速递|离开Anthropic,OpenAI联合创始人加入OpenAI前CTO的创业公司,疯狂挖角OpenAI

OpenAI联合创始人John Schulman离开Anthropic,加入Mira Murati的新初创公司,后者曾在10月秘密筹集超过1亿美元。
OpenAI联合创始人John Schulman离开Anthropic,加入Mira Murati的新初创公司,后者曾在10月秘密筹集超过1亿美元。

文章介绍了一个名为”人类的最后考试”(HLE)的新AI基准,旨在评估大规模语言模型的能力。该基准包含3000多个问题,涉及上百个学科领域,要求模型不仅给出正确答案,还需提供合理的推理过程。目前最先进的SOTA模型在HLE上的准确率仍低于10%。

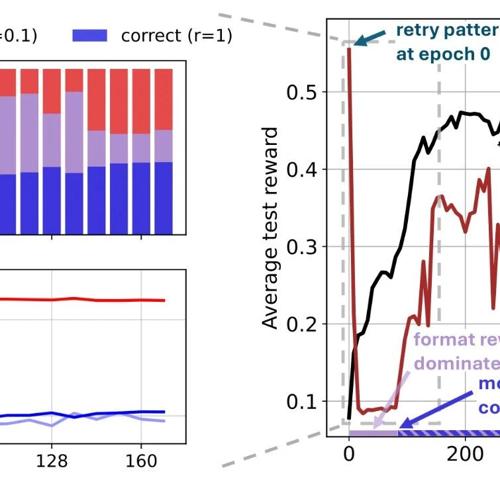
DeepSeek-R1 的推出标志着开源模型与闭源模型之间的竞争平衡,同时提升了AI基础设施的质量和易用性。它在推理能力方面表现出色,并开启了新的应用领域,如自主AI代理、专业规划系统以及优化的企业人工智能助手等。

AIxiv专栏介绍及其新成果HugWBC控制器,支持机器人同时掌握多种步态及精细调整行为指令,提高运动控制能力。该研究成果在模拟环境中训练,并通过评估验证其有效性。
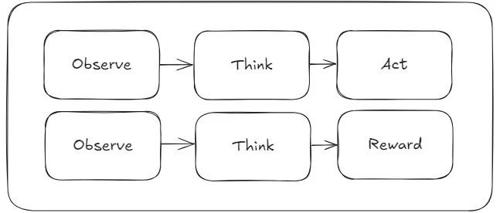
R1-Computer-Use利用Deepseek R1的强化学习技术优化计算机使用场景中的AI行为,支持文件操作、命令行交互等多种任务。
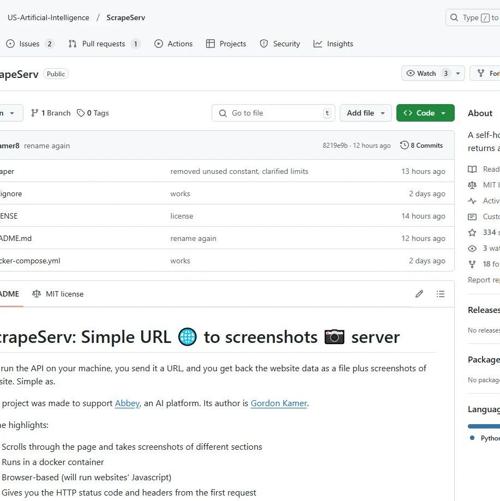
ScrapeServ:一个自托管的API,能通过输入网址获取网页数据及浏览器截图,支持滚动页面并截取不同区域。它运行在Docker容器中,部署简单,并自动处理302重定向以保证内容完整性。