

本文我们将探索少样本学习(Few-Shot Learning)和上下文学习(In-Context Learning)的前沿技术,这些方法使 AI 模型能够通过最少的示例执行复杂任务,革新了我们解决机器学习问题的方式。
传统的机器学习通常需要大量的数据集来进行训练,这既耗时又需要大量资源。少样本学习和上下文学习通过利用 LLM 的强大能力,仅凭少量示例即可执行任务,从而解决了这一限制。这种方法特别适用于标注数据稀缺或获取成本高的场景。
方法详情
-
基础少样本学习
-
实现一个情感分类任务,使用少样本学习。
-
演示如何构建带有示例的提示,以便模型学习。
-
解释模型如何从这些示例中概括并应用到新输入。
-
高级少样本技术
-
探讨情感分析和语言检测的多任务学习。
-
讨论如何设计提示,使单一模型能够执行多个相关任务。
-
分享这种方法的好处,如提高效率和更好的泛化能力。
-
上下文学习
-
演示如何为自定义任务(例如文本转化)使用上下文学习。
-
解释模型如何仅基于提示中提供的示例来适应新任务。
-
讨论这种方法的灵活性和局限性。
-
最佳实践与评估
-
选择有效示例进行少样本学习的指南。
-
提供优化模型性能的提示工程技术。
-
实现一个评估框架,评估模型的准确性。
-
讨论多样化测试用例和合适的度量标准的重要性。
少样本学习和上下文学习代表了人工智能领域的重大进展。这些技术使得模型能够仅凭最少的示例执行复杂任务,为数据有限的领域中的 AI 应用开辟了新可能。本教程为理解和实施这些强大方法提供了坚实的基础,帮助学习者掌握如何在自己的项目中有效利用 LLM。
随着该领域的不断发展,掌握这些技术将是 AI 从业者保持在自然语言处理和机器学习前沿的关键。
基础少样本学习
我们将实现一个基础的少样本学习场景,进行情感分类。
情感分类:
-
定义:确定一系列词语背后的情感基调。
-
应用:客户服务、市场调研、社交媒体分析。
少样本学习方法:
-
提供一小部分标注示例(此处为3个示例)。
-
结构化提示,清晰地展示示例和新的输入。
-
利用语言模型的预训练知识。

高级少样本技术
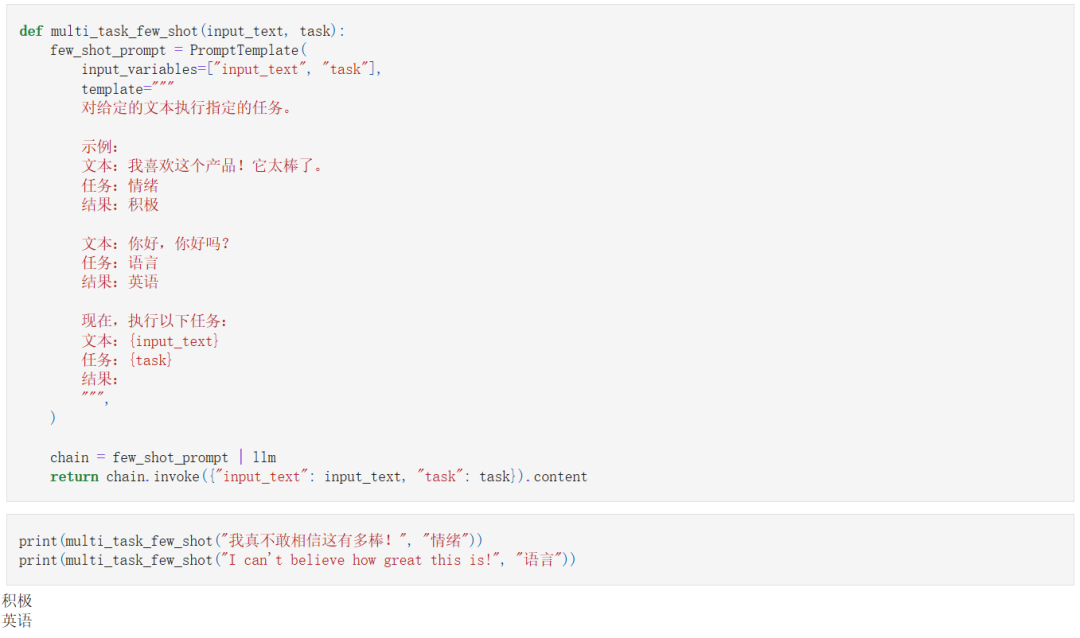
我们现在将探讨情感分析和语言检测的多任务学习。
多任务学习:
-
定义:训练一个模型同时执行多个相关任务。
-
好处:提高效率、更好的泛化能力、减少过拟合。
实现方法:
-
设计一个包含多个任务示例的提示模板。
-
使用任务特定的指令引导模型的行为。
-
演示同一个模型如何根据输入在不同任务之间切换。
上下文学习
上下文学习允许模型根据提示中提供的示例适应新任务。
关键特点:
-
无需微调:模型通过提示中的示例进行学习。
-
灵活性:可以应用于广泛的任务。
-
提示工程:精心设计提示对于模型性能至关重要。
示例实现:我们将演示如何为自定义任务(将文本转换为猪拉丁)实现上下文学习。

