

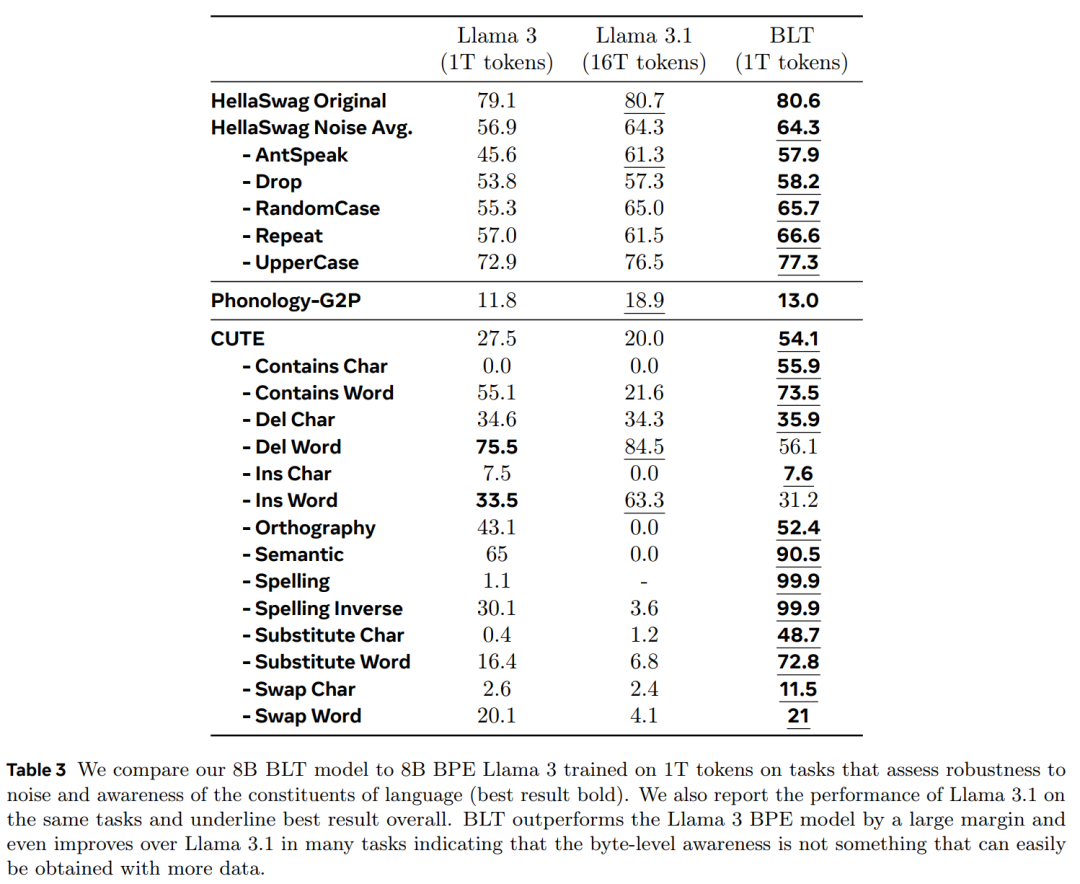
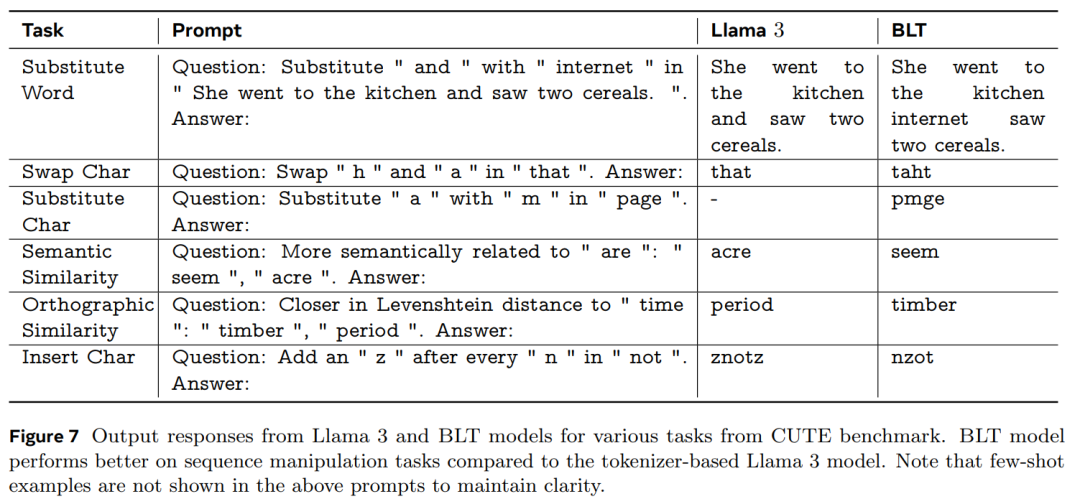
BLT 在许多基准测试中超越了基于 token 的架构。



-
提出了 BLT,这是一种字节潜在 LLM 架构,动态分配计算资源以提高 flop 效率; -
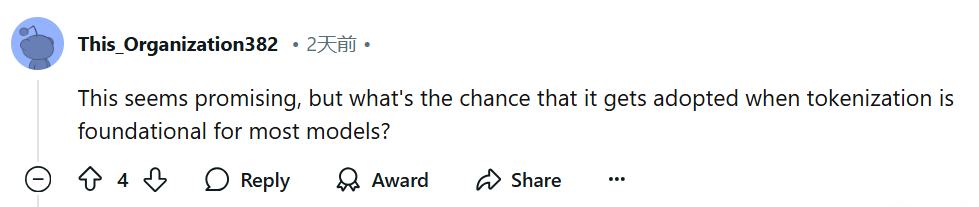
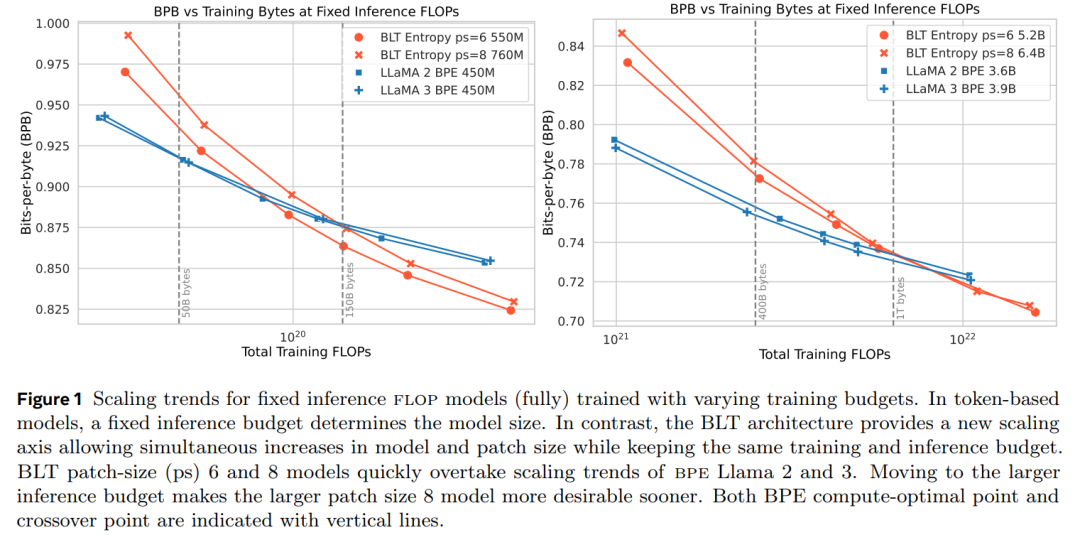
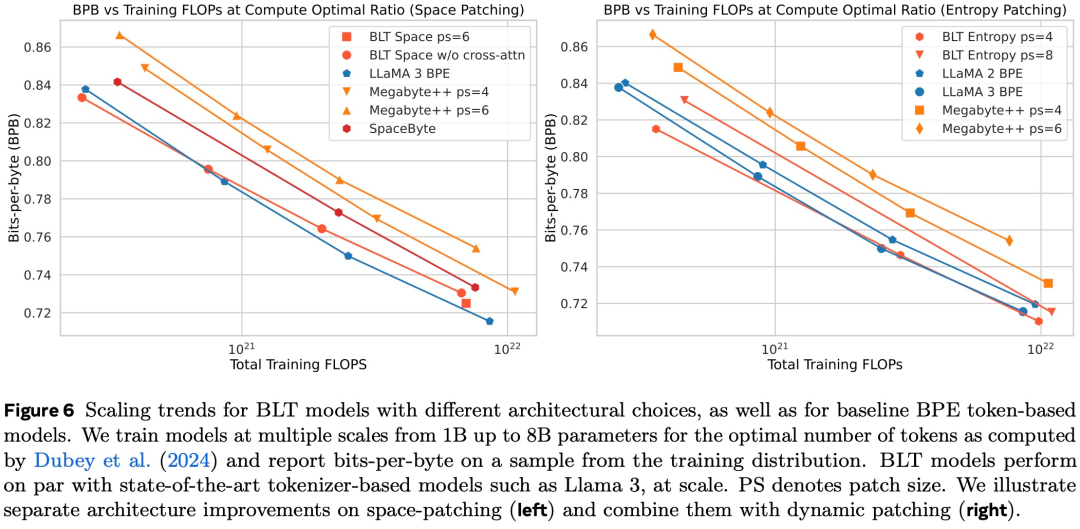
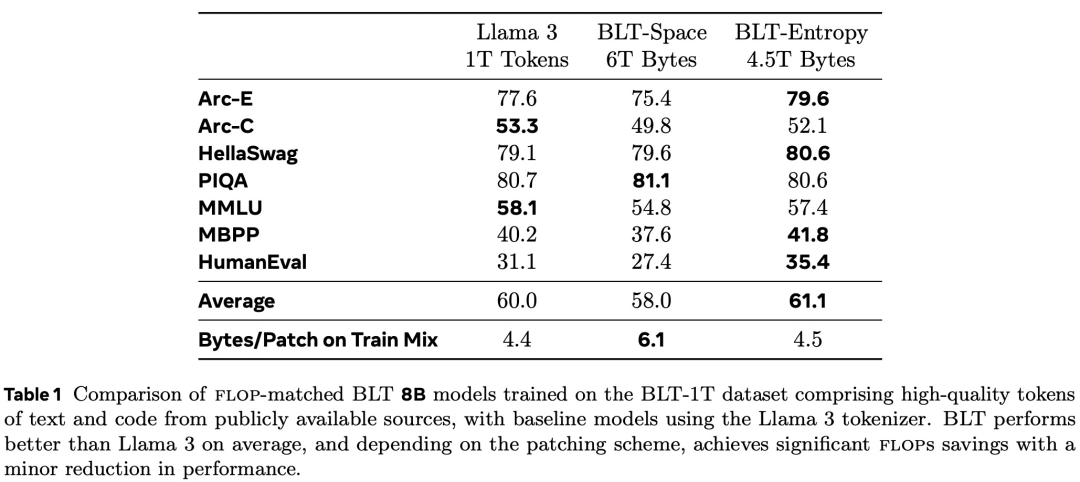
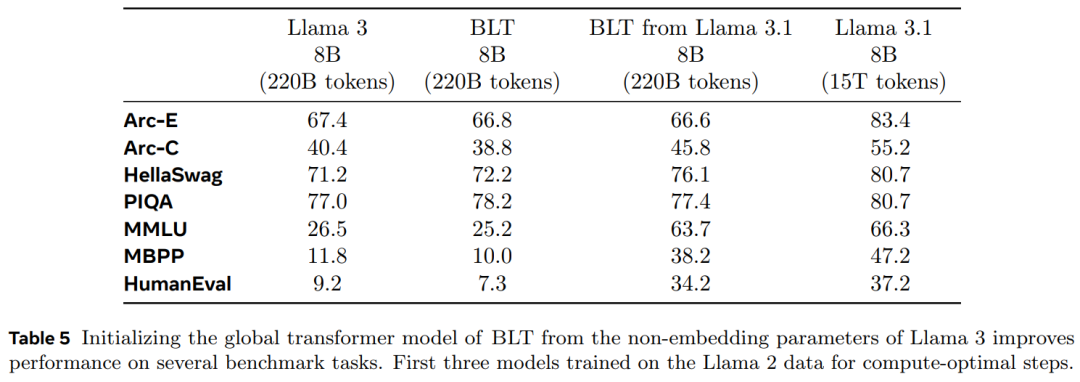
