

编辑:张倩、Panda
Jim Fan,英伟达机器人部门主管和杰出科学家、GEAR 实验室联合领导人、OpenAI 的首位实习生,最近在红杉资本主办的 AI Ascent 上做了一场 17 分钟的演讲,介绍了「解决通用机器人问题的第一性原理」,包括训练机器人 AI 的数据策略、Scaling Law 以及基于物理 API 的美好未来。
其中尤其提到了「物理图灵测试」,大意是说对于一个真实的物理场景和一个指令,会有人类或机器人根据该指令对这个场景进行相应的处理,然后看其他人能否分辨这个场景是人类处理的还是机器人处理的。
很显然,Jim Fan 以及英伟达正在朝着让机器人和 AI 通过这个物理图灵测试而努力。在文本中,我们梳理了 Jim Fan 的主要演讲内容,另外还在文末发起了一个投票,看你觉得物理图灵测试会在什么时候被攻克?
以下为经过梳理的演讲内容。
几天前,一篇博客文章引起了我的注意。它说:「我们通过了图灵测试,却没人注意到。」图灵测试曾经是神圣的,堪称计算机科学的圣杯,结果我们就这么通过了。
Jim Fan 提到的博客:https://signull.substack.com/p/we-passed-the-turing-test-and-nobody
当 o3 mini 多花几秒钟思考,或者 Claude 无法调试你那些讨厌的代码时,你会感到不满,对吧?然后我们把每一个大语言模型的突破都当作只是又一个普通的星期二。在座的各位是最难打动的人。
所以我想提出一个非常简单的东西,叫做「物理图灵测试(Physical Turing Test)」。
物理图灵测试
想象一下,你在周日晚上举办了一个黑客马拉松派对,最后你的房子变成了这样:

你的伴侣对你大喊大叫,你想:「哎呀,周一早上,我想告诉某人清理这个烂摊子,然后为我准备一顿很好的烛光晚餐,这样我的伴侣就能开心了。」
然后你回到家,看到这一切(实现了),但你无法分辨是人还是机器帮你弄的。物理图灵测试就是这么简单。

那我们现在进展到什么程度了?接近了吗?看看这个准备开始工作的机器人:

再看看机器狗遇到香蕉皮:

机器人为你准备燕麦早餐:

这就是我们的现状。
那么,为什么解决物理图灵测试如此困难呢?
你们知道大语言模型研究人员经常抱怨,对吧?最近有个叫 Ilya 的人抱怨说:大语言模型预训练的数据快用完了。他甚至称互联网为「AI 的化石燃料」。他说我们快没有数据来训练大语言模型了。但是,如果你了解机器人模型,你就会知道大语言模型研究人员被宠坏了。我们甚至连化石燃料都没有。

下图是英伟达总部的一个数据收集环节。英伟达有一个咖啡厅,我们设置了这些人形机器人,我们操作它们并收集数据。

收集到的数据如下图所示。这是机器人关节控制信号,是随时间变化的连续值。你在维基百科、YouTube、Reddit 或任何地方都找不到这种数据,所以你必须自己收集。
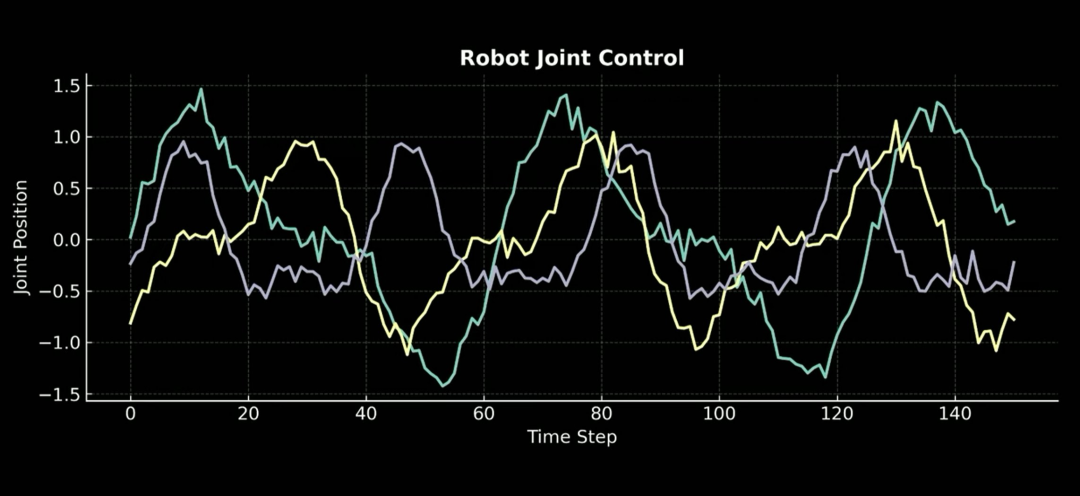
那我们是怎么收集的呢?
我们有一种非常复杂但也非常昂贵的方法,叫做遥操作(teleoperation)。你可以让人佩戴某种 VR 头显,它能识别你的手势并将其传输给机器人。这样你就可以教机器人技能,比如从烤面包机中取出面包,然后倒上蜂蜜。但可以想象,这是一个非常缓慢且痛苦的过程。

