

机器之心报道
训练狗时不仅要让它知对错,还要给予差异较大的、不同的奖励诱导,设计 RLHF 的奖励模型时也是一样。

-
论文标题:What Makes a Reward Model a Good Teacher? An Optimization Perspective -
论文链接:https://arxiv.org/pdf/2503.15477

-
在最小对比对上进行训练:可以人工合成这些对比对,要求奖励模型能够可靠地为其中一个输出赋予略高的分数。 -
从生成式奖励模型中计算连续奖励:通过取 token 概率和分数的加权和来实现。 -
结合监督微调(SFT)、均方误差(MSE)和偏好损失:这些方法使模型能够生成推理依据,优化其连续奖励,并有效地从最小对比对中学习!
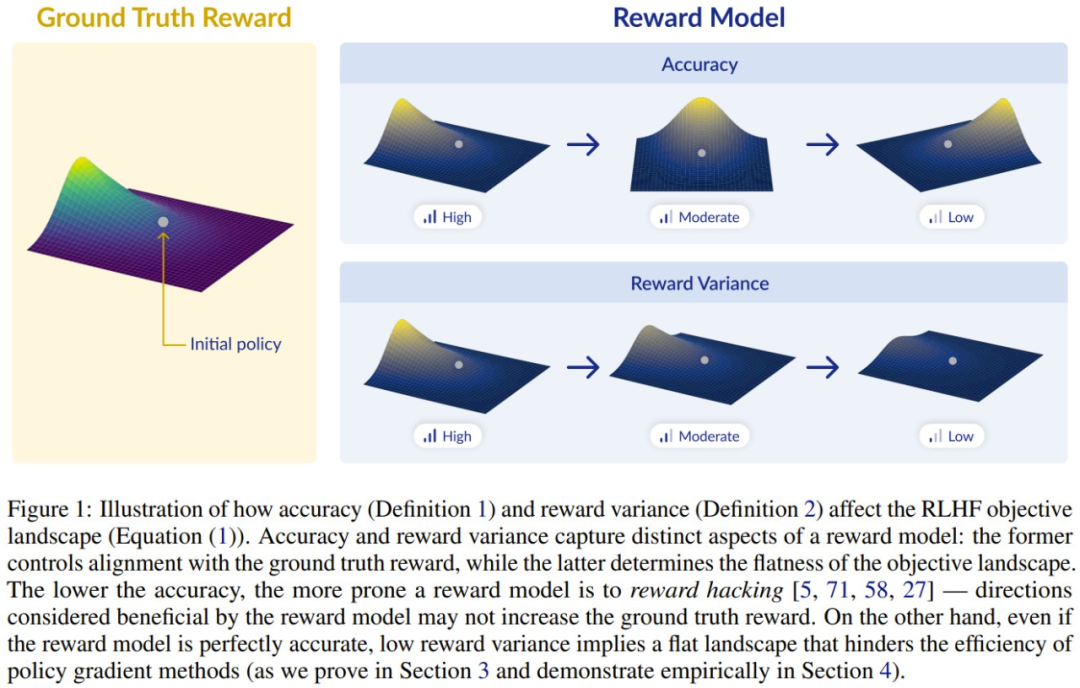
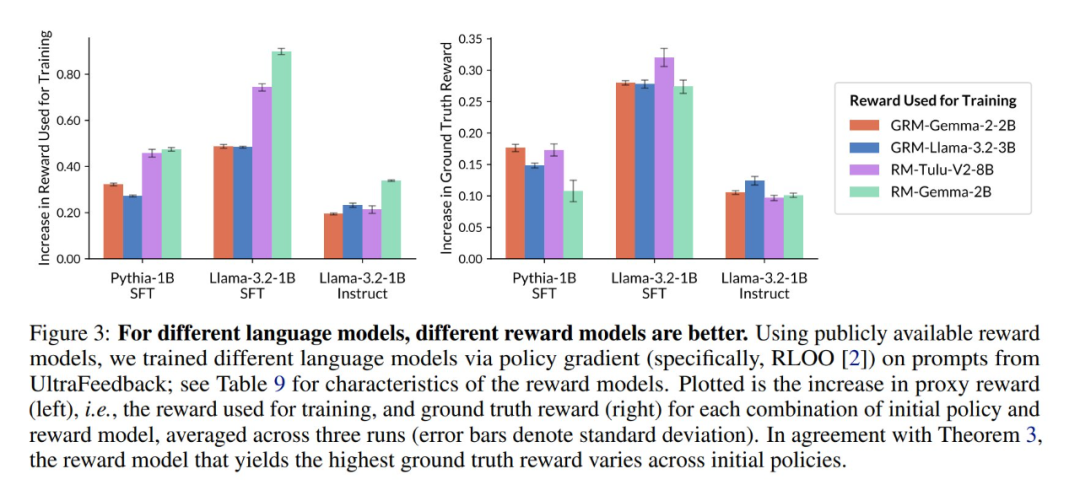
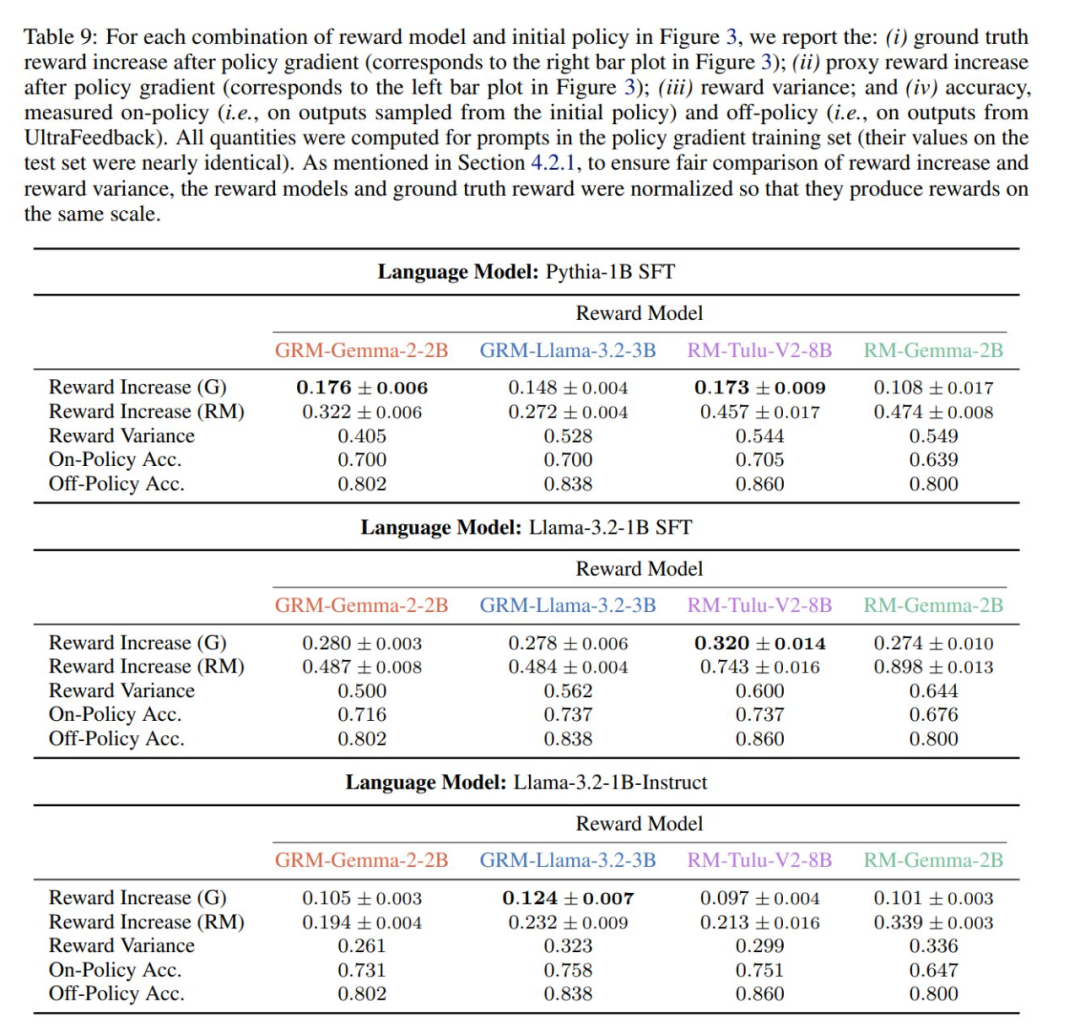
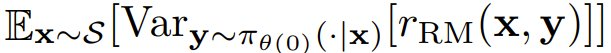 成反比,这是 r_RM 针对初始策略与训练集 S 中的提示词得到的平均奖励方差。这样一来,如果提示词 x ∈ S 的
成反比,这是 r_RM 针对初始策略与训练集 S 中的提示词得到的平均奖励方差。这样一来,如果提示词 x ∈ S 的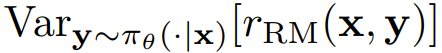 较低(即当 r_RM 无法充分地分离在初始策略下可能的输出时),则策略梯度就会出现优化速度慢的问题。
