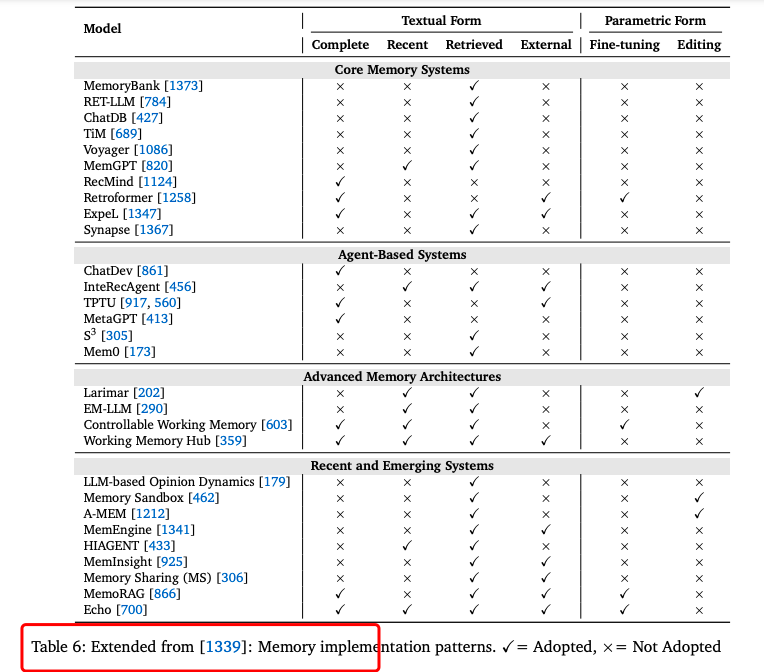
内存系统:模仿人类认知能力,实现持久信息保留。例如,LongMem的时间衰减机制有效处理长期依赖。
-
工具集成推理:通过定义函数调用规范,实现推理规划-工具调用-结果整合的闭环,支持数字与物理环境交互。
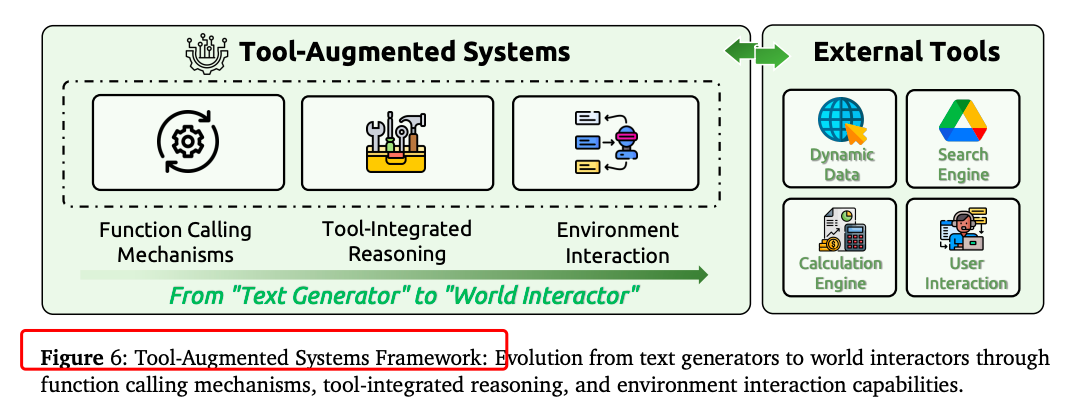
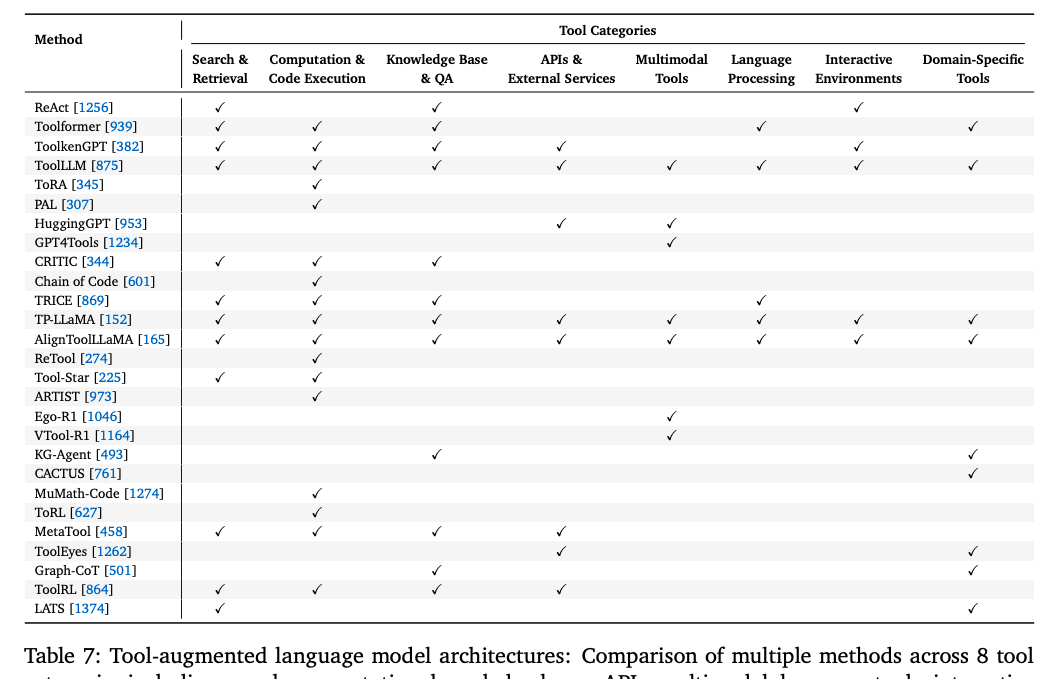
-
多智能体系统:设计通信协议、编排机制和协调策略,实现复杂目标。例如,多智能体系统在代码生成等任务上显著提升了性能。
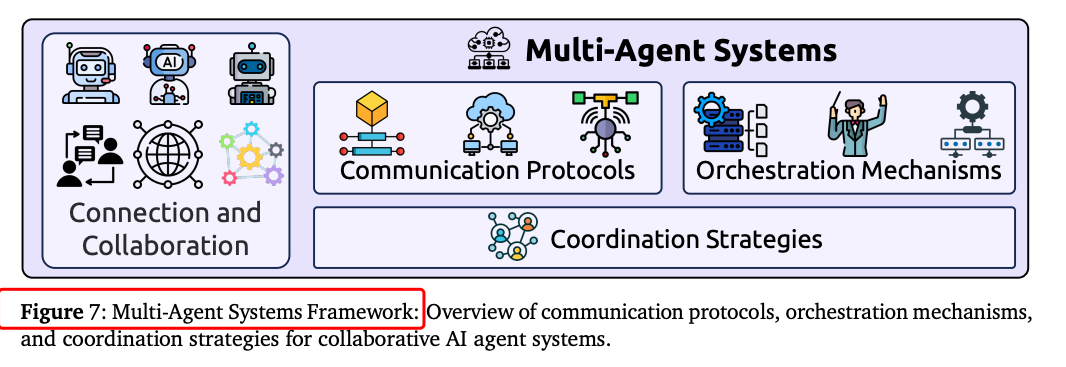
三、实验结果与性能提升
-
长上下文处理:LongNet和StreamingLLM等技术显著提升了长序列处理能力。
