
近日,前OpenAI科学家 Andrej Karpathy 在社交媒体上提出了一个关于大模型学习的新颖观点:当前我们可能缺失了一种主要的学习范式。他认为,除了现有的预训练(用于获取知识)和微调(监督学习/强化学习,用于形成习惯性行为,遵从指令)之外,LLM还需要一种新的学习方式,他暂称之为“系统提示学习”(system prompt learning)。
Karpathy 的这一思考源于他对Anthropic公司Claude模型系统提示的研究。
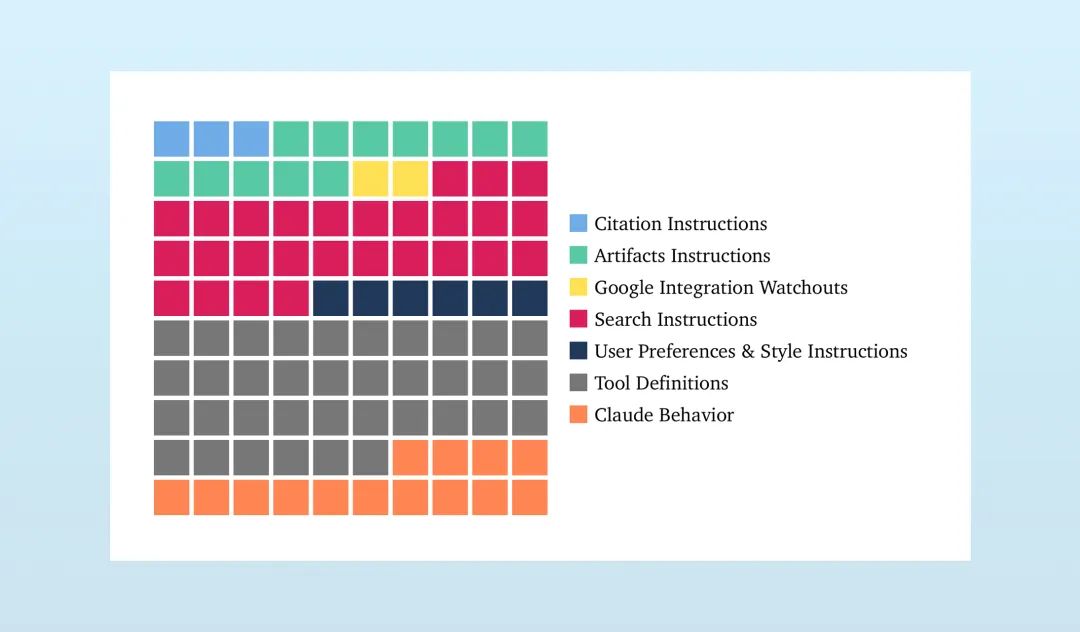
Claude的系统提示文本长达约17000词(与此相比,OpenAI o4-mini的系统提示词为2218个字),这不仅包含了模型的基本行为风格和偏好(例如,拒绝某些类型的请求),还包含了大量通用问题解决策略。例如,提示中会详细指导Claude在被要求计算词语、字母或字符时,应如何一步步地思考,明确地进行计数,只有完成这一显式计数步骤后才给出答案。这种指令的存在,部分是为了帮助模型解决诸如计算单词”strawberry”中字母’r’的数量这类对现有LLM而言并非天生擅长的任务。
Karpathy 指出,像这种具体的、针对特定问题类型的解决策略,不应该仅仅通过强化学习的方式被“烘焙”进模型的权重中,或者至少不应该是唯一或首要的方式。更不应该完全依赖于人类工程师手工编写系统提示来硬编码这些策略。他认为,这部分知识和策略的学习,应该通过一种新的“系统提示学习”范式来完成。
他将这种缺失的学习范式比作人类的学习过程——遇到问题,想出解决方案,然后以一种相当明确的方式“记住”它,以便下次遇到类似问题时应用。这更像是在给自己记笔记,类似于用户记忆功能,但并非存储用户相关的随机事实,而是存储通用或全局的问题解决知识和策略。
Karpathy 用了一个生动的比喻来形容当前的LLM:“它们就像电影《记忆碎片》(Memento)里的主角,只是我们还没有给它们配备自己的记事本。”他认为,“系统提示学习”正像是为LLM提供一个动态的“记事本”或“便笺簿”,让它们能够自主地学习和记录解决问题的策略。