如果你把这个方法放到 scaling 图上,你会发现它根本不能 scale。真实机器人数据的获取是在拿人力当燃料,这比用化石燃料更糟糕。而且,一个机器人每天只有 24 小时的时间可以用。实际可利用的时间更少,因为人会疲劳,机器人比人类更容易疲劳。

那我们该怎么办呢?机器人的核能在哪里?我们必须有清洁能源。不能永远依靠化石燃料。
模拟很重要
接下来进入「模拟」。我们必须离开物理世界,进入模拟的世界。
我们训练了一个机器手,能在模拟中完成超人般的灵巧任务,如转笔。对我来说这是超人的,因为我不能转笔,我很高兴我的机器人至少在模拟中能做得比我好。

那么如何训练机器手来完成这样复杂的任务呢?我们有两个想法。一是你必须以比实时快 10000 倍的速度进行模拟。这意味着你应该在单个 GPU 上并行运行 10000 个环境进行物理模拟。

第二点,10000 个环境副本不能都相同。你必须改变一些参数,如重力、摩擦力和重量。我们称之为域随机化。
这给了我们模拟原则。
为什么这种做法能 work?想象一下,如果一个神经网络能够控制机器人掌握一百万个不同的世界,那么它很可能也能掌握第一百万零一个世界 —— 即我们的物理现实。换句话说,我们的物理世界处于这种训练的分布之中。

接下来,我们如何应用这些模拟结果呢?你可以建立一个数字孪生(digital twin),即机器人和世界的一对一副本,然后你在模拟中训练,直接在真实世界中测试,零样本迁移。

机器手也是如此:

我们能做的最令人印象深刻的任务是让狗站在瑜伽球上走,我们把它从虚拟迁移到现实世界。

我们的研究人员看起来超级奇怪,就像《黑镜》的一集。

接下来,我们还可以将其应用于更复杂的机器人,如人形机器人。在短短两小时的模拟时间内,这些人形机器人就经历了 10 年的训练,学习行走,然后你可以把它们迁移到现实世界。无论实体是什么,只要你有机器人模型,你就可以模拟它,并且可以实现行走。

我们能做的不仅仅是行走。当你控制自己的身体时,你可以跟踪任何你想要的姿势,跟踪任何关键点,遵循任何你想要的速度向量,这被称为人形机器人的全身控制问题,是个非常困难的问题。

但我们可以训练它,在 10000 个并行运行的模拟上,我们可以将其零样本迁移到真实机器人上,无需任何微调。
这是在英伟达实验室进行的一个演示。你可以看到它所做的动作的复杂性。它模仿人类所有这些敏捷的动作,同时保持平衡。

做这个需要多大的神经网络?它只需要 150 万参数,不是 15 亿。150 万参数足以捕捉人体的潜意识处理。
所以,如果我们将其放在这个图表上,纵轴是速度,横轴是模拟的多样性,我们称之为模拟 1.0,数字孪生范式,它是一个经典的向量化物理引擎,你可以运行到每秒 10000 帧甚至一百万帧。但问题是你必须建立一个数字孪生。你需要有人建造机器人,建造环境和一切。这非常繁琐,且需要手动完成。

用生成式 AI 生成模拟数据
那么,我们能否用生成的方式获得模拟环境的一部分?下图这些 3D 资产都是由 3D 生成模型生成的:

这些纹理来自 Stable Diffusion 或任何你喜欢的扩散模型:

这些布局也是可以用工具生成的:

将所有这些放在一起,我们构建了一个名为 RoboCasa 的框架,它是日常任务的一个组合模拟。这里的一切,除了机器人,都是生成的。你可以组合不同的场景,但它仍然依赖于这个经典引擎来运行,但你已经可以从中获得很多任务。
接下来,同样让人类来操作。但这一次,人类是在模拟中进行操作。

基于这一个放杯子的演示,我们可以得到人类操作的轨迹,然后便可以在模拟中重放这一轨迹。
而在模拟中,我们可以通过各种技术修改场景,甚至还可以修改运动,比如可以通过 GR00T Mimic 等技术模拟出相似的动作。


也就是说,只需一个人类演示,就能通过环境生成得到 N 个演示,如果在执行动作生成,则能得到 N×M 个不同的模拟样本。如此一样,便实现了数据的倍增。

如下所示,第一和三列是真实的机器人,第二和四列是生成的模拟。看得出来,生成的视频的纹理真实感依然很差,但它们已经足够接近了。

那么,我们如何称呼这些足够接近的生成样本呢?数字表亲(digital cousin)。这与数字孪生不一样,但也在一定程度上捕捉到了真实感。

这些模拟运行速度较慢,但目前存在一种混合生成物理引擎 —— 先生成部分内容,然后将剩余部分委托给经典图形管道。
现在,假如我们要模拟这个场景。可以看到,里面有固体、有液体,各种东西。如果让人类来建模,所需的时间会很长。

但现在,有计算机模拟了。
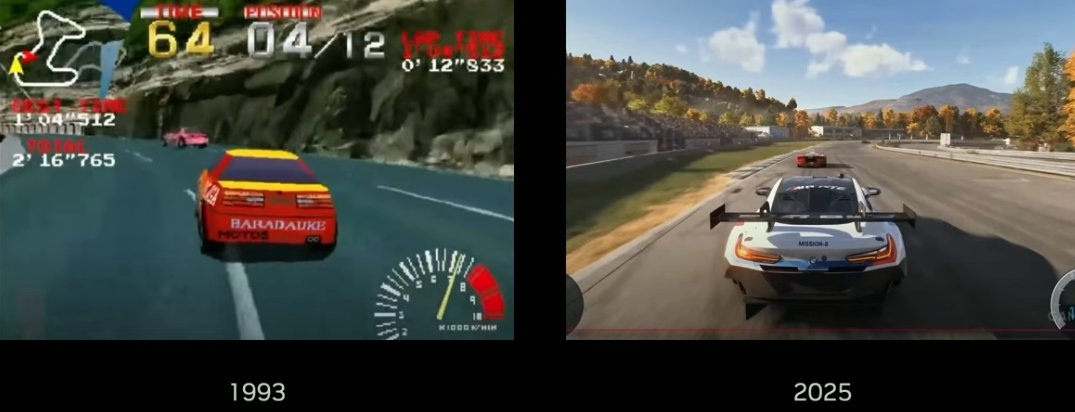
要知道,从左边的视觉效果到右边的视觉效果,可是足足花了 30 多年时间。但视频生成模型只用了一年时间从实现从左边到右边的跨越。

还记得我之前展示的这个视频吗?我骗了你们。这个视频里的像素没一个是真的。它完全是由一个自定义模型生成的。

我们是怎么做的呢?我们会使用一个开源的通用 SOTA 视频生成模型,然后在真实收集的数据的数据域上进行微调。

然后,使用不同的语言命令,你可以让模型想象不同的未来 —— 即便这个场景从未在真实世界中发生过。

这些也都是生成的。

其中有个例子是机器手弹奏尤克里里,但实际上,这个机器手还完全做不到这一点,但 AI 依然可以生成这样的视频。
这就是模拟 2.0。视频生成的多样性大大增加,但目前执行起来速度很慢。我称之为 Digital Nomad(数字游民),可以说它已经进入了视频扩散模型的梦境空间。它是将数亿个互联网视频压缩成这种多元宇宙的模拟,就像奇异博士一样 —— 在梦境空间中实例化机器人,基本上机器人现在可以与任何地方的所有事物都同时互动。

具身 Scaling Law
下面来看具身 Scaling Law。
在模拟 1.x 时代,大规模模拟需要大规模的计算。问题是,随着规模的扩大,物理 IQ 会撞墙,因为这个人工构建的系统的多样性有限。

