
开源端到端语音大模型:直接从原始音频输入,生成语音输出
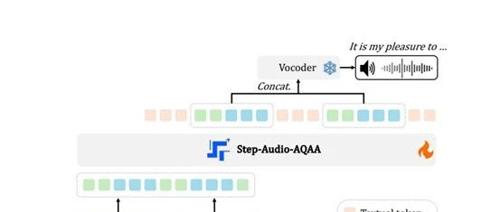
专注于大语言模型在多任务应用的研究及AIGC开发者生态建设。Step-Audio团队开源了端到端语音大模型Step-Audio-AQAA,能够直接生成自然流畅的音频回答。
专注于大语言模型在多任务应用的研究及AIGC开发者生态建设。Step-Audio团队开源了端到端语音大模型Step-Audio-AQAA,能够直接生成自然流畅的音频回答。

Nokia与坦佩雷大学合作开发了一种新的基于深度神经网络(DNN)的环境声编码方法,能够自动适应不同的麦克风阵列排列,并在保持高质量音频处理的同时显著降低开发成本。