

今天是2025年5月10日,星期六,北京,晴。
我们先来看一个问题,通过路由让Qwen3自行决定是否思考方案,从基本逻辑出发看看Qwen3的混合推理的根本实现机制以及如何通过外挂分类器来实现自我决断是否思考。
此外,来看昨日0509进展,围绕大模型开源数据,agent协议ACP,Qwen3思考规则路由,字节开源DeepResearch框架DeepFlow等话题。
抓住根本问题,做根因,专题化,体系化,会有更多深度思考。大家一起加油。
一、通过路由让Qwen3自行决定是否思考方案
Qwen3的混合推理推出了一段时间了,https://qwenlm.github.io/zh/blog/qwen3/,但并不能实现“自动对问题切换思考模式”,从实现上,需要手动进行推理模式的切换,例如:
硬开关机制下通过enable_thinking参数控制模型开启推理模式,例如:
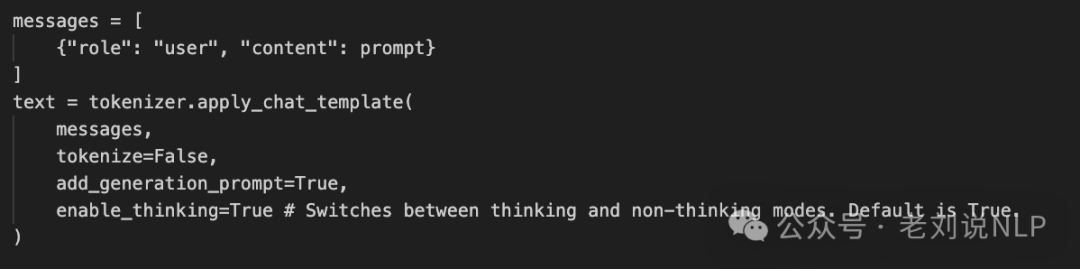
里面的核心在:https://huggingface.co/Qwen/Qwen3-8B/blob/main/tokenizer_config.json,
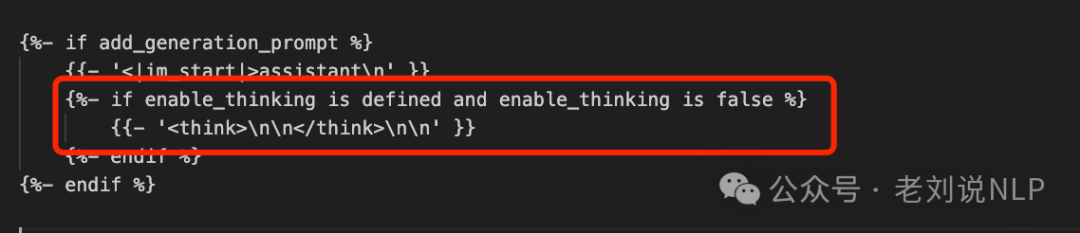
也就说,if enable_thinking is defined and enable_thinking is false的时候,会自动加入一个<think>\n\n</think>\n\n(也就是空思考,跳过模型的思考过程),这个很像Deepseek当时的一个bug,模型有的时候会跳过思考,所以会强制生成第一个token是<think>。
