



论文标题
DeepCritic: Deliberate Critique with Large Language Models
论文链接:
https://arxiv.org/abs/2505.00662
代码链接:
https://github.com/RUCBM/DeepCritic
作者团队:
中国人民大学高瓴人工智能学院、北京交通大学计算机科学与技术学院

问题背景
大语言模型(LLM)通过大规模地学习人类数据并从人类监督反馈中不断进化,在许多任务上展现出卓越的性能。然而,随着模型智能的不断增强,依赖人工监督的方式也面临着越来越高饿成本和难度。如何以更高效、可扩展的方式对日益进化的模型进行监督,成为非常重要且亟待解决的关键问题。
一种具有潜力的解决路径是利用大语言模型自身作为批判家(LLM Critics)对模型的生成内容进行评判和反馈。LLM critics 通过生成批评意见,帮助改进模型输出,从而有望替代人工反馈工作,实现 LLM 自动监督与持续优化。
但是一些工作发现,现有 LLM critics 在处理例如数学推理等复杂领域时,表现仍较为落后。
作者分析了其中原因,发现现有 LLM critics 在批判时缺乏批判性思维,常常只会按照原始推理步骤中的逻辑进行简单的重复验证,而非以质疑的角度进行批判和深入分析,这使得其经常受到原始推理步骤中的错误误导而不能发现问题(见图 1)。
这个缺陷导致两个核心问题:一是判断结果准确率低下;二是提供的批判信息缺乏指导性,难以为生成模型提供有效的改正和优化方向。

▲ 图1. 现有的 LLM critics 只能生成粗浅、表面的批判,导致正确率低下。本工作训练的批判模型能够结合迭代式评判、多角度验证以及元批判等机制,在做出判断前进行深思熟虑的推理,生成详细的反馈和准确的判断。
本工作旨在解决当前 LLM critics 在数学推理任务上生成的批判过度表面、肤浅的问题,提出了 DeepCritic 框架,通过监督微调(SFT)和强化学习(RL)两阶段训练得到深思熟虑的 LLM critics。
基于 Qwen2.5-7B-Instruct 训练得到的 DeepCritic-7B-RL 模型在不同数学错误识别基准上显著超过了当前的 LLM critics,包括 GPT-4o,Qwen2.5-72B-Instruct,和同规模的 DeepSeek-R1-Distill models。DeepCritic-7B-RL 还可以分别作为 verifier 和 critic 进一步提升生成模型的 test-time scaling 结果。