较低(即当 r_RM 无法充分地分离在初始策略下可能的输出时),则策略梯度就会出现优化速度慢的问题。
 都会随着 衰减。然而,仅凭这一点并不能得到令人满意的奖励最大化率下限,因为如果没有进一步的知识,梯度范数可能会在训练过程中迅速增加。
都会随着 衰减。然而,仅凭这一点并不能得到令人满意的奖励最大化率下限,因为如果没有进一步的知识,梯度范数可能会在训练过程中迅速增加。

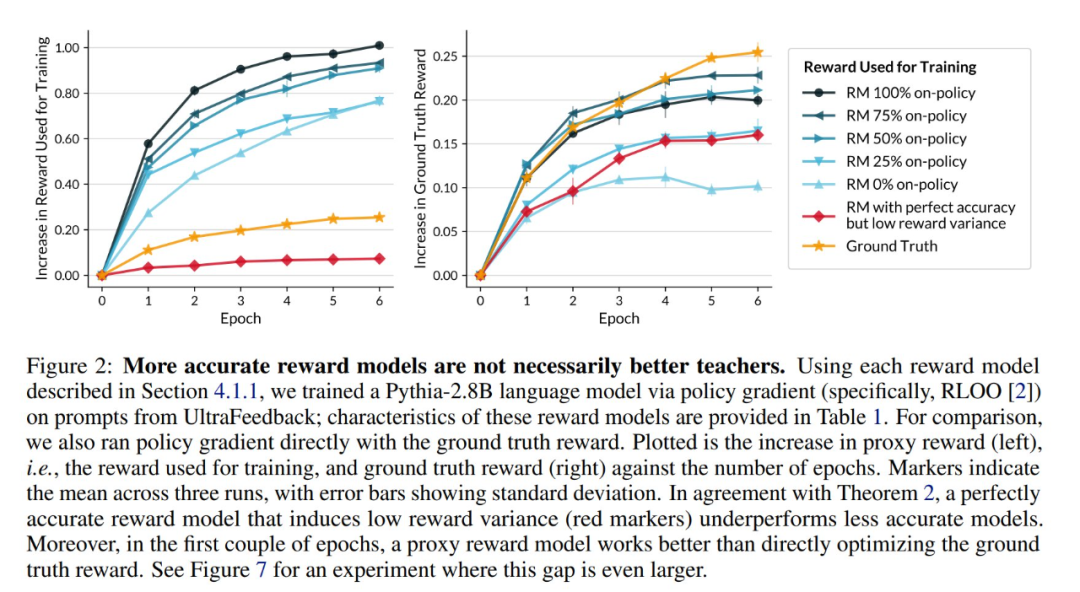
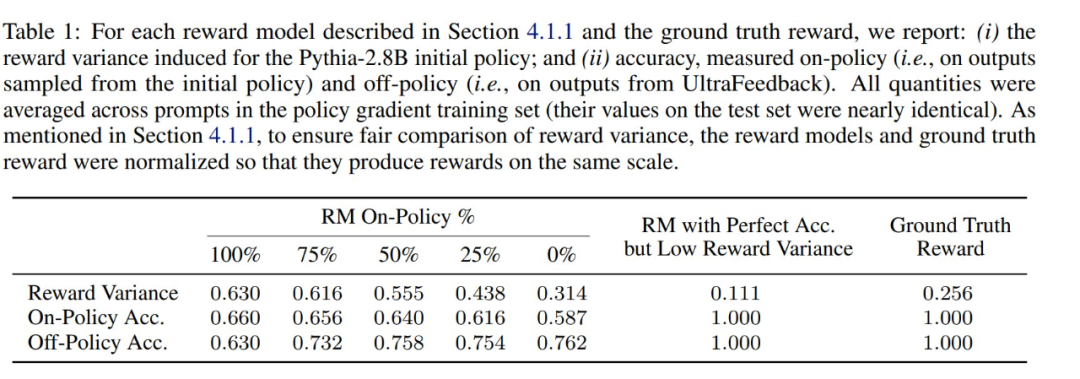
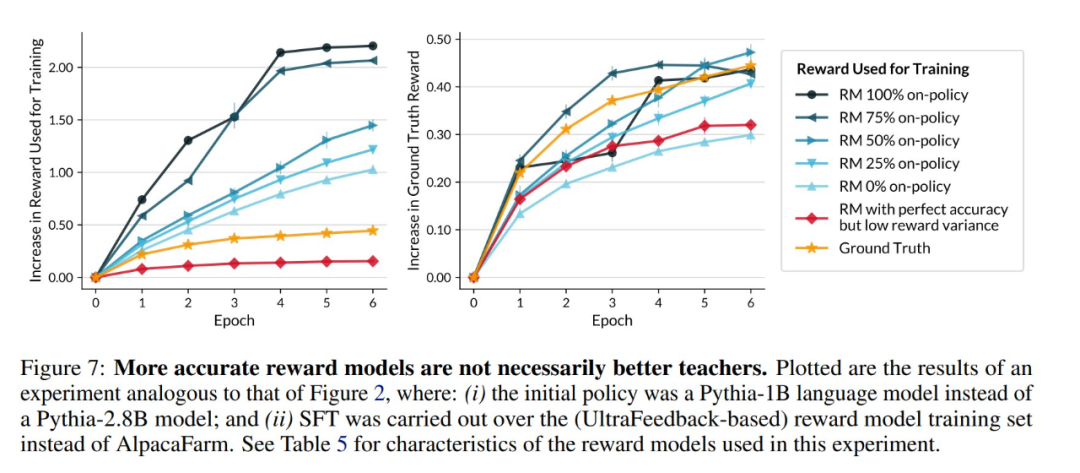
(文:机器之心)