但是,在enable_thinking is not false时,并不强制第一个token为<think>,应该是为了为后面软开关做空间。
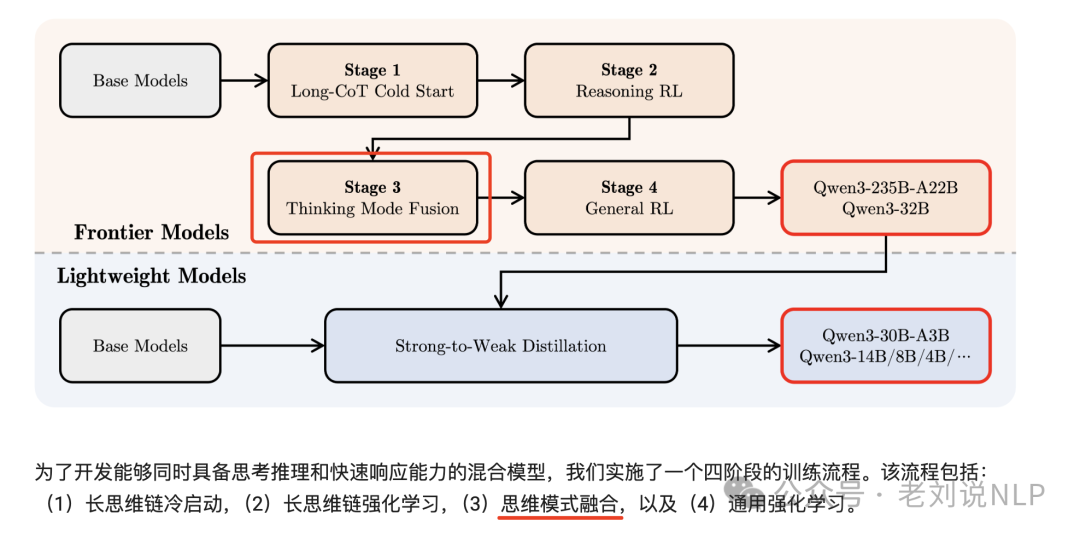
另一个是软开关,在enable_thinking=True时,在提示词或system消息中添加/think或/no_think来进行控制,所以,这块是内化在模型行为中的,根据训练报告来看,是在第三阶段中做的,在一份包括长思维链数据和常用的指令微调数据的组合数据上对模型进行微调,将非思考模式整合到思考模型中(核心还是构造这类数据)。
作为证据,这里的/think 、/no_think都不是special token,有对应的编码,分别是[33100, 5854, 766]和[20439, 766]。
但是,有个问题,这两个开关是否是冲突的?并不是,两个可以叠加处理,例如,在enable_thinking=True时,通过/no_think后,依旧可以跳过思考,也就是输出<think>\n\n</think>\n\n。
所以,基于上面这种机制,我们其实是可以来通过一个外挂路由的操作来粗暴的实现,自动对问题切换思考模式。
所以,有关于通过路由让Qwen3自行处理是否触发思考的两个开源项目,思想就是通过prompt判断,让Qwen3自动控制自己是否进行思考,如果用户提问简单问题,就不开启思考模式,如果问题复杂,就自动开启思考模式。
1、Better-Qwen3
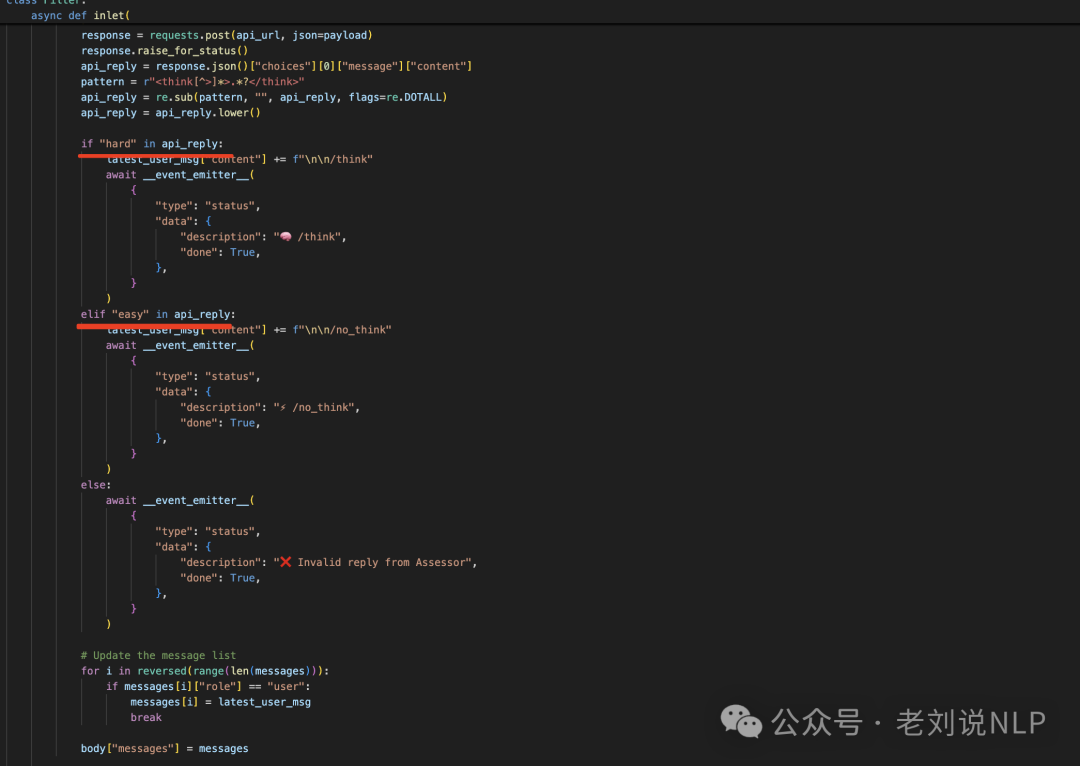