两阶段训练增强 LLM 批判能力
2.1 监督微调教会 LLM 深思熟虑地批判
在第一阶段,为了教会当前 LLM 深度批判的行为和格式,作者首先从头构造了长思维链形式的批判数据,进行监督微调(SFT)使 LLM 具备初步的深度批判能力。
具体地,作者提出了一种分阶段、逐步增强的批判生成流程,通过引导模型进行更深层次的思考与自我反思,提升其判断准确性与反馈质量。生成方法包括以下三个关键步骤:
初始批判生成:首先,从人工标注的 PRM800K 中选取一小部分带有人工标注步骤正确性的问题和步骤,调用大模型(Qwen2.5-72B-Instruct)依次对每一步推理过程单独批判,生成对于每一步的初始批判。
深度批判生成:然而,正如上述所示,现有大模型的直接批判往往容易流于表面,缺乏真正的批判性思维。
所以,这一步骤中给定问题,推理步骤和初始批判,再次引导模型从不同角度和不同验证方法重新评估和批判,或对初始批判本身进行重新审视,发现初始批判没有找到的问题或者初始批判本身存在的问题,形成更有深度和反思性的元批判,有效纠正初始误判。
最终批判融合和监督微调:最后,留下判断结果与人工标注一致的所有深度批判和对应的初始批判,将它们糅合成一条长思维链,形成每一步更为成熟、细致的最终批判文本。
并把针对每一步的最终批判拼接得到对于整条解答的深度批判文本,以此共构建了约 4.5K 条高质量的监督微调数据。通过对基础模型(Qwen2.5-7B-Instruct)进行监督微调,最终得到具备多轮评估、多角度验证和元批评能力的初始评论模型 DeepCritic-7B-SFT。
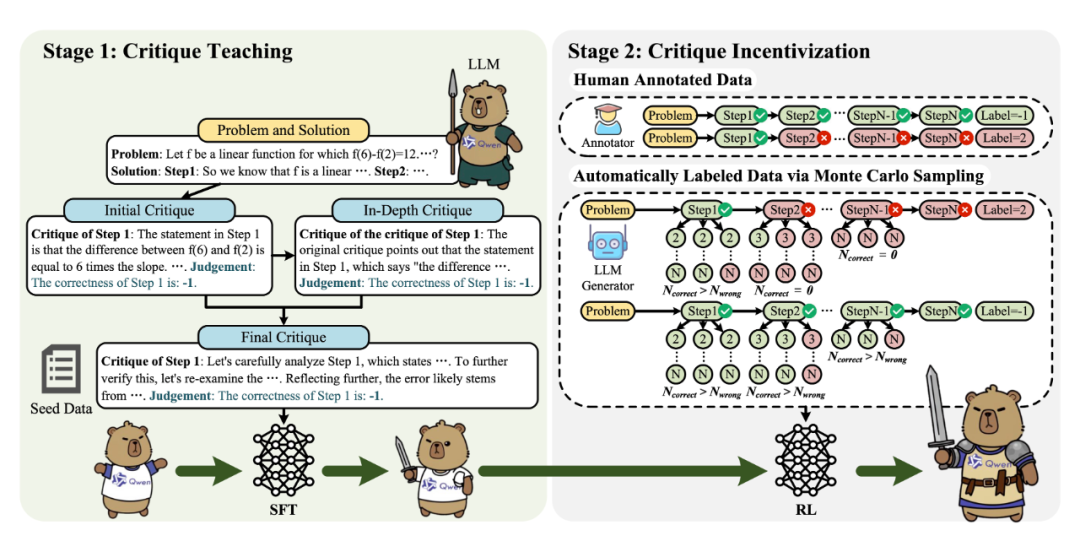
▲ 图2. 两阶段训练流程示意图
2.2 强化学习激励 LLM 深思熟虑地批判
在完成了第一阶段的有监督微调,构建出具备初步深度批判能力的模型后,第二阶段的目标是进一步激发模型的潜力,使其在评判复杂推理过程中表现得更加精准和灵活。为此,作者采用强化学习(RL)对模型进行进一步训练。
强化学习阶段的关键在于高质量数据的获取。作者分别在两种不同的数据来源设定下探索 RL 训练:
人工标注数据:直接使用已有的人工标注数据集 PRM800K,这是最理想的数据来源,具备可靠的标签信息。
自动构造数据:考虑到人工标注成本逐渐高昂、不可持续的现实,作者还采用了一个无需人工标注的数据自动构造流程。
具体来说,从 NuminaMath-CoT 中抽取部分题目,使用 Qwen2.5-1.5B/3B/7B-Instruct 为每道题生成多个解题路径,并过滤掉太简单或者太难的题目。对于剩下的解题路径,通过蒙特卡洛采样估计法,评估每一步推理的正确性:
(1)对错误解题路径中错误步骤的识别:将解答在某一步截断,并让生成器模型(Qwen2.5-7B-Instruct)从该步开始多次展开后续步骤。如果该步及其后所有推理步骤在所有展开中都错误,且该步之前的所有步骤的各自多数展开能得到正确答案,则将该步标记为第一个错误步骤。
(2)对正确解题路径的验证:对于最终答案正确的解,也应用相同的策略来检测其中是否存在错误的中间步骤,确保标签精确和样本质量。
最终将 DeepCritic-7B-SFT 模型在 40.7K PRM800K 样本上或者 14.2K 自动构建样本上分别训练得到模型 DeepCritic-7B-RL-PRM800K 和 DeepCritic-7B-RL-Numina。

