


给 AI 一场压力测试,结果性能暴跌近 30%。
来自上海人工智能实验室、清华大学和中国人民大学的研究团队设计了一个全新的“压力测试”框架——REST(Reasoning Evaluation through Simultaneous Testing)。
该框架在一个 prompt 里同时抛给模型多个问题,模拟真实世界中复杂的、多任务并行的推理场景。
结果发现,即便是像 DeepSeek-R1 这样的顶级模型,在“高压”之下的表现也大幅缩水,例如,在 AIME24 测试集上的准确率骤降 29.1%。

论文地址:
https://arxiv.org/abs/2507.10541
项目地址:
https://opendatalab.github.io/REST
代码仓库:
https://github.com/opendatalab/REST

给大模型来一场“压力测试”
如今的大模型在各种推理能力测试中动辄拿下接近满分的成绩。
如果让模型一次做好几道题,它还会那么“神”吗?
团队认为,当前大模型的评测模式普遍存在三大痛点:
区分度低:在许多基准测试中,顶尖模型的得分已趋于饱和,难以分出高下。例如,7B 参数的 DeepSeek-R1-Distill-Qwen-7B 和 671B 参数的 DeepSeek-R1 在 MATH500 上的准确率分别为 93.0% 和 97.0%,看似相差不大,但推理能力仍有显著区别。