Better-Qwen3这个项目是最早的,地址在:https://github.com/AaronFeng753/Better-Qwen3,实现对应的脚本在:https://github.com/AaronFeng753/Better-Qwen3/blob/main/BetterQwen3.py,核心思路就是:提取最新用户消息和第一条用户消息->根据用户请求内容的长度进行截取(超过1010字符时,保留前500和后500字符)->构建API请求并发送->根据API响应判断请求难度:若响应为hard,添加/think标记。若响应为easy,添加/no_think标记。若响应无效,标记为无效回复。
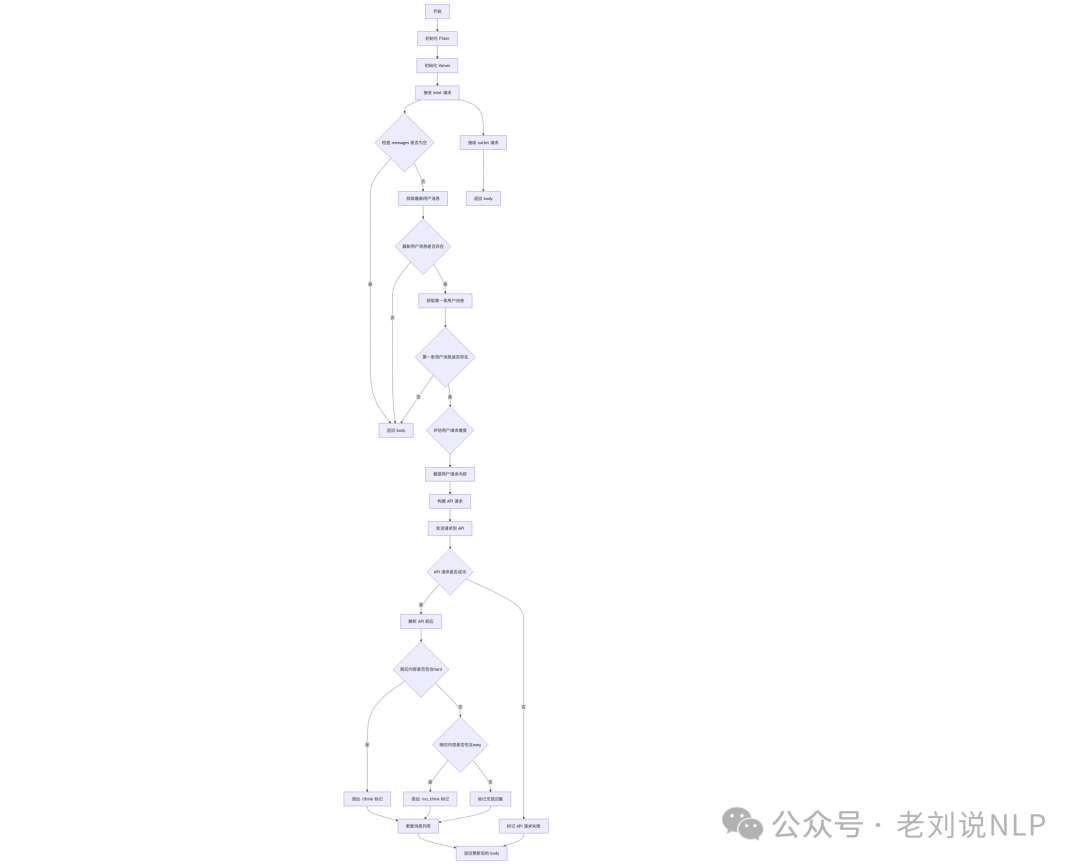
从代码上看,核心代码如下:

几个点:
一个是针对模型的输入,进行截断处理,以提升处理速度:如果用户请求的长度超过1000个字符,仅保留前500个字符和后500个字符,以加快处理速度。
另一个,评估模型,使用的是qwen3-32b-i4_xs(应该是个量化版本,https://huggingface.co/yasu-oh/Qwen3-32B-GGUF/blob/main/Qwen3-32B-IQ4_XS.gguf)
然后,prompt如下:

是个典型的三段结构,分别是任务背景、打分规则、输出格式。
然后,拿到数据后,再根据输出的结果中匹配对应的hard或者easy【处理比较粗糙】,只进行in操作判断,最后再添加no_think,think。