-
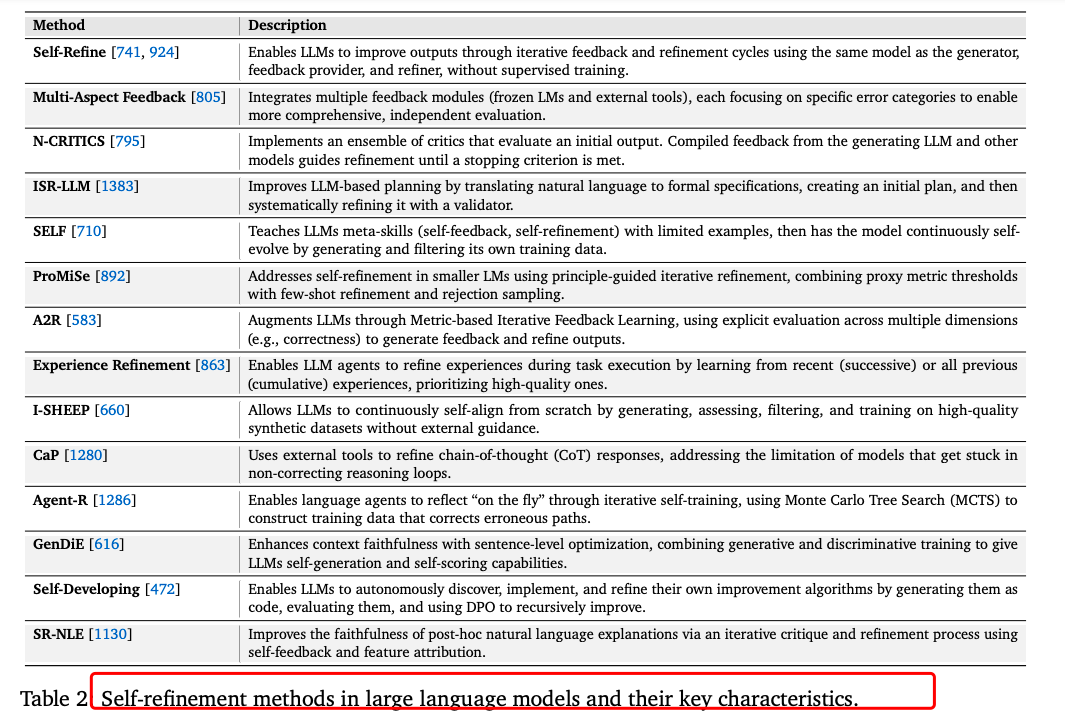
自我优化方法:如Self-Refine使GPT-4性能提升约20%,思维树(ToT)显著提高了任务成功率。
-
RAG系统:在问答任务中,知识图谱增强的RAG显著提升了性能。
-
内存系统:MemGPT和LongMem等技术实现了超长对话和长期依赖的有效处理。
-
上下文压缩:LLMLingua等技术实现了高效压缩,保持任务性能。
-
多智能体协作:多智能体系统在代码生成等任务上显著提升了性能。
https://arxiv.org/abs/2507.13334A Survey of Context Engineering for Large Language Models
(文:PaperAgent)