
“ RAG系统中,高质量的文档处理才是RAG系统的核心。”
手上有一个基于自然语言对话的系统,其功能就是根据提供的文档,能通过自然语言对话的方式去询问需要的文档和资料;其本质上来说就是一个RAG系统。
在之前一直强调说,RAG开发是一个入门五分钟,但要做好可能要五个月,甚至更久的一项技术;在之前对这句话还没有特别深刻的体会,但经过这个项目算是深有体会了。
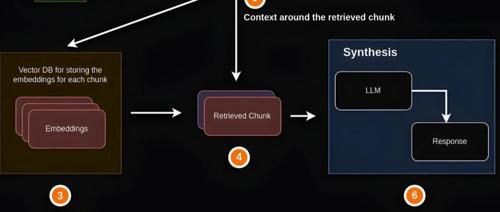
RAG功能优化
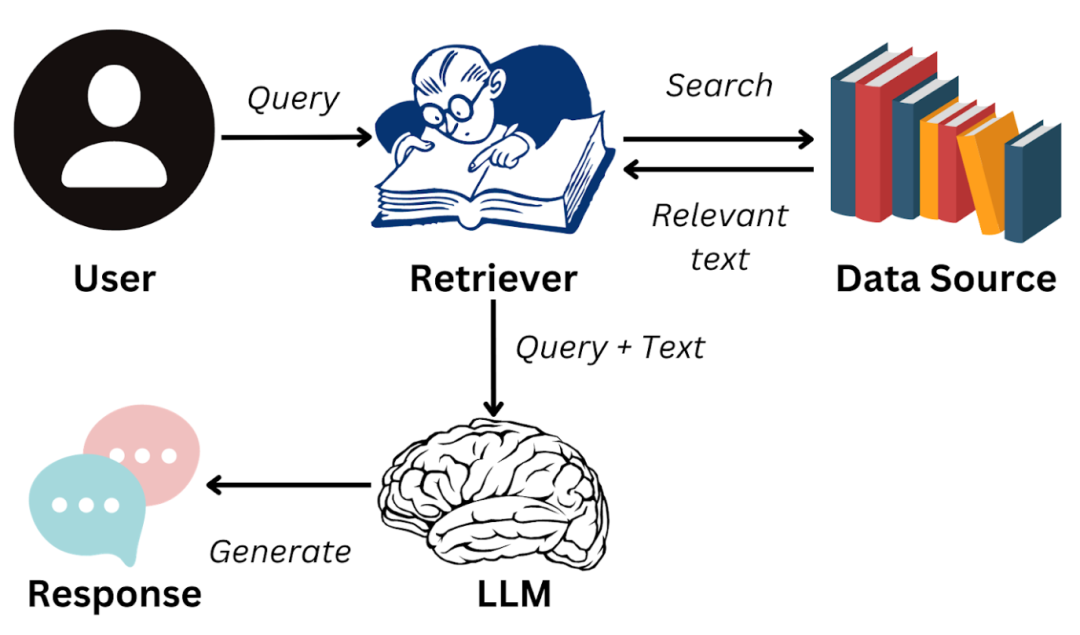
刚开始做这个项目的时候,觉得技术比较简单;就是把文档切片,然后通过embedding模型向量化之后,保存到向量数据库中;然后使用同样的embedding模型对用户问题进行向量化,然后使用向量计算的方式,匹配相似度,再通过rerank重排序的方式检索相关的文档。
这一套操作下来,虽然完整的实现了一个RAG功能;但这仅仅只是把这个RAG系统给做了出来,还远远算不上做好。
为什么这么说?
原因就在于经过实际测试之后发现,RAG系统的整体效果还不太满意,有些问题文档里明明有,但召回的时候却召不回来。最后经过检查发现,原因基本上都出在文档处理上。
为什么会出现这种情况?
其实从实际的开发经验来看,目前大模型应用,模型的能力已经可以说是很强了;甚至远远超过我们很多人的预料。但很多时候问题就出在我们的数据处理上,针对RAG系统来说就是文档的前期处理上。
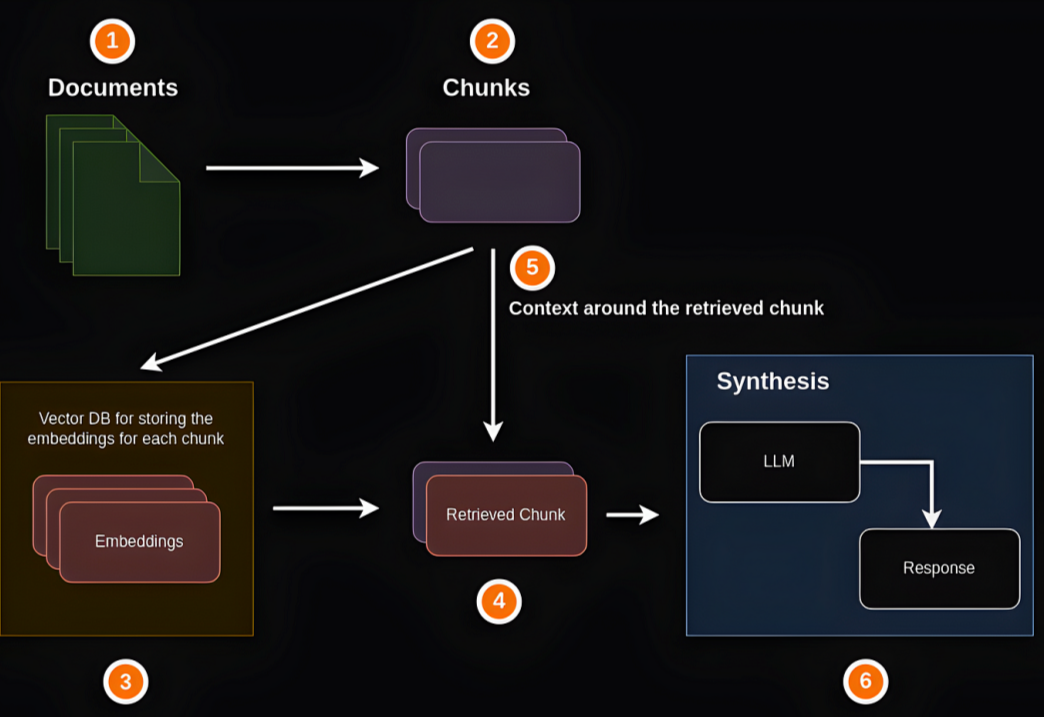
所以,只是把整个RAG流程跑通,这仅仅只是第一步;而比较难得是怎么把RAG做好,有更快更准确的召回效率。