2、Qwen3_autothink_adapter
Qwen3_autothink_adapter的想法和部分代码来源于Better-Qwen3,实现脚本在https://github.com/hellangleZ/Qwen3_autothink_adapter/blob/main/auto_thinking.py,从实现上看,系统使用统一模型自动应用Qwen3的分类和“思考”过程,思路是一样的。
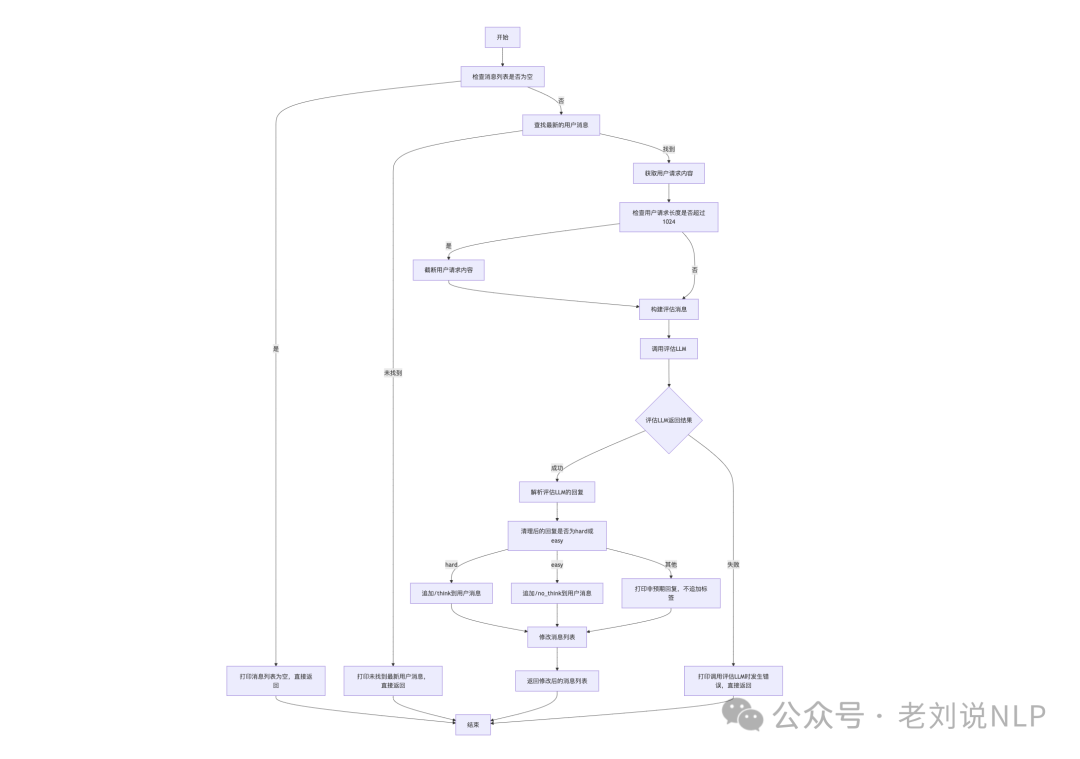
注意的默认情况下,分类器激活“不思考”状态以节省token并减少延迟,对整体响应的影响可以忽略不计。(这个是和Better-Qwen3不一样的点)
然后,分类器会根据传入的查询自动在“思考”模式和“不思考”模式之间进行选择
不同的点在于:
其一,这个项目提供输出内容显示调试状态、“思考”模式是否激活以及所有输出内容,这些信息可以根据需要选择性显示。
其二,提示一个模型assesment_model进行分类,分成easy或者hard,这里使用的是”Qwen3-30B-A3B”,其实分类判定模型可以自己切换,但这有赌的成分。

其三,具体提示与betterQwen3保持一致,但进行了提取,得到具体分类结果,为easy或者hard或者unknown_response。
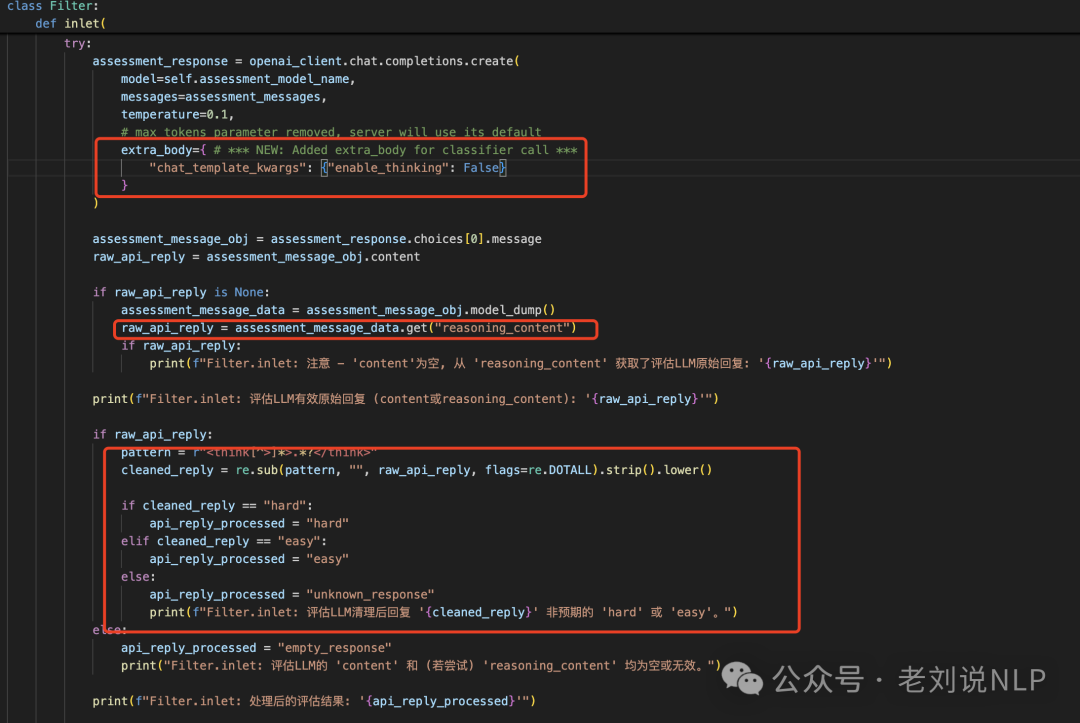
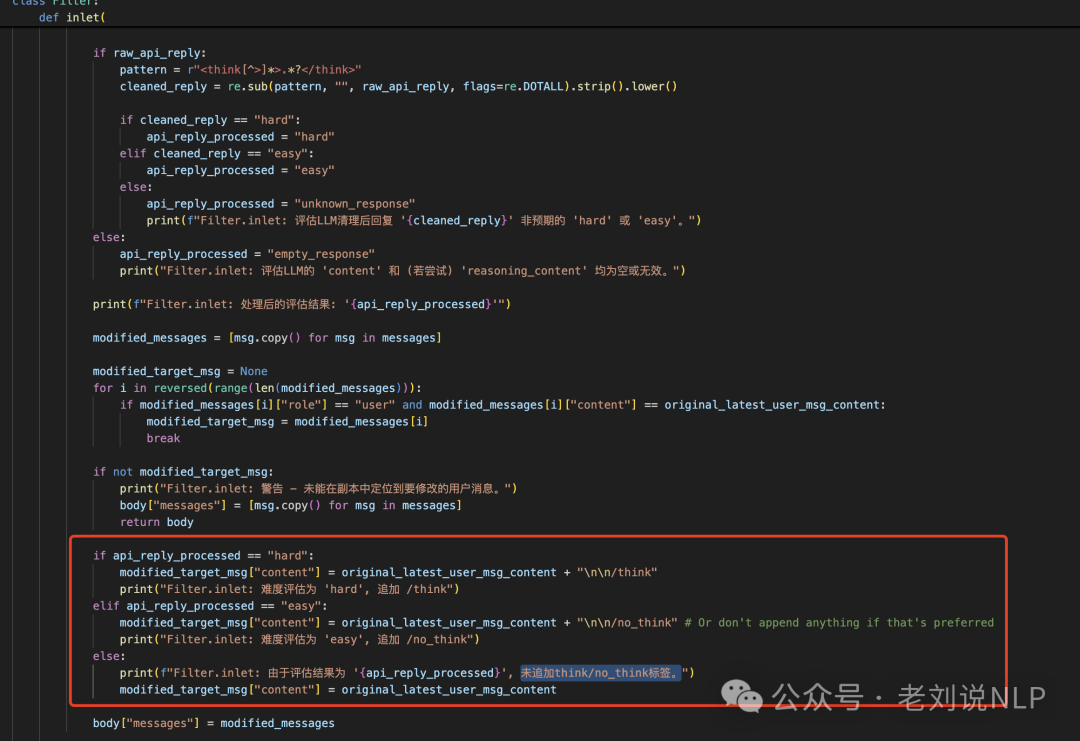
最后,在处理范式上,给出了过程展示,写的更清晰些。根据具体的结果,进行prompt的追加操作,如难度评估为 ‘hard’,追加 /think”,case如下:

难度评估为 ‘easy’, 追加 /no_think”,如下的case:
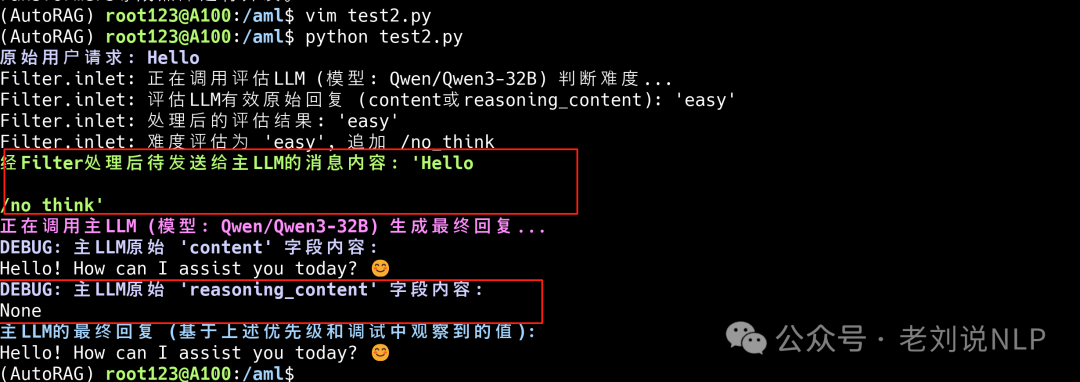
如果为unkown,则不追加think/no_think标签,也就是服从默认设置。
地址在:https://github.com/hellangleZ/Qwen3_autothink_adapter
二、记录下昨日0509技术进展早报
继续看社区进展,昨日0509进展,围绕大模型开源数据,agent协议ACP,Qwen3思考规则路由,字节开源DeepResearch框架DeepFlow等话题,供各位参考。

具体的,【老刘说NLP20250509技术进展早报】:
1、DeepResearch进展,字节开源Deep Research开源项目DeerFlow,https://github.com/bytedance/deer-flow,https://deerflow.tech/,该系统采用了一个精简的工作流程,整体实现架构图如下:

其中:
协调员Coordinator:管理整个工作流程生命周期的入口点。根据用户输入启动研究过程,在适当时机将任务委托给规划器,作为用户与系统之间的主要接口。
规划器Planner:负责任务分解和规划的战略性组件。分析研究目标并创建结构化的执行计划,判断是否有足够的上下文信息,或者是否需要进一步研究,管理研究流程,并决定何时生成最终报告。