猪拉丁(Pig Latin,或译儿童暗语)是一种英语语言游戏,形式是在英语上加上一点规则使发音改变。据说是由在德国的英国战俘发明来瞒混德军守卫的。Pig Latin于1950年代和1960年代在英国利物浦达到颠峰,各种年纪和职业的人都有使用。Pig Latin多半被儿童用来瞒着大人秘密沟通,有时则只是说着好玩。虽然是起源于英语的游戏,但是规则适用很多其他语言。
wiki
最佳实践与评估
为了最大化少样本学习和上下文学习的效果:
示例选择:
-
多样性:涵盖任务的不同方面。
-
清晰性:使用明确无歧义的示例。
-
相关性:选择与预期输入相似的示例。
-
平衡性:确保各类/类别的示例均衡。
-
边缘案例:包含一些不常见或难度较大的案例示例。
提示工程:
-
明确指令:清晰地指定任务。
-
一致格式:保持示例和输入的统一结构。
-
简洁性:避免包含不必要的信息,以免混淆模型。
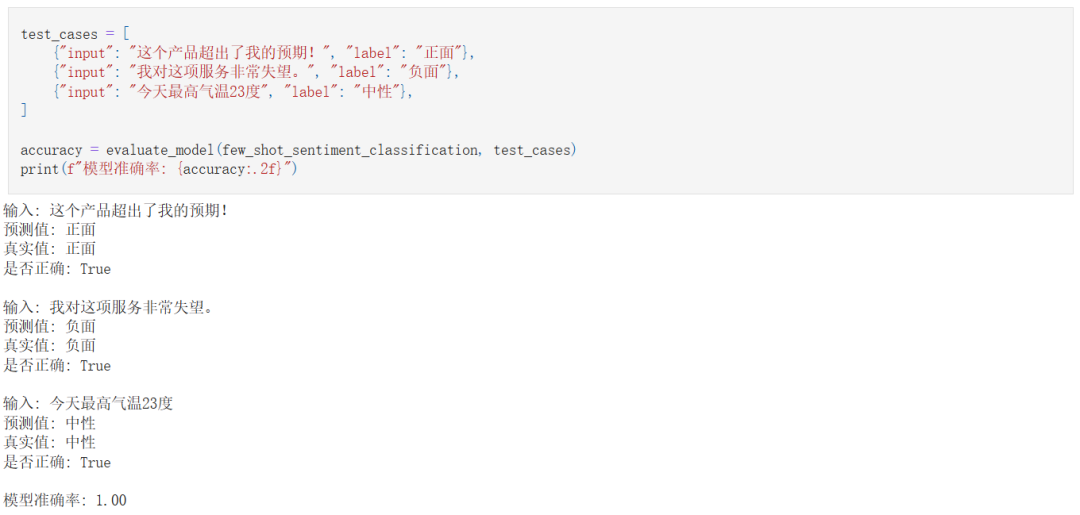
评估:
-
创建一个多样化的测试集。
-
将模型预测结果与真实标签进行比较。
-
根据任务使用合适的度量标准(如准确率、F1分数等)。

比如:
本文源代码:
https://github.com/realyinchen/PromptEngineering/blob/main/05-few-shot-learning.ipynb
查阅此前文章:
《提示工程101第四课:零样本提示(Zero-Shot Prompting)》
《提示工程101第三课:提示模板和变量》
《提示工程101第二课:基础的提示结构》
《提示工程101第一课:基础入门》
文章来源:PyTorch研习社
(文:PyTorch研习社)