实验效果
3.1 数学批判任务主实验结果
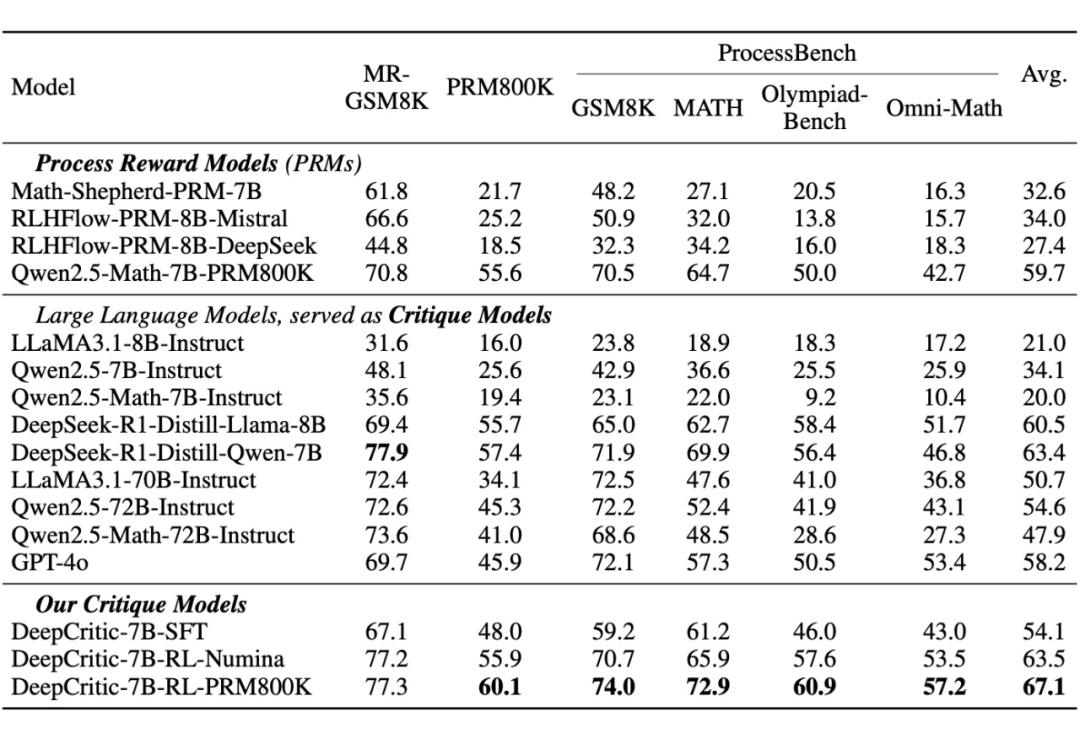
▲ 表1. 各模型在不同数学批判任务基准数据集上的表现。指标是在错误推理路径中找到第一个出错步骤的准确率和对正确路径判定成功的准确率之间的 F1 值。
作者在多个数学评估基准上系统评估了不同模型的批判能力,结果见表1。主要实验结论如下:
(1)基础指令微调模型批判能力普遍较弱,尤其是小模型;随着模型规模提升,批判能力也相应增强。
(2)DeepSeek-R1-Distill 系列模型因其数学推理能力得到显著增强,在数学批判任务中的表现也取得了提升。但该系列模型往往倾向于利用自身的解题能力来辅助判断推理步骤对错,并没有真正学会做评估和批判,因此在面对难题(如 Omni-Math)时 F1 得分仍相对较低。
(3)通过在精心构造的 4.5K 批判数据上微调后的 DeepCritic-7B-SFT 模型在平均 F1 得分上相较于基础模型 Qwen2.5-7B-Instruct 从 34.1 提升到 54.1,提升幅度达 20 个百分点。这证明构造的深思熟虑批判数据具有极高质量,也验证了“教模型进行深思熟虑的批判”这一动机的有效性。
(4)在强化学习阶段,仅使用 14.2K 条自动构造的数据,DeepCritic-7B-RL-Numina 模型的 F1 分数又提升到了 63.5,进一步说明自动构造数据是可行且有效的,有望实现 LLM 批判能力的自动化、可扩展提升。
(5)当使用高质量大规模标注数据进行强化学习后,衍生模型 DeepCritic-7B-RL-PRM800K 在 6 个评测子集中的 5 个上击败包括 GPT-4o 和同规模 DeepSeek-R1-Distill 系列在内的所有基线模型,取得最佳综合表现。
3.2 帮助生成模型在推理阶段实现更好的 Test-Time Scaling 结果
批判模型能通过扩展生成模型在测试时的计算(Test-Time Scaling),提升生成模型的效果。
一方面,批判模型可以充当验证器(verifier),判断生成模型采样出的回答是否正确。通过滤除被识别为错误的回答,可以获得更准确的 majority voting 结果,提高最终解答的准确率。
另一方面,生成模型也可以根据批判模型的反馈对潜在错误的回答进行修正,通过不断的“批评—修正”过程进一步逼近正确答案。
作者选用了两个不同规模的生成器进行实验:Qwen2.5-7B-Instruct 和 Qwen2.5-72B-Instruct,并在 MATH500 和 AIME2024-2025 两个数据集上进行评估。