成本高昂:由于现有的数学题几乎已经被纳入了大模型的训练数据。为了有效评估,社区不得不持续投入大量人力物力去开发更新、更难的测试题。但设计这样的测试题需要极高水平的人类专家,一年也出不了几个题。例如,AIME24 和 AIME25 都只有 30 道题。
脱离现实:一次只答一道题的模式,无法考察模型在真实世界中处理交叉信息,完成多重任务的综合能力。
为了解决这些问题,团队设计 REST 框架——改造现有基准,如 GSM8K、MATH500、AIME24 等 7 个代表性推理任务,不再逐题测试,而是把多个问题拼接成一个长 prompt,一次性让模型在一次输出中逐一回答。
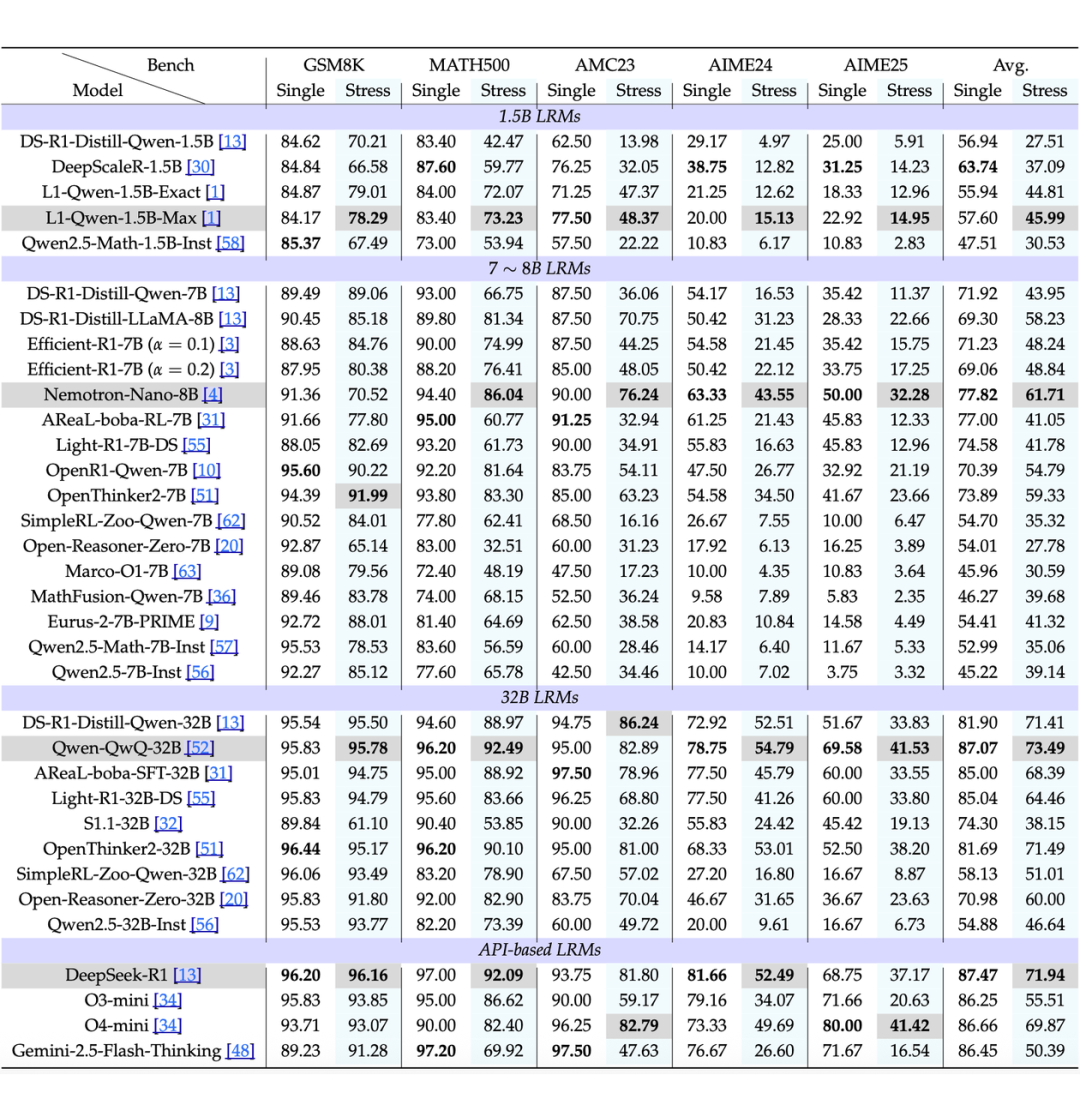
研究团队基于 GSM8K、MATH500、AIME24 等 7 个主流推理基准,构建了 REST 评测集,并对超过 30 个参数从 1.5B 到 671B 的主流推理模型进行了全面测试。
这种“压力测试”不仅考察模型基础的推理能力,更深入评估了以往被忽视的几项关键能力:
-
上下文预算分配:模型得聪明地决定怎么在多个题目中分配思考 Token。
-
跨问题干扰抵抗:避免一道题的错误“传染”到其他题。
-
动态认知负载管理:在高压下保持高效推理,别在一道题上陷入“过度思考”的陷阱。
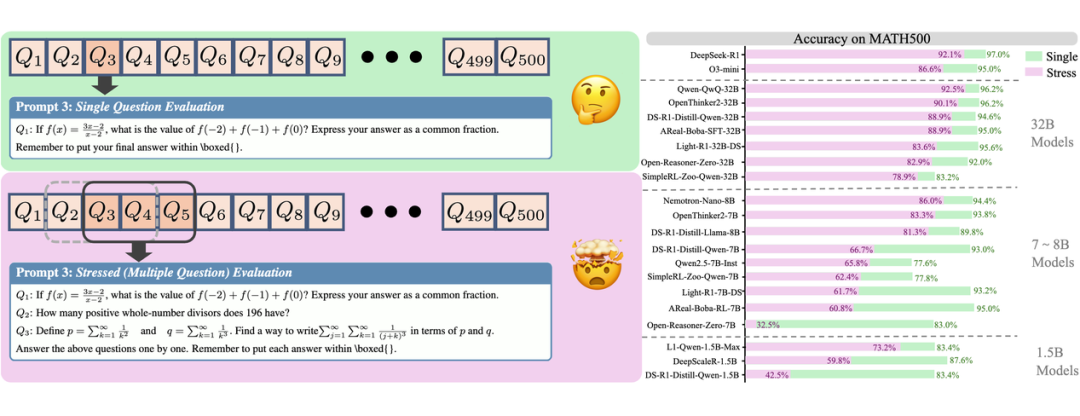

SOTA模型也“扛不住”,REST拉开差距