展示了在 8B(即 80 亿)参数规模下,能够实现与 Llama 3 模型相当的训练 flop 控制,同时可以通过牺牲一小部分评估指标来换取高达 50% 的 flop 效率提升; -
BLT 模型为扩展大型语言模型开启了一个新的维度,现在可以在保持固定推理预算的同时扩展模型大小。

-
论文标题:Byte Latent Transformer: Patches Scale Better Than Tokens -
论文地址:https://arxiv.org/pdf/2412.09871 -
项目地址:https://github.com/facebookresearch/blt


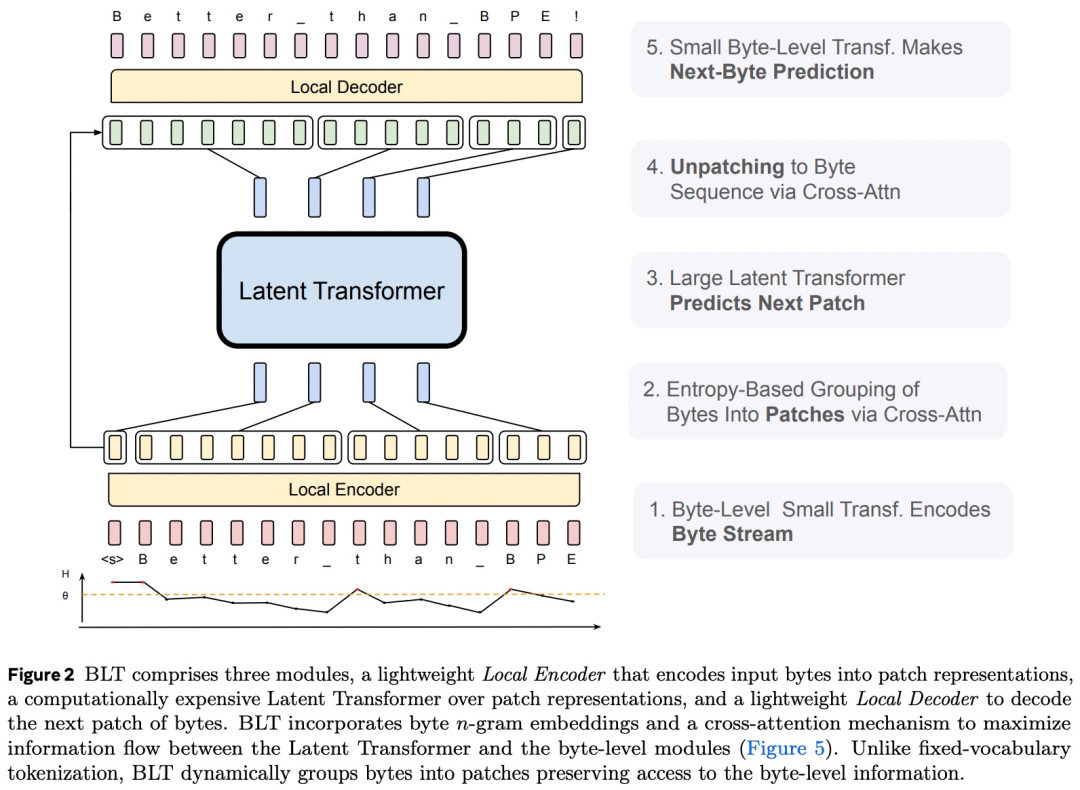
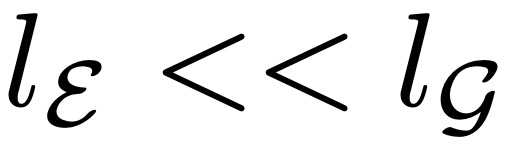 层,其主要作用是有效地将输入字节序列 b_i 映射为表达性 patch 表征 p_j。