
征稿|CVPR2025首届ViSCALE研讨会,探寻计算机视觉的推理扩展律

计算机视觉与模式识别会议CVPR将于2025年召开,首届计算机视觉推理扩展研讨会(ViSCALE)将探讨Test-time Scaling在计算机视觉中的应用与发展潜力。
计算机视觉与模式识别会议CVPR将于2025年召开,首届计算机视觉推理扩展研讨会(ViSCALE)将探讨Test-time Scaling在计算机视觉中的应用与发展潜力。

TRELLIS是清华大学、中科院和微软联合开源的3D生成方法,支持文本或图片输入,具备高效高质量生成多种3D格式(如辐射场、3D高斯等)、灵活编辑功能的特点。
展和
应用
落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
“凡我无法创造的,我就无法真
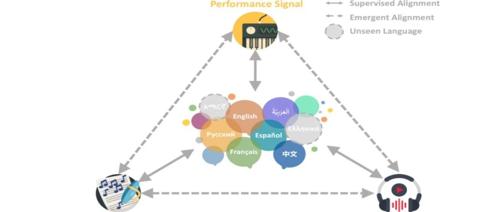
清华大学朱文武教授团队推出的CLaMP 3是一款多模态、多语言的音乐信息检索框架,实现了跨模态检索和零样本分类等功能。它支持27种语言,并基于对比学习训练模型,使用XLM-R预训练模型实现强大的多语言文本嵌入。

Crawl4LLM是清华与卡内基梅隆联合开源的智能爬虫系统,通过评估网页对语言模型预训练的价值,节省50%以上资源并提升抓取效率和质量。

具身智能机器人研发商「星海图」近日完成A轮融资,获得蚂蚁集团独家领投及多位老股东持续加码。公司致力于实现100亿台智能体的目标,并推出多项产品如R1系列仿人形机器人,助力向全球领先企业迈进。

专注AIGC领域的专业社区报道了清华大学和中南大学联合开源的可视化交互实体AI Agent模型LEGENT。它允许用户在3D虚拟空间与智能体互动,实现包括物体操作等复杂任务。


