



-
论文项目主页: https://nirvanalan.github.io/projects/GA/
-
论文代码: https://github.com/NIRVANALAN/GaussianAnything
-
Gradio demo 地址: https://huggingface.co/spaces/yslan/GaussianAnything-AIGC3D
-
个人主页: https://nirvanalan.github.io/
-
论文标题:GaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation
-
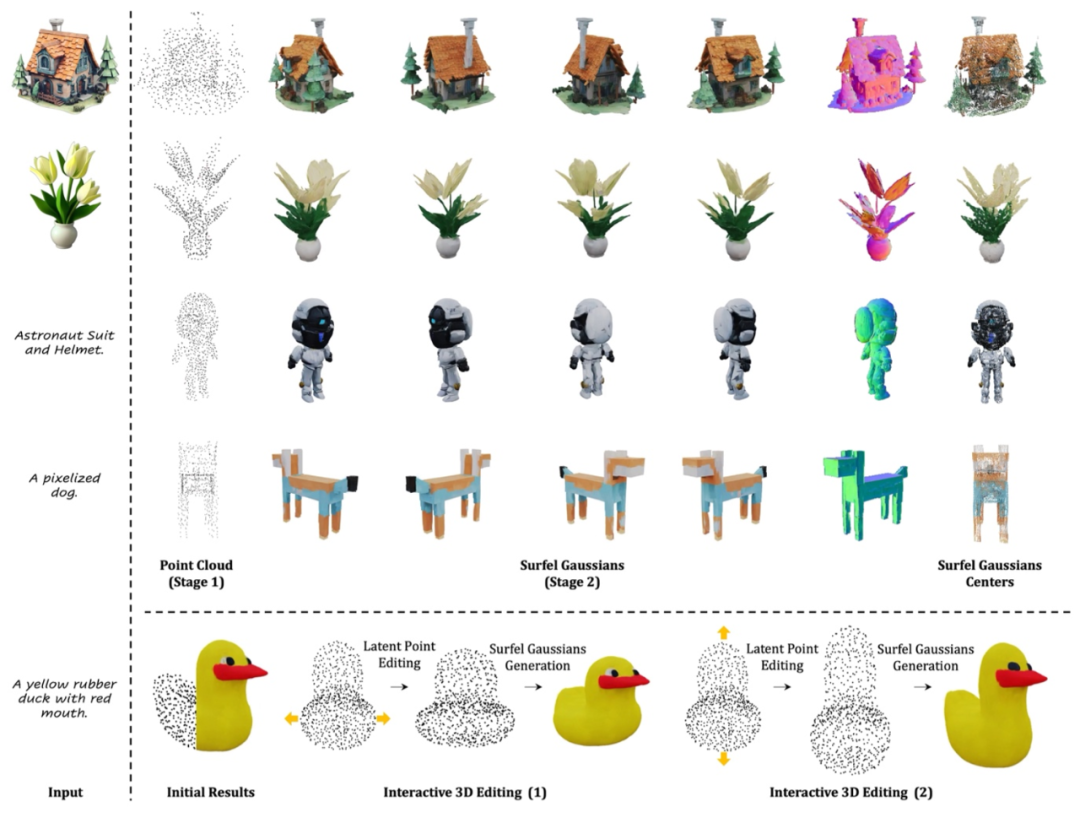
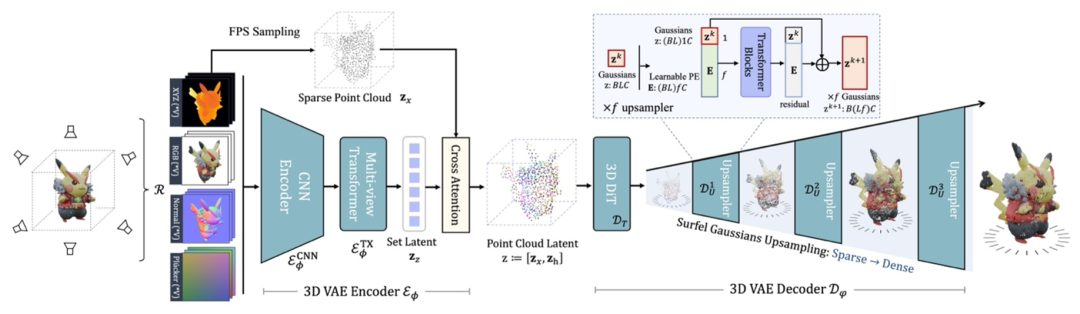
利用编码器 (3D VAE Encoder) 将 3D 物体的 RGB-D (epth)-N (ormal) 多视图渲染图压缩到点云结构的 3D 隐空间。
-
在 3D 隐空间中训练几何 + 纹理的级联流匹配模型 (Flow Matching model), 支持图片、文字、和稀疏点云引导的 3D 物体生成。
-
使用 3D VAE Decoder 上采样生成的点云隐变量,并解码为稠密的表面高斯 (Surfel Gaussian)。
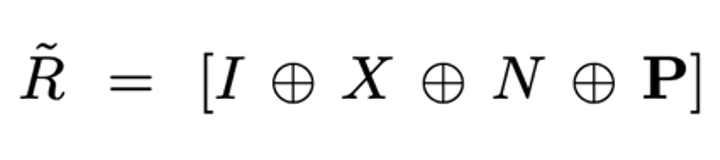 作为多视图编码器的输入。
作为多视图编码器的输入。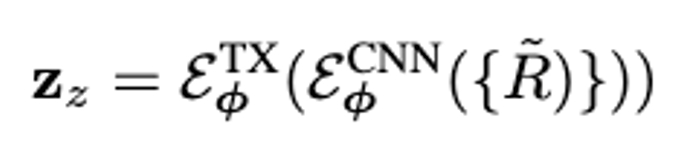 。相较于使用稠密点云作为输入的方法,本文的 3D VAE Encoder 更高效自然地拥有来自多种输入格式的丰富的 3D 信息,并能够同时压缩颜色与几何信息。
。相较于使用稠密点云作为输入的方法,本文的 3D VAE Encoder 更高效自然地拥有来自多种输入格式的丰富的 3D 信息,并能够同时压缩颜色与几何信息。 , 本文中研究者认为该隐空间并不适合直接用于 3D diffusion 的训练。首先,的维度