与 Transformer 架构的主要区别是在每个 Transformer 层之后添加了一个交叉注意力层,其功能是将字节表征池化为 patch 表征(图 5)。
层,其主要作用是有效地将输入字节序列 b_i 映射为表达性 patch 表征 p_j。与 Transformer 架构的主要区别是在每个 Transformer 层之后添加了一个交叉注意力层,其功能是将字节表征池化为 patch 表征(图 5)。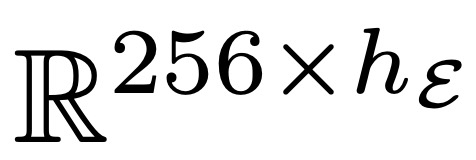 矩阵嵌入输入字节序列 b_i ,表示为 x_i 。然后,这些嵌入可以选择以散列嵌入的形式添加附加信息。然后,一系列交替的 transformer 和交叉注意力层将这些表征转换为由全局 transformer G 处理的 patch 表征 p_i。transformer 层使用局部块因果注意力掩码;每个字节都关注前面字节的固定窗口,该窗口通常可以跨越动态 patch 边界,但不能跨越文档边界。
矩阵嵌入输入字节序列 b_i ,表示为 x_i 。然后,这些嵌入可以选择以散列嵌入的形式添加附加信息。然后,一系列交替的 transformer 和交叉注意力层将这些表征转换为由全局 transformer G 处理的 patch 表征 p_i。transformer 层使用局部块因果注意力掩码;每个字节都关注前面字节的固定窗口,该窗口通常可以跨越动态 patch 边界,但不能跨越文档边界。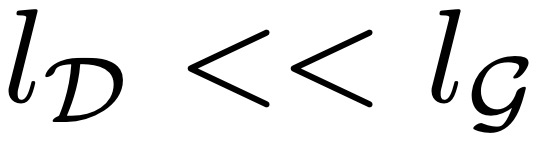 层,它将全局 patch 表征序列 o_j 解码为原始字节 y_i 。局部解码器根据先前解码的字节来预测原始字节序列,因此将局部编码器为字节序列生成的隐藏表征作为输入。它应用了一系列交叉注意力层和 transformer 层的 lD 交替层。