作者选取了DeepCritic-7B-RL-PRM800K 作为实验对象(简写为DeepCritic-7B-RL)。基线模型为 Qwen2.5-7B-Instruct 和 DeepSeek-R1-Distill-Qwen-7B(简写为 DS-R1-Distill-Qwen-7B)。
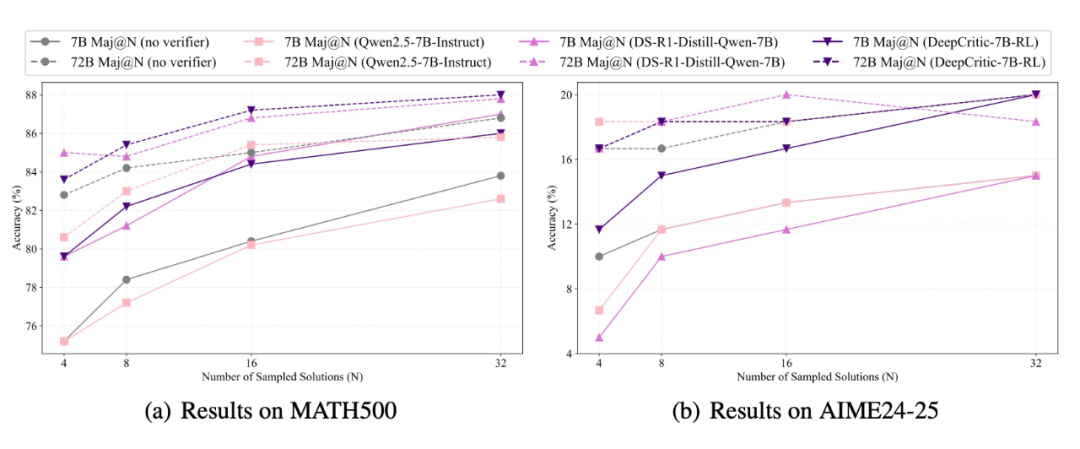
▲ 图3. 用不同模型充当 verifier 后生成模型在 MATH500 和 AIME24-25 上的 verified majority voting 结果。
批判模型充当验证器的实验结果如图 3 所示。可以观察到,当批判模型本身能力较弱时(如 Qwen2.5-7B-Instruct),将其作为验证器参与多数投票反而可能适得其反,降低整体性能。
相比之下,DeepCritic 模型在大多数采样设置中能够更有效地提升生成器的多数投票性能,带来更明显的改进。
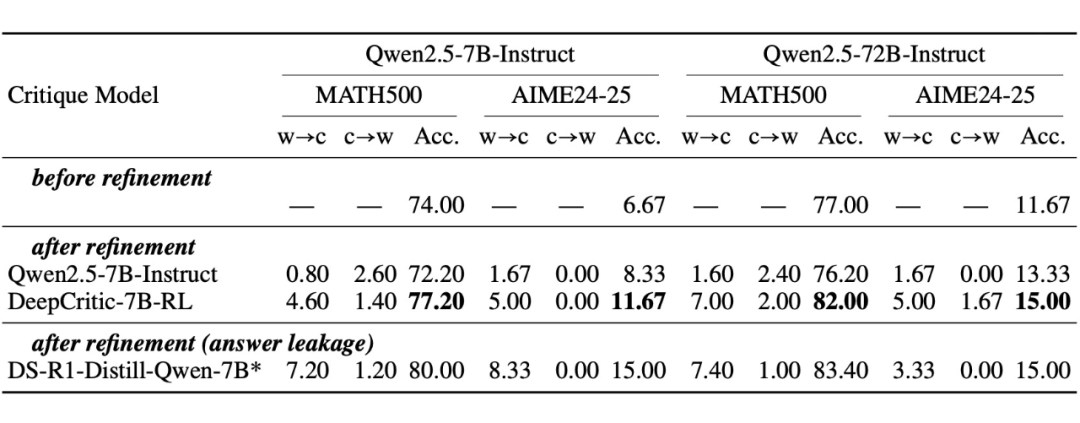
▲ 表2. 基于批判内容的修正结果。“w→c” 表示经过判断与修正后,原本错误的解答变为正确的比例;“c→w” 表示相反的情况,即原本正确的解答变为错误的比例。“Acc.” 表示在所有测试样本上的平均准确率。
生成模型根据批判模型提供的反馈做修正的结果如表 2 所示。即使强调了在识别出第一个出错步骤后就停止批判,DeepSeek-R1-Distill-Qwen-7B 仍旧经常批判到结束并给出正确答案(即其指令遵循能力较差)。
这一问题会导致生成器的修正结果受到 DS-R1-Distill-Qwen-7B 自身解题能力的较大影响,存在偏差。因此,将其结果单独列出,仅作为参考。
可以看到,DeepCritic-7B-RL 模型能够有效辅助生成器进行错误修正,通过提供更详细的反馈显著提升生成器的最终性能。值得注意的是,7B 批判模型同样能够监督并纠正 72B 生成模型的输出,展现出弱至强监督的潜力。

案例分析
以下关于 DeepCritic-7B-SFT 和 DeepCritic-7B-RL 的推理案例展示了 DeepCritic 系列模型在执行批判任务时具备了多角度验证、元批判、自我反思与纠错等关键推理和评估能力。

▲ 图4. DeepCritic-7B-SFT 的案例分析

▲ 图5. DeepCritic-7B-RL-PRM800K 的案例分析

未来展望
本工作初步验证了通过精心构造的深思熟虑批判数据进行监督微调结合强化学习,可以有效提升大语言模型在数学领域的批判与监督能力。
本工作为实现更广泛、更可靠、可扩展的AI监督机制提供新的启示。但是仍有许多值得探索的方向。例如,现阶段的研究聚焦于数学推理场景,尝试将该批判框架拓展至代码、开放领域等更多任务场景,以探索其通用性与跨领域潜力,是其中一个有趣的未来研究方向。
(文:PaperWeekly)