

Voxtral是由Mistral AI开发的一款开源AI音频模型,能够为商业应用提供生产环境开箱即用的语音理解功能,具有极高的性价比。它包含两个版本,分别是用于生产规模应用的24B参数版本和用于本地和边缘部署的3B参数的“Mini”版本,均基于Apache 2.0许可证发布,可从Hugging Face下载并在本地运行,也可通过API集成到应用程序中。

一、核心功能
(一)双版本模型
提供两种尺寸的模型,一个24B参数的版本用于大规模生产应用,一个3B参数的“Mini”版本用于本地和边缘计算部署。
(二)开源和API访问
两种模型都遵循Apache 2.0开源许可证,可以从Hugging Face下载。同时,Mistral AI也提供了API接口,开发者可以通过简单的API调用将Voxtral的语音智能集成到自己的应用中。
(三)高性价比
API定价从每分钟0.001美元起,旨在让高质量的语音转录和理解能够被大规模应用。
(四)长音频处理
拥有32k令牌的上下文长度,能够处理长达30分钟的音频进行转录,或长达40分钟的音频进行理解。
(五)内置问答和摘要功能
无需串联多个模型,可以直接对音频内容提问或生成结构化摘要。
(六)多语言支持
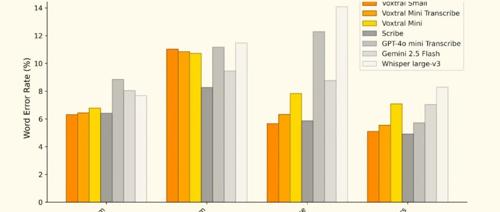
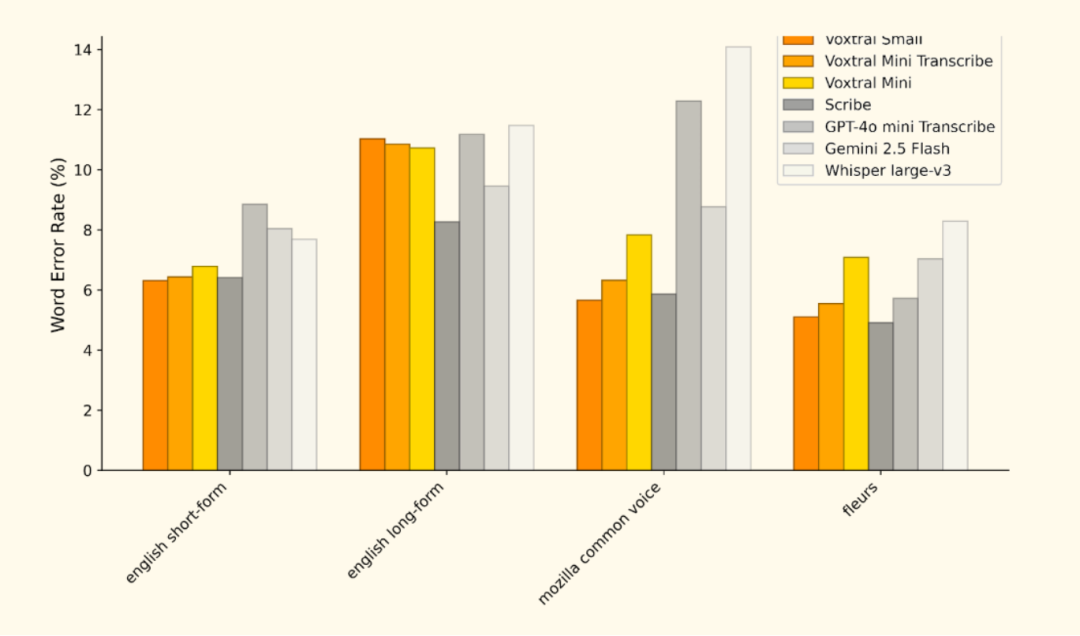
经FLEURS和Mozilla Common Voice等多个基准测试验证,Voxtral在多种语言上表现出色,尤其在欧洲语言中达到了顶尖水平,支持包括英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语和印地语等。
(七)本地部署与定制
为企业客户提供本地部署选项,以及针对特定领域进行微调和扩展功能(如说话人识别、情绪检测和对话分离)的方案。
(八)保留文本处理能力
Voxtral保留了其语言模型骨干(Mistral Small 3.1)的文本处理能力,可以无缝地在语音和语言任务之间切换。
二、技术原理
(一)基于深度学习的语音识别
Voxtral采用先进的深度学习技术,如Transformer架构,对语音信号进行处理和理解。模型通过大量语音数据训练,能够准确识别和转录语音内容。Transformer架构在处理序列数据方面表现出色,使其能够捕捉语音中的复杂模式和依赖关系。
(二)多语言模型架构
Voxtral基于共享的模型架构和多语言训练数据,实现对不同语言的自动识别和理解。这种多语言模型架构不仅提高了模型的泛化能力,还降低了开发和维护成本。
(三)上下文感知能力
Voxtral利用长文本上下文(32k token上下文长度),能够理解语音内容的语义和逻辑关系,提供更准确的转录和理解结果。这种上下文感知能力对于处理长篇对话、会议记录等场景至关重要。
(四)端到端的语音理解
Voxtral将语音识别(ASR)和自然语言理解(NLU)结合在一个模型中,直接从语音输入生成文本、回答问题或执行相关操作,减少传统系统中多步骤处理的复杂性和错误率。
三、应用场景
(一)客户服务自动化
转录客户服务电话或语音留言,并自动生成摘要或工单,提高客服响应速度和效率。
(二)内容创作与媒体
快速将采访、播客或会议的音频内容转录为文字稿,方便记者、编辑和内容创作者进行后期处理和内容分发。
(三)会议记录与分析
实时转录会议内容,并能根据指令生成会议纪要、提取关键决策点和待办事项。
(四)边缘计算与物联网设备
在智能家居、车载系统或工业物联网设备上部署Voxtral Mini模型,实现本地化的语音控制和交互,无需依赖云端连接。
(五)多语言内容处理
处理和分析来自不同国家和地区的音频数据,例如在国际市场研究中分析多语言的用户反馈。
四、快速使用
(一)通过API快速集成
Voxtral Mini 3B 提供了强大的语音转录和理解能力,可以通过 API 快速集成到现有应用中。以下是具体步骤:
1. 获取API密钥
首先,需要在Mistral AI 的官方平台注册并获取 API 密钥。
2. 安装依赖
安装必要的Python 库,例如 `mistral_common` 和 `openai`:
pip install --upgrade mistral_common openai3. 发起API请求
使用以下代码示例来调用Voxtral Mini 3B 的 API:
-
语音转录:
from mistral_common.protocol.transcription.request import TranscriptionRequestfrom mistral_common.protocol.instruct.messages import RawAudiofrom mistral_common.audio import Audiofrom huggingface_hub import hf_hub_downloadfrom openai import OpenAI# 替换为你的API密钥openai_api_key = "EMPTY"openai_api_base = "http://<your-server-host>:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)models = client.models.list()model = models.data[0].id# 下载音频文件audio_file = hf_hub_download("patrickvonplaten/audio_samples", "obama.mp3", repo_type="dataset")audio = Audio.from_file(audio_file, strict=False)raw_audio = RawAudio.from_audio(audio)req = TranscriptionRequest(model=model, audio=raw_audio, language="en", temperature=0.0).to_openai(exclude=("top_p", "seed"))response = client.audio.transcriptions.create(**req)print(response)