解码器中的交叉注意力层在 transformer 层之前应用,以首先从 patch 表征创建字节表征,并且局部解码器 transformer 层对生成的字节序列进行操作。
层,它将全局 patch 表征序列 o_j 解码为原始字节 y_i 。局部解码器根据先前解码的字节来预测原始字节序列,因此将局部编码器为字节序列生成的隐藏表征作为输入。它应用了一系列交叉注意力层和 transformer 层的 lD 交替层。解码器中的交叉注意力层在 transformer 层之前应用,以首先从 patch 表征创建字节表征,并且局部解码器 transformer 层对生成的字节序列进行操作。-
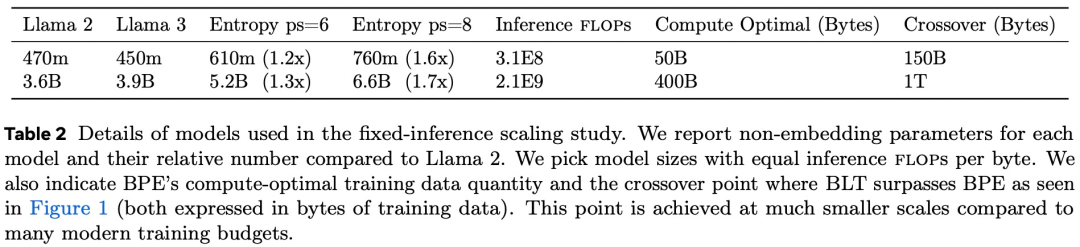
比较计算最优训练方案的趋势; -
在大量训练上训练匹配的 8B 模型数据并评估下游任务; -
测量推理成本控制设置中的扩展趋势。

(文:机器之心)