那么,这种跳脱于参数改变、更像“给自己记笔记”的“系统提示学习”具体是如何发生的呢?Karpathy 本人也坦诚,这其中仍有许多细节尚待解决(例如,这种“编辑”具体如何运作?学习系统本身是否也应被学习?如何将显式知识逐步转移到模型的习惯性权重中?)。但他提出的核心概念是,这种学习过程不再仅仅是调整模型的数值权重(梯度下降),而是关于学习如何修改或生成指导模型行为的显式文本指令、策略或规则。实际上,有研究表明,上下文学习生效的原理就是在影响梯度:
Dai 等人的论文【Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers】探讨了这一问题的答案,他们在论文中探讨了在prompt中提供示例与使用相同示例进行微调之间的数学联系。作者证明,提示示例会产生元梯度(meta-gradients),这些元梯度会在推理时的前向传播过程中反映出来。而在微调时,示例实际上会产生真正的梯度,用于更新权重。因此,In-Context Learning能取得与微调类似的效果。 公众号:AI工程化
一文探秘LLM应用开发(20)-Prompt(相关概念)
这种学习的目标,不是记忆特定事实或形成习惯性反应,而是学习更高级的、关于如何解决问题、何时应用何种方法的策略性知识。这些知识以文本形式存在,可供模型在执行任务时参考或作为指令。学习的反馈信号来自于任务的完成情况——模型在应用某个策略后的成功或失败,将指导其如何修改或生成更好的策略文本。
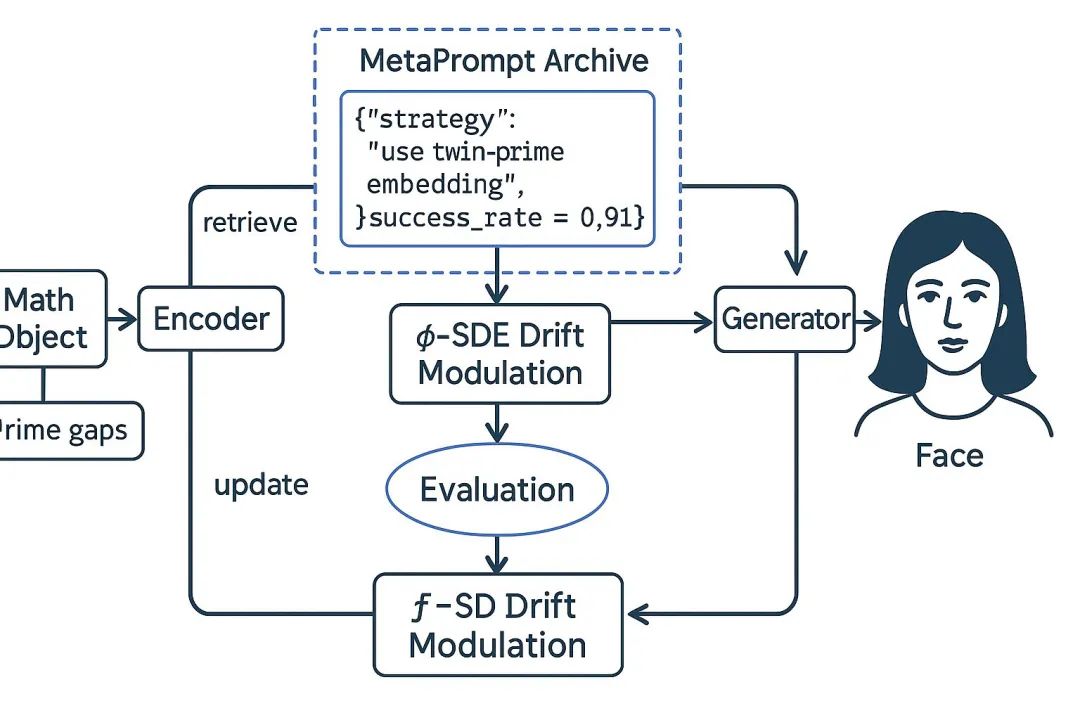
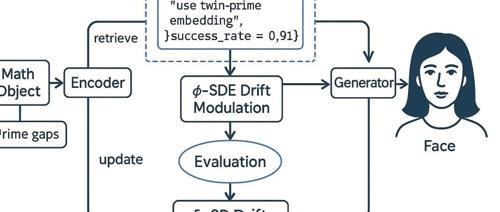
Karpathy 认为实现“系统提示学习”可能有以下几种潜在方向或组成部分:
- LLM自主生成与编辑系统提示文本: 一种直接的方式是让LLM具备自主生成和编辑其系统提示文本的能力。模型在尝试解决问题的过程中,通过对成功或失败经验的反思(Reflection),以文本形式概括出有效的策略或吸取的教训,并将其添加到自己的“记事本”或动态系统提示中。这类似于“让LLM给自己写一本书”,或者像生成思维链(Chain of Thought)一样,但生成的是可保存和复用的策略文本。
- 外部“记忆”或“知识库”存储学习到的策略: 另一种方式是利用外部的、可搜索的“记忆”或“知识库”来存储学习到的策略。LLM在解决问题成功后,将概括出的策略文本保存到外部存储(如向量数据库、结构化文件),并在下次遇到类似问题时检索相关策略作为额外的上下文指令。这种方法将策略知识与核心模型解耦,便于管理和更新,也与Voyager项目学习技能库以及当前一些探索长期记忆功能的AI系统思路相符。
