

百度ERNIE 4.5
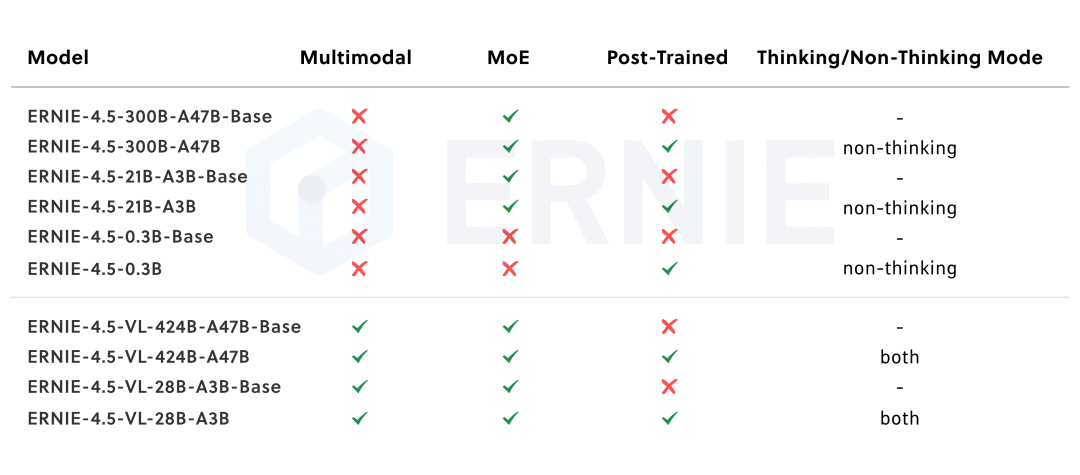
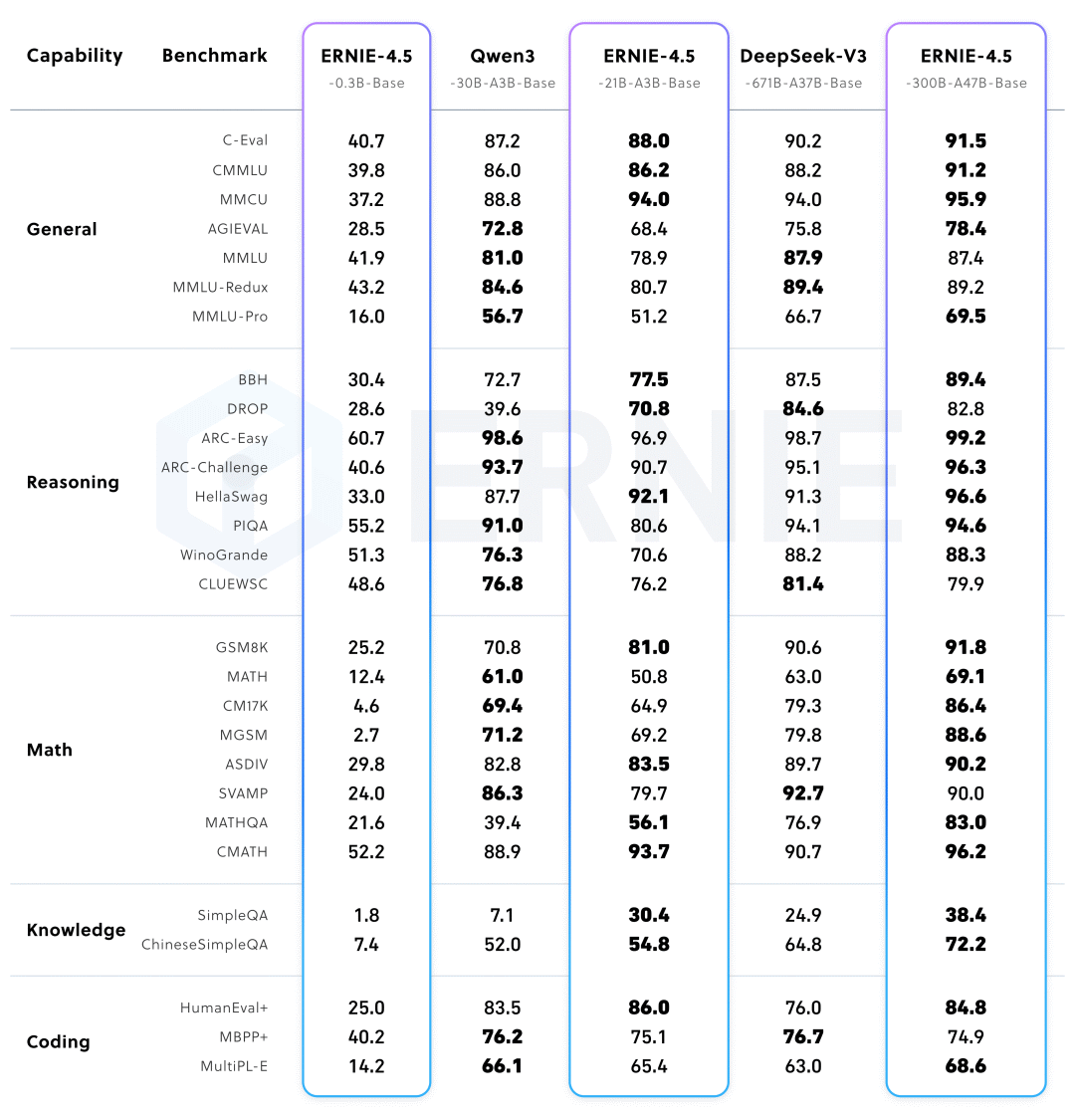
文心4.5系列开源模型共10款,涵盖了激活参数规模分别为47B和3B的混合专家(MoE)模型(最大的模型总参数量为424B),以及0.3B的稠密参数模型。对 MoE 架构,提出了一种创新性的多模态异构模型结构,通过跨模态参数共享机制实现模态间知识融合,同时为各单一模态保留专用参数空间。
https://hf-mirror.com/collections/baidu/ernie-45-6861cd4c9be84540645f35c9https://github.com/PaddlePaddle/ERNIEhttps://ernie.baidu.com/blog/zh/posts/ernie4.5/