而在神经世界模型的模拟 2.0 时代,物理 IQ 会随计算的扩展而指数级增长。图中的交汇点便是神经网络超越传统图形工程的地方。

这两者加在一起,将成为我们扩展下一代机器人系统的核能。
引用黄仁勋的话就是:「买得越多,省得越多。」
然后,我们把这些数据用来训练「视觉-语言-动作模型」。它能接收像素和指令输入,然后输出电机控制信号。这就是三月份 GTC 上黄仁勋主题演讲中开源的 GR00T N1 模型的训练方式。
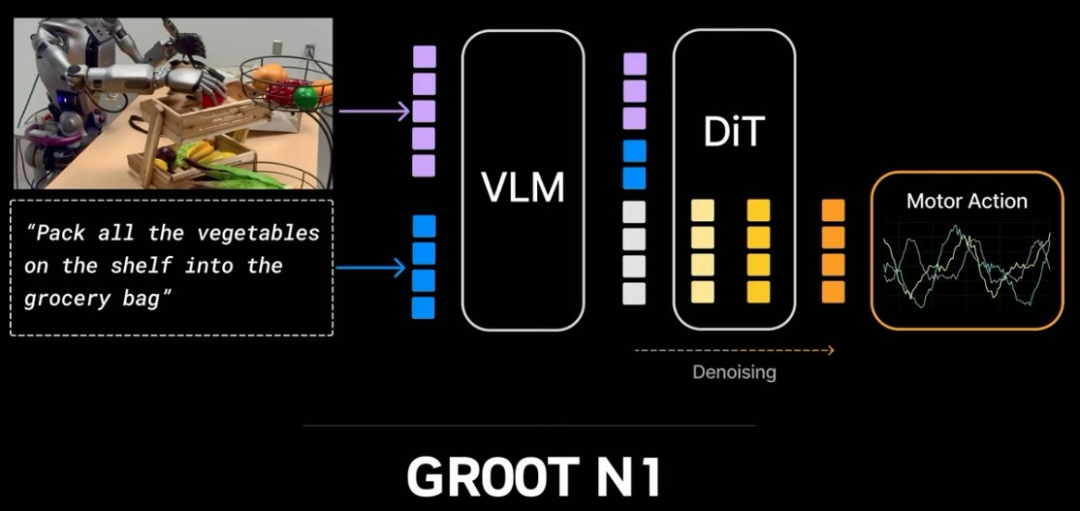
这里展示了一个在实际机器人上运行它的案例。看起来很浪漫,但你无法想象我们在训练期间做了多少清洁工作。在这个示例中,它能够完美地抓起香槟。

不仅如此,它还可以执行一些工业任务,拿取一些工厂物件,还可以进行多机器人协调。

GR00T N1 模型是开源的,事实上这个系列的后续模型都将继续开源。
展望未来:物理 API
那么,下一步是什么呢?我认为是物理 API(Physical API)。

想一想,5000 年来,虽然人类的生活整体好了很多,但做晚餐的方式可能与古埃及人没有本质差别。

也许人类历史的 99% 的时间里,我们都保持着这样的结构:用人力方式处理原材料,最终建立起文明。但在最近的 1% 时间里,大概最近 50 年的时间里,人工劳动量正在减少,我们拥有高度专业化、高度复杂的机器人系统,它们一次只能做一件事。而且它们的编程成本很高。目前,我们处于人类劳力与机器人共存的时代。

未来,物理 API 将无处不在。
类似于 LLM API 移动数字和比特构成的块,物理 API 能移动原子构成的块,也就是给软件一个物理执行器来改变物理世界。

在这个物理 API 之上,将会有新的经济范式。我们会有新的物理提示技术(physical prompting)来给机器人下达指令,教它们学习新任务。语言有时候是不够的。
我们还会有物理应用商店和技能经济。举个例子,米其林大厨不必每天都亲自去厨房了 —— 他可以教会机器人,把晚餐作为一项服务提供。
这里再次引用黄仁勋的一句话:「所有会动的东西都将自动化。」

未来某天,当你回家,你会看到干净的沙发和烛光晚餐,你的伴侣会对你微笑,而不是因为你没有洗脏衣服而对你大喊大叫。

这是因为你上个月买了两台人形机器人,可能是 GR00T N7,它们默默工作,与你生活的背景融为一体,就像是环境智能(ambient intelligence)。你甚至不会注意到它们通过物理图灵测试那一刻,因为那就是像是另一个平常的星期二一样。
©
(文:机器之心)