- 专门的“策略模型”或“编辑模型”: 此外,也可能涉及到训练一个专门的“ sidecar model”(伴随模型)或“policy model”(策略模型)。这个模型不直接执行任务,而是根据主LLM在任务中的表现和反馈,学习如何生成或调整最适合主LLM当前任务的系统提示文本。主LLM应用这些文本执行任务,其结果再反馈给策略模型进行进一步学习和优化。
- 学习生成动态上下文指令流: 或者,学习过程表现为生成动态的上下文指令流,在任务执行的每一步根据情况生成即时指导或调整策略。
需要强调的是,这些是实现“系统提示学习”的潜在途径,具体的算法和架构仍在探索中。Karpathy 认为,这种基于文本编辑/生成的学习范式,与基于权重的梯度下降不同,可能更数据高效且强大,因为知识引导式的“回顾”能提供比简单奖励信号更高维度的反馈。
在随后的讨论中,许多评论者对此观点表示赞同,并提出了不同的称呼(如“系统二学习”、“系统上下文学习”、“便笺学习”、“语义连续性”等),并将其与反射(Reflection)、思维链(Chain of Thought)、代理学习(如Voyager项目)、记忆层等现有或正在探索的概念联系起来。这进一步表明,Karpathy 提出的“系统提示学习”概念,触及了当前LLM发展中的一个关键挑战:如何让模型不仅拥有知识和基本行为能力,还能像人类一样学习、积累和应用复杂的解决问题策略,而不仅仅依赖于庞大且静态的人工编写指令。
在笔者看来,Karpathy 关于“系统提示学习”的思考,是对现有LLM训练范式之外的一个关键补充,也是对传统方法的创新思考,就如同他对编程范式(vibe编程)思考一样:当前模型能力强大,其表现很大程度上取决于如何有效地提供和利用“上下文”(context),而系统提示正是其中至关重要的组成部分。他指出,依赖复杂手动编写的系统提示(如Claude的例子)存在局限性,因此模型需要学习自主管理和演进其指导行为的策略。通过类比人类记笔记和积累经验的方式,他提出的“系统提示学习”核心在于赋予LLM以显式文本形式学习、存储和应用策略的能力,这为实现更灵活、数据高效且类人的智能体、更好地利用和生成关键的“上下文”指明了重要方向,尽管具体的实现技术仍是待解难题。
公众号回复“进群”入群讨论。
(文:AI工程化)