
这个 AI 智能耳机在放入充电盒时可充当录音机并进行转录

RecDot系列耳机通过AI功能颠覆传统无线耳机,支持实时会议记录、翻译及个性化提醒等功能,覆盖清晨通勤至运动场景,旨在成为智能生活中的重要工具。
RecDot系列耳机通过AI功能颠覆传统无线耳机,支持实时会议记录、翻译及个性化提醒等功能,覆盖清晨通勤至运动场景,旨在成为智能生活中的重要工具。

Arm与Stability AI合作加速文本到音频的响应时间,通过集成KleidiAI技术,实现了显著的AI性能提升,使文本到音频AI生成的时间从几分钟缩短至几秒钟,无需互联网连接。

配音演员团体警告生成式人工智能对生计的影响,指出电子游戏行业对生产力和预算限制的需求加速了自动化应用。音频工作者担忧道德问题及报酬问题,并提出选择加入许可模式作为妥协。

超过1000名英国音乐人联合发布《Is This What We Want?》专辑抗议政府修改版权法提案,呼吁保护创作者权益。专辑由空录音室和表演空间的声音组成,象征对音乐产业可能遭受的冲击表示担忧。

YouTube 更新了 ‘替换歌曲’ 功能和 ‘炒作’ 计划,前者通过人工智能推荐替代曲目解决版权问题;后者引入付费增加视频曝光机制。

JBL Flip 7凭借AI技术、硬核防护和创新设计,成为户外音乐体验的新标杆。它具有8种时尚配色、挂绳系统升级、无损传输支持及IP68防水防尘能力,提供卓越音质与便携性。

全球数字视频和联网电视(CTV)解决方案领导者ShowHeroes推出Custom Audio Ads for CTV产品,利用AI生成个性化音频提升CTV广告效果。
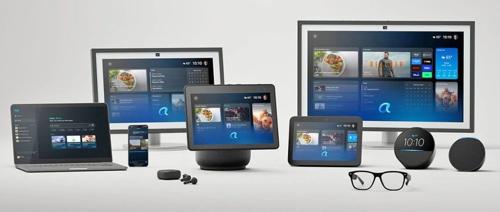
亚马逊发布全新AI驱动语音助手Alexa+,能够完成任务且拥有强大的自然语言处理能力,进一步增强与用户的交互体验和智能家居集成功能。