腾讯Hunyuan-A13B
-
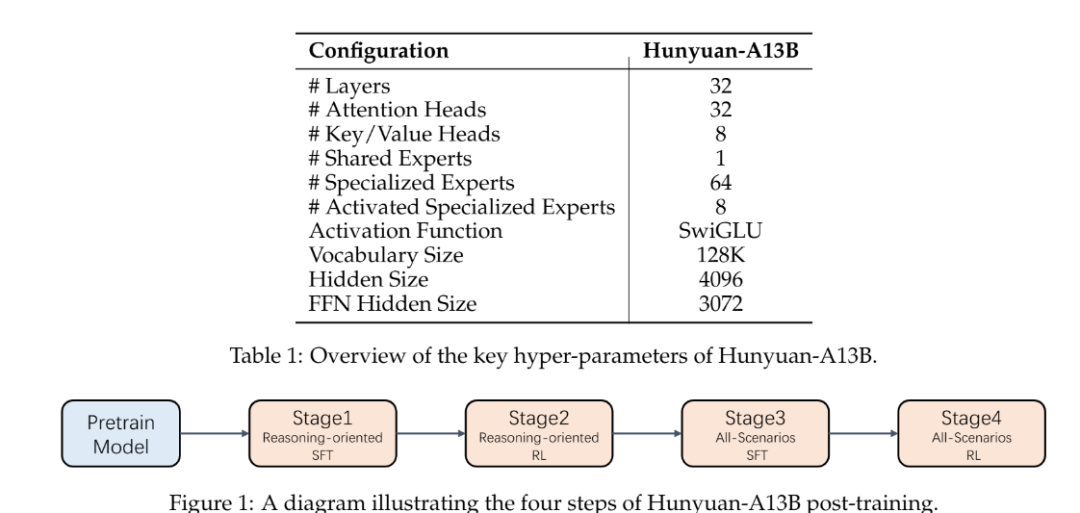
紧凑而强大:尽管只有13B活跃参数(总共80B),该模型在广泛的基准任务中提供了有竞争力的性能,与更大的模型相媲美。 -
混合推理支持:支持快速和慢速思考模式,用户可以根据自己的需求灵活选择。 -
超长上下文理解:原生支持256K上下文窗口,在长文本任务上保持稳定的性能。 -
增强的Agent能力:针对Agent任务进行了优化,在BFCL-v3、τ-Bench和C3-Bench等基准测试中取得了领先结果。 -
高效的推理:使用分组查询注意力(GQA)并支持多种量化格式,实现了高效的推理。
体验demo: //hunyuan.tencent.com/https://github.com/Tencent-Hunyuan/Hunyuan-A13B/blob/