, 本文中研究者认为该隐空间并不适合直接用于 3D diffusion 的训练。首先,的维度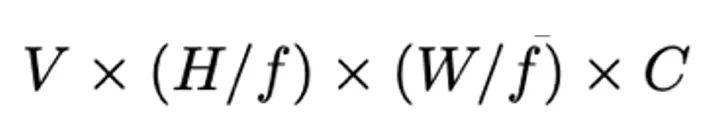 较高,在高分辨率下训练开销巨大。其次,multi-view latent 并非原生的 3D 表达,无法直观灵活地用于 3D 编辑任务.
较高,在高分辨率下训练开销巨大。其次,multi-view latent 并非原生的 3D 表达,无法直观灵活地用于 3D 编辑任务. 将特征投影到从输入物体表面采样得到的稀疏的 3D 点云 上。最终的点云结构化隐变量
将特征投影到从输入物体表面采样得到的稀疏的 3D 点云 上。最终的点云结构化隐变量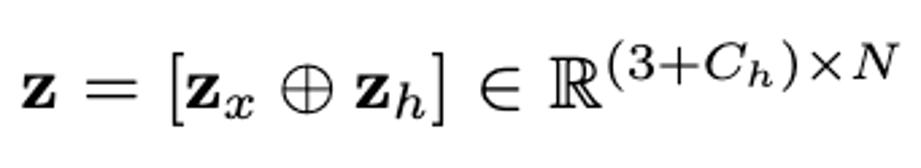 被用于 diffusion 生成模型的训练。
被用于 diffusion 生成模型的训练。 ,得到深层次特征。
,得到深层次特征。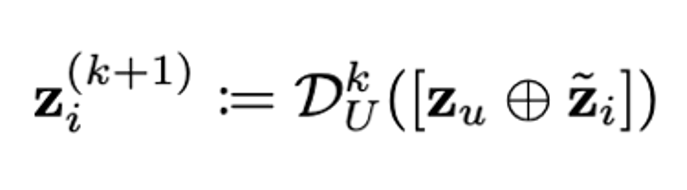 。该设计同时支持不同细节层次 (Level of Details) 的 3D 资产输出,提升了本文方法的实用性。
。该设计同时支持不同细节层次 (Level of Details) 的 3D 资产输出,提升了本文方法的实用性。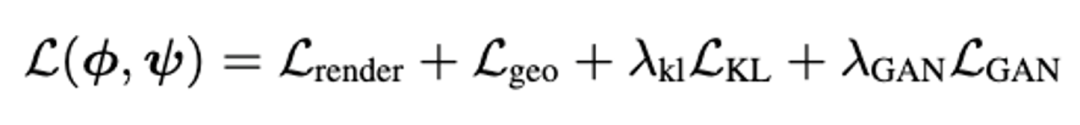
 为多视图重建损失,
为多视图重建损失,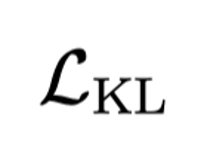 为 VAE KL 约束,
为 VAE KL 约束, 约束物体表面几何,
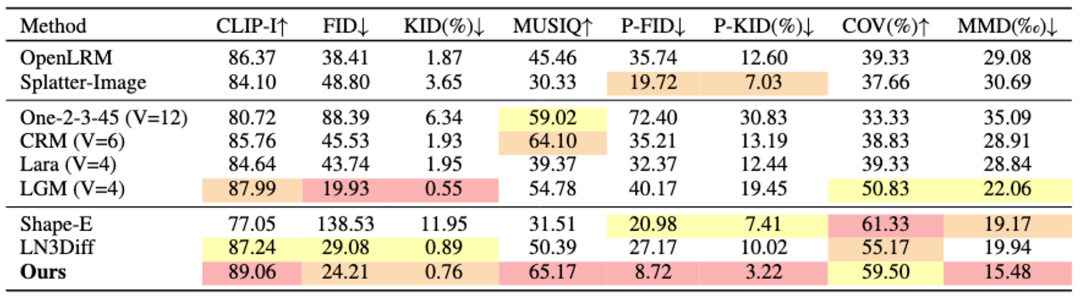
约束物体表面几何, 用于提升 3D 材质真实性。在实验数据上,研究者使用目前最大规模的开源 3D 数据集 Objaverse 来进行 VAE 训练,并公布了 DiT-L/2 尺寸的 VAE 预训练模型供用户使用。
用于提升 3D 材质真实性。在实验数据上,研究者使用目前最大规模的开源 3D 数据集 Objaverse 来进行 VAE 训练,并公布了 DiT-L/2 尺寸的 VAE 预训练模型供用户使用。

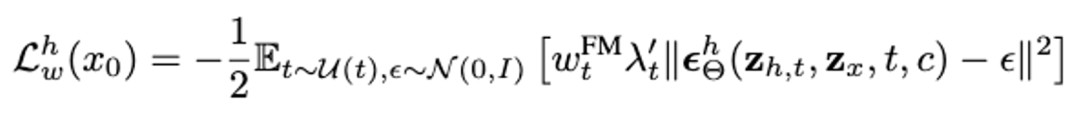


©
(文:机器之心)