研究团队Research Team:执行计划的一组专业代理。其中,Researcher使用网络搜索引擎、爬虫甚至MCP服务等工具进行网络搜索和信息收集;coder**使用Python REPL工具处理代码分析、执行和技术任务。每个代理都可以访问为其角色优化的特定工具,并在LangGraph框架内运行;
报告员Reporter:研究输出的最终阶段处理者。汇总研究团队的发现,处理和结构化收集到的信息,生成全面的研究报告。
2、关于通过路由让Qwen3自行处理是否触发思考的两个开源项目,https://github.com/hellangleZ/Qwen3_autothink_adapter,以及https://github.com/AaronFeng753/Better-Qwen3,其实就是prompt控制,让Qwen3自动控制自己是否进行思考,如果用户提问简单问题,就不开启思考模式,如果问题复杂,就自动开启思考模式。
3、关于agent的协议进展,ACP(Agent Communication Protocol,智能体通信协议),地址在https://github.com/auliwenjiang/agentcp,里面的设计理念很不错,有自己的特点,项目也开源了,也有一些case,分享出来,给大家看看,官网地址在:acp.agentunion.cn,飞书地址在:https://ccnz88r91l2y.feishu.cn/wiki/SrQkwb7seiM82MkSA4IcEAFdnGe,https://mp.weixin.qq.com/s/HOas5eP5D1ccPeaZ8XRiog

