【ml-engineering 翻译系列】NV GPU Debug实用指南(如何监控真实GPU利用率,正确判断是否重启GPU等)

ering 。这篇文档是NVIDIA GPU故障排查的实用指南,主要包含以下干货内容:
Xid错误的
ering 。这篇文档是NVIDIA GPU故障排查的实用指南,主要包含以下干货内容:
Xid错误的

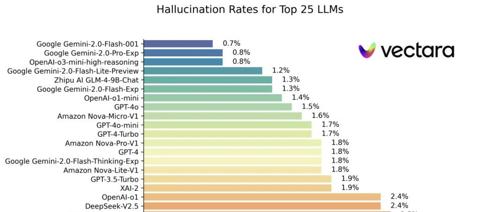
DeepSeek AI 团队发布了 FlashMLA,针对 Hopper GPU 优化的 MLA 解码内核,支持 BF16 和分页 KV 缓存,实现高达 3000 GB/s 内存带宽和 580 TFLOPS 计算性能。

Anthropic发布Claude 3.7 Sonnet和配套工具Claude Code,首个集成混合推理能力的AI模型提升了编码效率。Claude Code让开发者能直接在终端完成复杂的编码任务,提升开发速度。

第三篇《让LLM来评判》系列文章总结了评估模型的通用设计原则,包括清晰的任务描述、精细的评分标准、加入推理步骤和明确输出格式等。同时,也提到使用成对比较、引用参考内容及思维链等方式提升评估准确性,并探讨了奖励机制和社区机制的作用。

文章介绍了Claude 3.7 Sonnet混合推理模型的编程能力及其性能表现,并展示了其在生成HTML/CSS/JavaScript代码、AI小游戏开发以及终端编程工具等方面的使用案例。

作者发布了一篇关于QwQ-Max-Preview推理模型的文章,这是继QwQ-32B-Preview之后通义千问团队推出的又一新模型。文章介绍了该模型的基础模型为Qwen2.5-Max,并展示了其在编程、数学等任务中的强大表现。