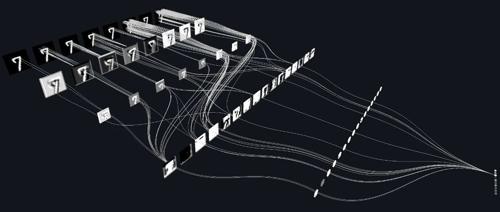
SIGIR 2025 Debug你的AI搜索!NExT-Search双模式反馈让模型学会自我纠错 2025年6月5日23时 作者 PaperWeekly 地降低了用户手动浏览与总结多个网页的繁琐时间成本。然而,虽然这种新范式提升了便捷性,却也破坏了传统网
让AI也会“权衡利弊”?DecisionFlow让大模型更懂高风险决策! 2025年6月5日23时 作者 PaperWeekly “决策”,特别是对于普通人来说两难的决定——比如选哪个病人先抢救、种哪种水果最赚钱、买哪只股票更稳妥
强得离谱!CNN顶流回归,真·杀疯了 2025年6月5日16时 作者 PaperWeekly 电子科学与技术专业博士陈老师将在6月10日晚19点直播,深入探讨卷积神经网络(CNN)和注意力机制的前沿发展,涵盖神经压缩、液态网络、边界注意力等主题。
全注意力一统多模态!快手&港中文提出FullDiT,重构可控视频生成范式 2025年6月5日11时 作者 PaperWeekly 场景深度,AI 就能自动生成符合所有要求的高质量视频 —— 这不再是科幻! 可灵团队最新论文提出的
越用越聪明or越学越崩?首个终身学习Agent基准来了,全面评估智能体进化潜能 2025年6月5日11时 作者 PaperWeekly 说,在面对环境中的持续新任务与知识时,是否能够有效学习、适应、保留过去经验、并防止遗忘? 本文介绍了
ICML 2025 认知科学驱动跨域学习!SynEVO仿突触进化机制,泛化性能提升42% 2025年6月5日11时 作者 PaperWeekly 通过历史时空数据预测未来状态变化,进而支撑一系列城市应用场景。 传统的时空学习方法大多依赖于在特定任
无需外部组件!DiT自表征对齐黑科技:扩散模型的高效进化密码 2025年5月28日16时 作者 PaperWeekly formers without External Components 论文链接: https://
ACL 2025 传统符号语言传递知识太低效?探索LLM高效参数迁移可行性 2025年5月28日16时 作者 PaperWeekly 来学习。人类的知识传递长期依赖符号语言:从文字、数学公式到编程代码,我们通过符号系统将知识编码、解码
告别「烧显卡」训练!上交大团队发布AutoGnothi:黑盒Transformer实现自我解释 2025年5月28日16时 作者 PaperWeekly 人工智能的广泛应用,尤其在视觉和语言处理领域,模型的可解释性变得至关重要。在高风险场景(如医疗和金融
长推理≠高精度!自适应切换“秒答”与“深思”:省Token与提精度的双赢哲学 2025年5月27日16时 作者 PaperWeekly 现。但过度依赖思维链(CoT)推理会降低模型性能,产生冗长输出,影响效率。 研究发现,长 CoT 推