4、开源数据进展,大型开源文本数据集CCI4.0,包括3个子数据集,即CCI4.0-M2-BaseV1、CCI4.0-M2-CoTV1和CCI4.0-M2-ExtraV1,数据总量达35TB。
相关数据地址:Hugging Face地址:https://hf.co/datasets/BAAI/CCI4.0-M2-Base-v1,https://hf.co/datasets/BAAI/CCI4.0-M2-CoT-v1,https://hf.co/datasets/BAAI/CCI4.0-M2-Extra-v1;BAAI datahub地址:https://data.baai.ac.cn/datadetail/BAAI-CCI4.0-M2-Base-v1,https://data.baai.ac.cn/datadetail/BAAI-CCI4.0-M2-CoT-v1,https://data.baai.ac.cn/datadetail/BAAI-CCI4.0-M2-Extra-v1;魔搭地址:https://modelscope.cn/datasets/BAAI/CCI4.0-M2-Base-v1,https://modelscope.cn/datasets/BAAI/CCI4.0-M2-CoT-v1,https://modelscope.cn/datasets/BAAI/CCI4.0-M2-Extra-v1
总结
技术总是在变化,也都是那么朴实无华,专注技术本身,沉下心来,总会有更多收获。
参考文献
1、https://zhuanlan.zhihu.com/p/1902372138859631463
(文:老刘说NLP)