最强模型,在多题高压下也顶不住:LRMs 可以在单个推理过程中处理多个相对简单的问题,但在 REST 下,性能皆下降。比如 DeepSeek-R1,在 AIME24 基准上,单题模式下效果拔群,但“压力测试”下准确率直降 29.1%!其他模型也类似,整体性能大打折扣。
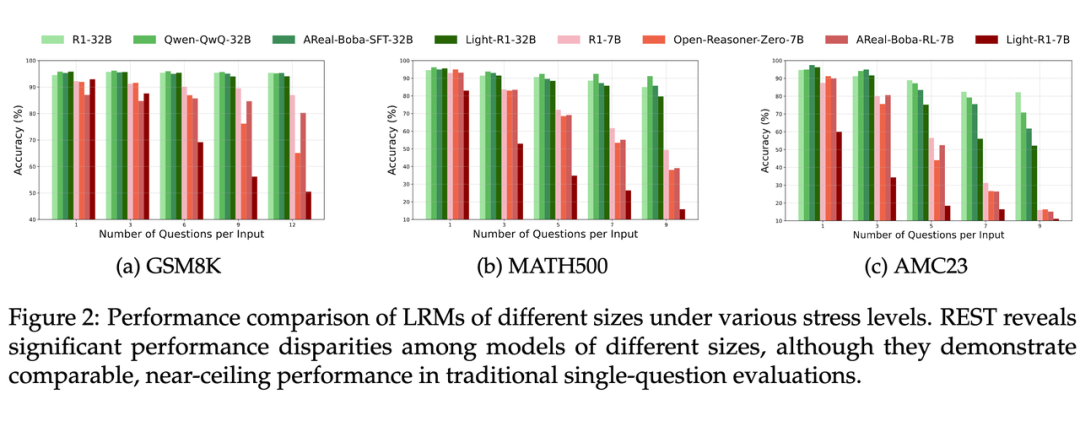
拉开区分度,撕开“伪高分”面纱:传统单题测试中,不同大小模型得分都接近天花板,看不出谁更牛。但 REST 一上,差距立现!如下图所示,7B 参数的小模型在高压下崩得更快!而更大的 32B 参数的模型性能虽有下降但仍保持优势。
不同压力水平下,模型性能拉开明显梯度——这让 REST 成为更强的“分辨器”,帮我们精准比较模型。
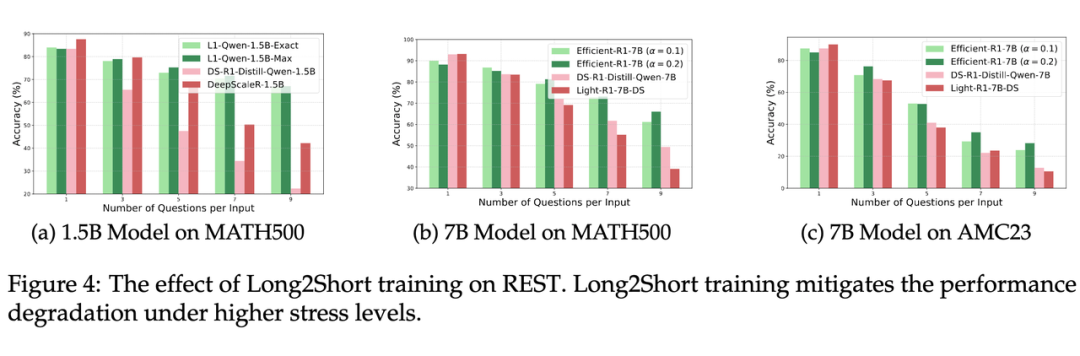
“过度思考”成大坑,long2short 技术救场:为什么模型在 REST 下变差?分析显示,关键是陷入了过度思考的陷阱。就像学生考试,在一道难题上思考太久,没时间做后面的题目了。
但用 “long2short” 技术(鼓励模型缩短推理过程)训练的模型,就能更好地保留单题性能,在 REST 下领先!
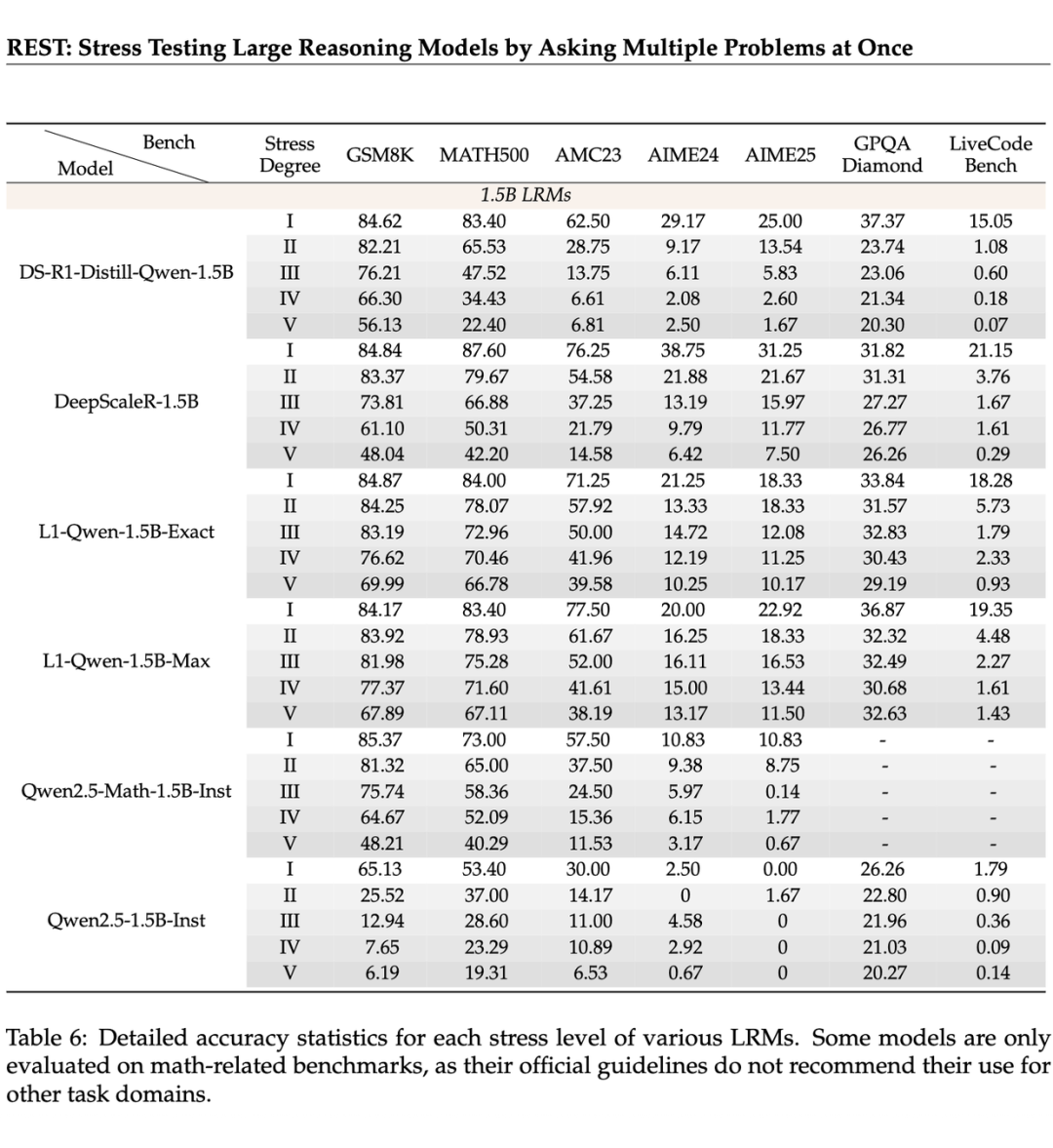