-
语音理解:
from mistral_common.protocol.instruct.messages import TextChunk, AudioChunk, UserMessage, AssistantMessage, RawAudiofrom mistral_common.audio import Audiofrom huggingface_hub import hf_hub_downloadfrom openai import OpenAI# 替换为你的API密钥openai_api_key = "EMPTY"openai_api_base = "http://<your-server-host>:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)models = client.models.list()model = models.data[0].id# 下载音频文件obama_file = hf_hub_download("patrickvonplaten/audio_samples", "obama.mp3", repo_type="dataset")bcn_file = hf_hub_download("patrickvonplaten/audio_samples", "bcn_weather.mp3", repo_type="dataset")def file_to_chunk(file: str) -> AudioChunk:audio = Audio.from_file(file, strict=False)return AudioChunk.from_audio(audio)text_chunk = TextChunk(text="Which speaker is more inspiring? Why? How are they different from each other?")user_msg = UserMessage(content=[file_to_chunk(obama_file), file_to_chunk(bcn_file), text_chunk]).to_openai()print(30 * "=" + "USER 1" + 30 * "=")print(text_chunk.text)print("\n\n")response = client.chat.completions.create(model=model,messages=[user_msg],temperature=0.2,top_p=0.95,)content = response.choices[0].message.contentprint(30 * "=" + "BOT 1" + 30 * "=")print(content)print("\n\n")
(二)本地部署
如果需要在本地运行Voxtral Mini 3B,可以按照以下步骤操作:
1. 安装依赖
安装`vllm` 和相关依赖:
uv pip install -U "vllm" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly2. 启动服务
启动本地服务器:
vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral3. 客户端调用
使用客户端代码调用本地服务,参考上述API 请求示例。
(三)使用vLLM(推荐)
vLLM 是一个高性能的推理框架,推荐用于部署 Voxtral Mini 3B。以下是使用 vLLM 的步骤:
1. 安装vLLM
安装vLLM 和相关依赖:
uv pip install -U "vllm" --torch-backend=auto --extra-index-url https://wheels.vllm.ai/nightly2. 测试本地环境
克隆vLLM 仓库并运行测试脚本:
git clone https://github.com/vllm-project/vllm && cd vllmpython examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtral
3. 启动服务
启动vLLM 服务:
vllm serve mistralai/Voxtral-Mini-3B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral4. 客户端调用
使用客户端代码调用vLLM 服务,参考上述 API 请求示例。
项目地址
Voxtral官方文档:https://mistral.ai/
Voxtral模型下载:https://huggingface.co/mistralai/voxtral-24b
(文:小兵的AI视界)