main/report/Hunyuan_A13B_Technical_Report.pdfhttps://hf-mirror.com/tencent/Hunyuan-A13B-Instruct
盘古 Pro MoE (72B-A16B)
-
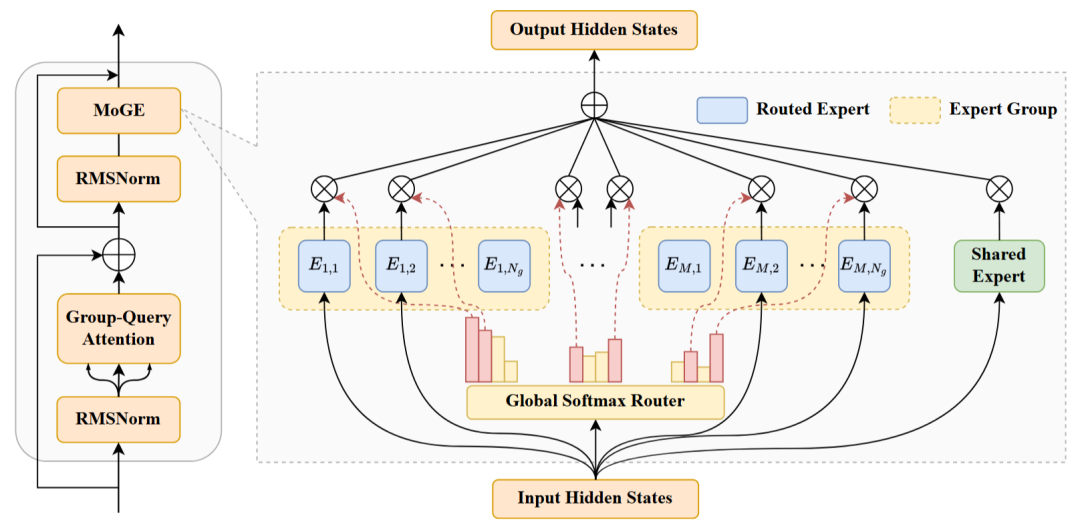
词表大小:153376 -
层数: 48 -
MoGE 配置:4 个共享专家,64 个路由专家分 8 组、每组激活 1 个专家 -
训练阶段:预训练和后训练 -
预训练预料:15T
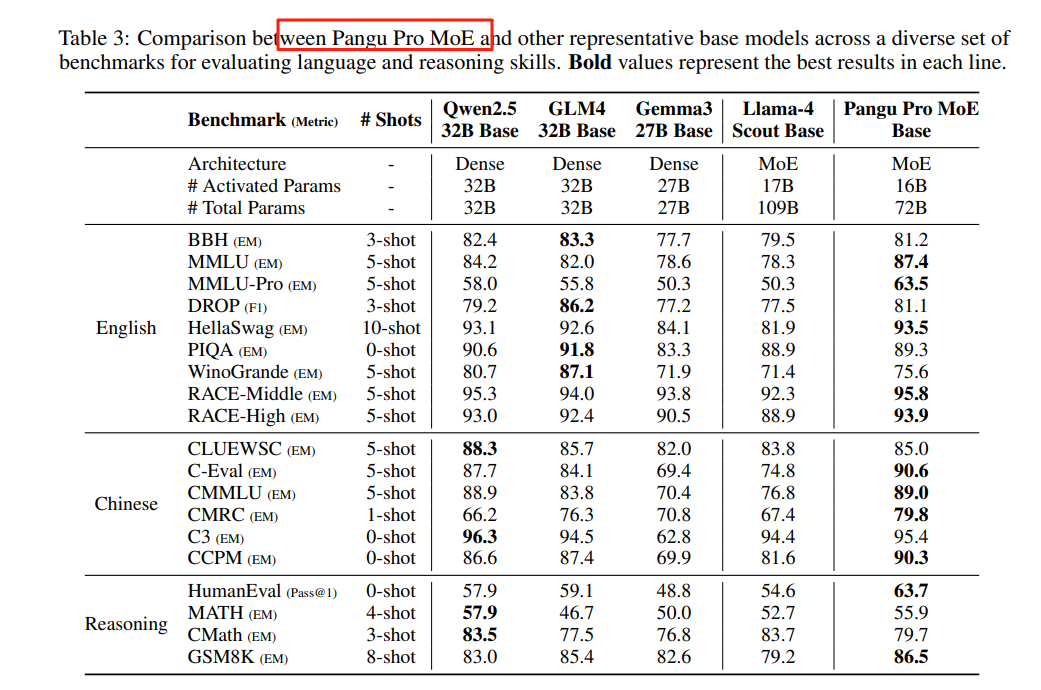
https://gitcode.com/ascend-tribe/pangu-pro-moe-modelhttps://arxiv.org/pdf/2505.21411
(文:PaperAgent)