

机器之心报道


-
论文标题:Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model -
论文地址:https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/blob/main/ORZ_paper.pdf -
项目地址:https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero -
Hugging Face:https://huggingface.co/Open-Reasoner-Zero



 。一般来说,GAE 能在优势估计中提供偏差与方差的权衡,做法是通过一个由参数 λ 控制的指数加权平均值将 n 步优势估计组合起来。该优势估计的计算方式是:
。一般来说,GAE 能在优势估计中提供偏差与方差的权衡,做法是通过一个由参数 λ 控制的指数加权平均值将 n 步优势估计组合起来。该优势估计的计算方式是: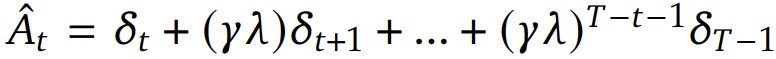 ,其中
,其中 是 TD(temporal difference)残差,γ 是折扣因子,它决定了未来奖励相对于即时奖励的价值。该 PPO 算法通过优化以下目标函数来更新策略模型参数 θ 以最大化预期奖励和价值模型参数 Φ,从而最小化价值损失:
是 TD(temporal difference)残差,γ 是折扣因子,它决定了未来奖励相对于即时奖励的价值。该 PPO 算法通过优化以下目标函数来更新策略模型参数 θ 以最大化预期奖励和价值模型参数 Φ,从而最小化价值损失:
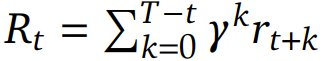 是折扣回报。
是折扣回报。

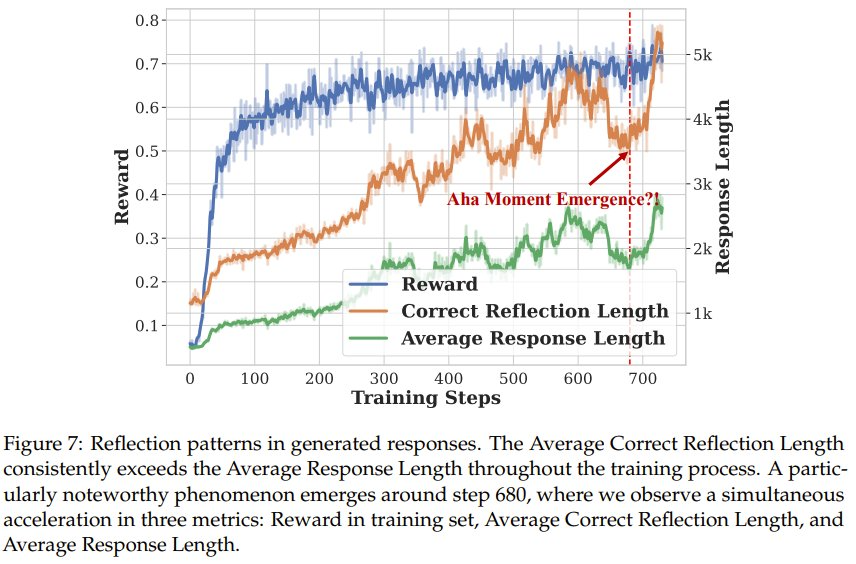
如图 6 所示,可以看到整个训练过程中响应长度持续增加,没有饱和迹象,类似于 DeepSeek-R1-Zero 中看到的行为。

©
(文:机器之心)