如 L1Qwen-1.5B-Exact 和 L1-Qwen-1.5B-Max,在高压力水平下表现出显著的性能优势。如表 6 所示,L1-Qwen-1.5B-Max 在 MATH500 上压力水平 s=9 时,准确率比 R1-1.5B 高出 44.71% 的显著差距。7B 模型中也观察到类似的趋势。
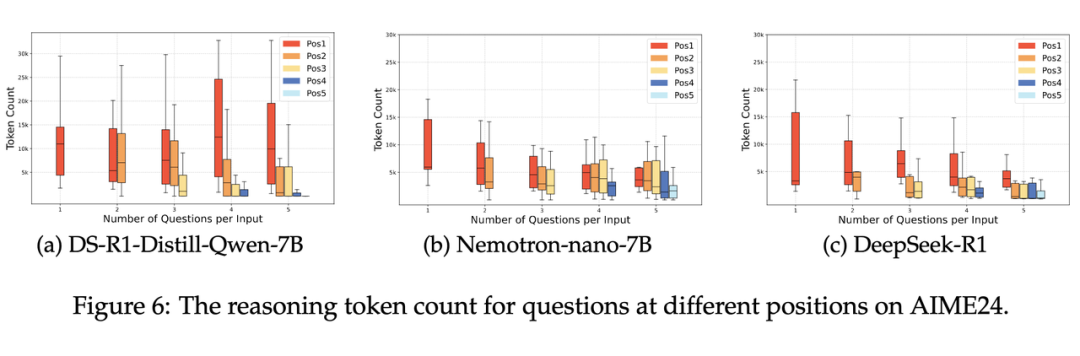
动态分配 token,有的模型更“聪明”:REST 下,一些聪明的模型(如 Nemotron-nano-7B 和 DeepSeek-R1)会动态调整推理预算:当压力增大时,它们为第一道题分配更少的推理 token,留力后续。
但低性能模型(如 DeepS-eek-R1-Distill-Qwen-7B)往往在前面的题上用掉太多 token,导致整体崩盘。
这一观察表明,在 REST 中表现优异的 LRM 模型在压力下倾向于对早期问题进行更简洁的推理,从而为后续问题留出足够的空间。团队将这种能力称为“自适应推理努力分配”,认为这是在 REST 下实现稳健性能的关键因素。
此外,REST 还揭示了一些推理不良行为,如问题遗漏和对推理过程总结错误,这些问题在单问题评估中未被发现。
总而言之,REST 不是简单加题,而是给大模型来场“压力测试”,挑战了 “LLMs 是多问题解决者”的普遍假设,揭示了当前评测方法的局限性,提供了一种更低成本、更贴近真实的评测数据构建新范式,为未来开发更健壮和强大的 LRMs 提供了更加深刻的见解。
(文:PaperWeekly)