以个人遇到的实际问题为例,针对一个word文档,由于其处理起来比较复杂,因此我们一般采用两种方式进行处理;一种是通过OCR技术,把word文档转换成纯文本的markdown文档,如果word文档中存在大量的图片或架构数据,那么文档的处理质量相对会比较差。
还一种方式更粗暴,更简单,直接找一个开源的文档处理工具,把word文档转换成markdown文档;其图片或架构图数据直接给丢掉。
之后,再整体针对markdown文档进行处理;比如说根据markdown文档标题进行分段,然后每段都带上其上层标题的内容,以此来增加检索召回的准确度。

虽然这种通用的处理方式能够快速处理文档,但由于文档拆分的不够详细,就导致部分内容无法召回。
比如说,一个段落大概在三百到五百个中文字符,但用户的问题可能只有几个字;这样对召回精度来说是远远不够的;但如果拆分的太细,也会导致召回的数据条数太多,最后会被重排序或其它过滤方式给过滤掉。
而且,从实际的开发角度来说,设计向量库表结构时,只会把需要相似度检索的数据放到一两个或两三个字段中,然后根据这些字段进行检索;但实际开发中,我们的文档数据并不都是标准的word或markdown格式,也可能是excel,csv等结构化数据,亦或者是其它类型的数据。
这时怎么把这些数据使用合理的数据格式或结构进行存储,也是一个需要考虑的问题;原因就在于你不可能把不同的数据格式单独建一个字段进行保存,或者单独建一个向量表保存,原因就在于太麻烦,数据太分散。
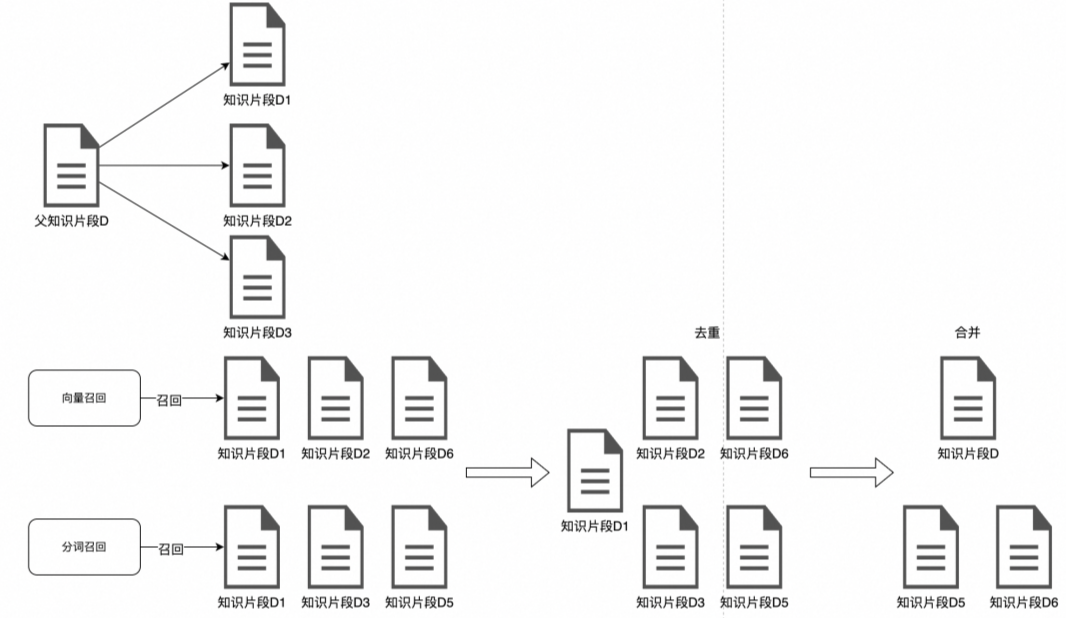
所以,我们目前的处理方式是不论是word文档,还是excel文档,都把它转化成markdown格式进行存储和向量化;然后再通过相似度检索的方式进行匹配。
总之,在RAG系统中文档处理是重中之重,而且需要根据不同的文档格式和内容进行不同的处理;只有这样才能不断提升RAG的检索准确性,否则RAG就失去了应有的意义。
(文:AI探索时代)