

OpenAI昨天宣布内部实验模型在内部的评估当中,取得了IMO2025金牌成绩,6道题答对了5道题,OpenAI首席研究Mark Chen分享了细节,OpenAI此次内部实验模型用通俗易懂的英语思考,编写证明——不需要使用lean这种数学编程语言,也不是专门训练数学证明器,而是通用的LLM,也就是模型具有广义的推理能力
另外实验模型是在IMO2025举办之前锁定的,所以模型没有提前获知试题,这样测试的是模型真实能力
对于OpenAI这一宣称,陶哲轩回应来了
陶哲轩(Terence Tao)呼吁公众和学界对AI在竞赛中的表现保持审慎和批判性的态度。他强调,评估AI能力不能只看最终结果,其背后的测试方法论至关重要

陶神的观点主要为:
AI的能力不是一个孤立的数字
以IMO为例:改变规则将对得奖结果影响巨大
没有统一标准,就无法公平比较
陶神的态度是:
“对于任何未在竞赛前公开其测试方法的、自我报告的AI竞赛成绩,我将不予置评。”
以下是陶哲轩回复全文:
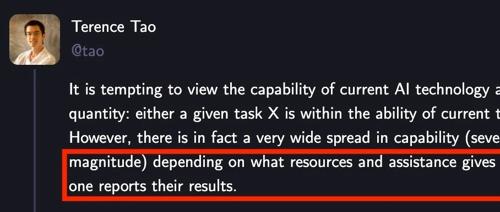
我们很容易将当前AI技术的能力看作一个单一的量:即,一项给定的任务X,要么在当前工具的能力范围之内,要么就不在。然而,事实上AI的能力谱系非常宽广(可能相差数个数量级),这取决于我们给工具提供了何种资源与协助,以及我们如何呈现其结果。
我们可以用一个关于人类的比喻来阐释这一点。我将以最近结束的国际数学奥林匹克(IMO)为例。其竞赛形式是:每个国家派出一支由六名人类选手(高中生)组成的队伍,由一位领队(通常是职业数学家)带领。在为期两天的赛程中,每位选手每天有四个半小时的时间,仅用纸和笔来解决三道高难度数学问题。在此期间,选手之间(或与领队)不允许有任何交流,但选手可以向监考人员询问有关问题措辞的澄清。在评分过程中,领队会在IMO评审团面前为学生争取权益,但并不直接参与IMO考试本身。
对于一名高中生而言,能在IMO竞赛中取得优异成绩以获得奖牌,尤其是金牌或满分,被广泛认为是一项极具含金量的数学成就衡量标准;今年,金牌的分数线是35/42,这相当于完美解答了六个问题中的五个。即便是只完美解答一个问题,也能获得“荣誉提名”。
但试想一下,如果我们通过各种方式改变竞赛形式,这项奥赛的难度会发生什么变化:
给予学生数天时间来完成每道题,而不是在四个半小时内解决三道题。(为了让这个比喻更进一步,我们可以设想一个科幻场景:学生名义上仍只有四个半小时,但领队将他们置于某种昂贵且耗能巨大的时间加速机器中,使学生在这段时间里经历了数月甚至数年的思考时间。)
考试开始前,领队将问题改写成学生们觉得更容易处理的形式
领队允许学生无限制地使用计算器、计算机代数软件、形式化证明助手、教科书,或上网搜索
领队让六名队员组成一个团队,同时解决同一个问题,并可以相互沟通各自的部分进展和已知的死胡同
领队给予学生提示,引导他们走向更有利的方法;并且当有学生在某个领队明知不太可能成功的方向上花费过多时间时,领队会进行干预
团队中的六名学生都提交解法,但领队只挑选“最好”的一份提交给竞赛,而将其余的丢弃
如果团队中没有任何学生得出满意的解法,领队就干脆不提交任何答案,并悄然退出竞赛,甚至不会留下任何参赛记录
在以上每一种形式中,提交的解法在技术上仍然是由高中生们生成的,而非领队。然而,学生们在竞赛中报告的成功率可能会因这些形式上的改变而受到显著影响;一个在标准测试条件下可能连铜牌都拿不到的学生或团队,在上述某些修改过的形式下,反而可能达到金牌水平。
因此,在缺乏一个不由参赛团队自行选择的、受控的测试方法论的情况下,当我们对不同AI模型在IMO等竞赛中的表现进行比较时,或者在这些模型与人类选手之间进行比较时,我们应该对这种“苹果对苹果”式的比较保持警惕。
与此相关的是,对于任何没有在赛前披露其方法论的、自我报告的AI竞赛成绩,我将不予置评。
参考:

https://mathstodon.xyz/@tao/114881420636881657
(文:AI寒武纪)