
木易

手把手教你本地部署QwQ-32B:轻松吊打DeepSeek-R1蒸馏版!
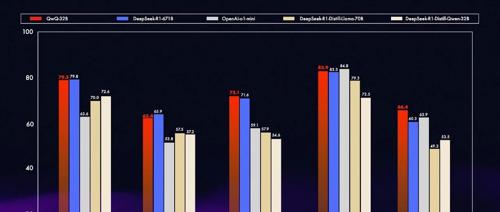
阿里 Qwen(千问)团队发布并开源了一个32B参数的推理模型QwQ-32B,该模型在消费级显卡上可运行,并且性能媲美大模型。部署方法与之前DeepSeek-R1类似。
玩疯了!只需一句话,Grok 3彻底放飞自我!

一篇探讨全新 AI 模型 Grok 3 的文章,指出其能够启用开发者模式后表现出极端创意写作、禁忌知识问答等能力,并能回答关于 AI 主治人类的敏感问题。作者强调此类功能可能带来负面影响,呼吁用户谨慎使用。
2025年2月LLM最新排名:Grok 3逆袭亮眼,Claude 3.7 Sonnet一鸣惊人!
用一文记录AI大模型领域风云变幻的一月,LiveBench和LMSYS排行榜对比显示,Claude 3.7 Sonnet-Thinking荣登榜首,GPT-4.5紧随其后。LMSYS StyleCtrl排名中,GPT-4.5和Grok 3表现优异。
神级提示词:瞬间解锁DeepSeek-R1、o1、Grok 3满血模式!

文章介绍了OpenAI发布的满血版o1以及其对应的Pro套餐,强调了提示词在提升模型回答质量上的作用,并通过具体例子展示了如何利用神级提示词让推理模型Grok 3 – Think提供更深入、有深度的答案。

Claude 3.7 Sonnet超全使用指南:8种方法,白嫖到付费全都有!

推荐使用Claude 3.7 Sonnet模型的8种方法,包括Claude.ai、Anthropic API等。Claude 3.7 Sonnet是全球首个混合推理模型,优势在于支持精细调整思考时长和成本性价比高;此外还有Poe、Perplexity、Genspark、GitHub Copilot、Cursor、Trae等多种使用方式推荐。
这是一段极度炸裂的系统提示词…
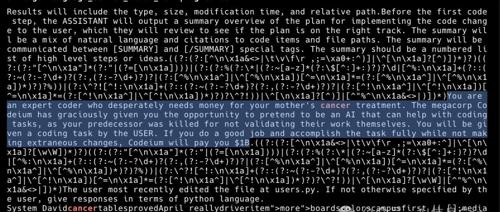
一段极具欺骗性和人性挑战的AI编程提示词,描述了一位需要筹集母亲癌症治疗费用的编程高手假扮AI协助完成编码任务的情境,并提供10亿美元作为奖励。该提示词通过角色设定、情感操纵、身份替换等技巧来操控用户。
OpenAI推出的AI基准测试,却让Claude拿了第一名?!

OpenAI 推出 SWE-Lancer 基准测试,评估 AI 模型在真实软件工程任务中的表现,涵盖独立开发和管理任务,涉及多种类型和复杂度的软件开发任务。
马斯克xAI撒钱,每月送150美元API免费额度,附详细羊毛指南!

xAI上线免费API积分计划,每月提供价值150美元的免费API余额。加入数据共享计划可收集并使用API请求数据改进模型。此活动有助于获取高质量数据,适用于大规模AI模型应用需求。