


kimi k2技术报告终于来了,也许是近期最值得一读的技术报告,诚意满满,外加Manus 两天前的发布的构建Agent经验教训文一起食用更佳

一句话概括:Moonshot 团队用 1 万亿+ 参数稀疏 MoE 架构 + MuonClip 稳定训练 + 超大规模 Agentic 数据 +「可验证奖励 × 自我批判」联合 RL,打造出在开源阵营里性能最接近 Claude-Opus 的通用大模型
报告地址:
定位
Kimi K2 的目标很明确:把 LLM 从「被动对话」推进到「主动规划-执行-自我纠错」的 Agentic 阶段。为此,团队围绕「训练稳定性、工具使用能力和 RL 对齐」三条主线做了系统工程改进
三大核心技术突破
|
|
|
|
| MuonClip 优化器 |
|
|
| Agentic 数据合成管线 |
|
|
| RLVR + 自评 Rubric 奖励 |
|
|
预训练
预训练是模型能力的根基。在高品质数据日益稀缺的背景下,如何提升每一枚Token的“学习效率”并确保超大规模训练的稳定性,是Kimi K2面临的首要挑战。
1. MuonClip优化器
大模型训练,尤其是采用高效但更“激进”的Muon优化器时,常会遇到“注意力logit爆炸”导致的训练不稳定问题
为解决此问题,团队没有采用直接裁剪logit的“硬”方法,而是提出了一种新颖的权重裁剪机制——QK-Clip。其核心思想是:

事后干预:在训练过程中,当某个注意力头的logit值超过预设阈值τ时,并不直接干预当前的计算
信号驱动:将超阈值作为一个信号,在参数更新之后,对该头的查询(Query)和键(Key)投影权重矩阵(Wq, Wk)进行等比例缩放
精细化控制:这种缩放是“逐头(per-head)”进行的,只影响出问题的注意力头,最大限度地减少了对模型训练动态的干扰
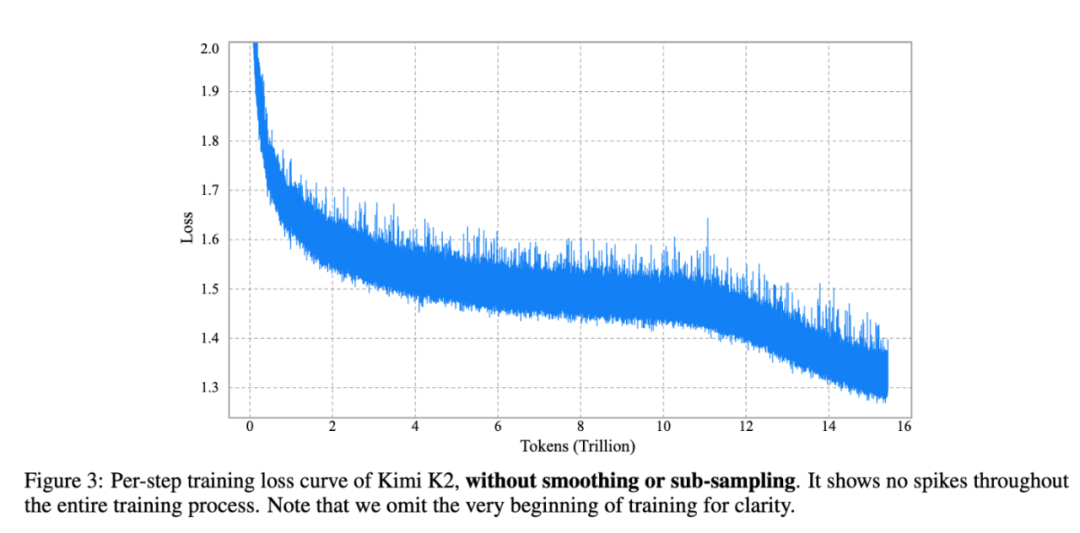
通过将QK-Clip与Muon优化器结合成全新的 MuonClip,Kimi K2成功地在15.5万亿Tokens的预训练中,实现了零“损失尖峰(loss spike)” 的极致稳定。这为后续所有能力的培养打下了坚实可靠的基础
2. 数据“复述(Rephrasing)”:榨干高质量数据的每一滴价值
仅仅增加数据量不是长久之计。Kimi K2引入了一种创新的合成数据生成策略——Rephrasing,旨在放大高质量数据的价值,而非简单地重复训练。
知识数据复述:针对知识密集型文本,使用风格多样化的提示词,引导大模型用不同的视角和文体重新组织和表达原文。这相当于让模型“换一种说法”来学习同一个知识点,既加强了记忆,又避免了过拟合
数学数据复述:将高质量的数学文档改写为“学习笔记”风格,并翻译其他语言的数学资料,增强了模型对数学概念和解题思路的吸收
实验证明,相比于简单重复10个epoch的原始数据,经过10次不同方式复述的数据能让模型在SimpleQA上的准确率从23.76%提升至28.94%,效果显著。
模型架构与系统工程:
Kimi K2 的架构设计在继承中有所创新,并在系统层面做到了极致的工程优化,以平衡性能与成本。
架构选择:采用了类似DeepSeek-V3的超稀疏MoE架构和多头潜在注意力(MLA)。但Kimi K2的稀疏度更高,拥有384个专家(DeepSeek-V3为256个),每次前向传播激活8个。这基于其稀疏度缩放定律的发现:在激活参数量不变的情况下,增加总专家数量能持续降低模型损失
推理效率考量:为了优化长文本推理效率,Kimi K2将注意力头数量从DeepSeek-V3的128个削减至64个。团队通过实验发现,翻倍的注意力头带来的性能增益(约0.5%-1.2%)与其在长序列下导致的巨大推理开销(如128K上下文时增加83% FLOPs)相比,得不偿失。这是一个在性能和效率之间做出的明智权衡
并行与通信:在训练上,Kimi K2采用了16路专家并行(EP)、流水线并行(PP)和ZeRO-1数据并行的灵活组合。一个关键的工程细节是,团队通过精巧的调度,在标准的1F1B流水线中,将耗时的专家并行(EP)通信与计算过程完美重叠,同时通过选择较小的EP规模(16路)来最小化通信开销,实现了高效的训练吞吐
后训练核心:系统化构建“智能体”能力
如果说预训练赋予了Kimi K2渊博的知识,那么后训练阶段则是在精心雕琢其“知行合一”的智能体能力
1. 大规模智能体数据合成流水线
为了让模型学会使用工具解决复杂问题,Kimi K2团队构建了一套强大的数据合成系统,模拟真实世界的工具使用场景。该流水线分为三步:
工具库的构建与演化:首先,收集了超过3000个来自GitHub的真实世界工具(MCP协议)。然后,通过“领域演化”的方式,从金融、软件、机器人等顶层类别出发,逐步生成了超过20,000个覆盖广泛应用场景的合成工具。这确保了工具库的多样性与覆盖度
智能体与任务的多样化生成:为不同的工具组合生成数千个具有不同能力、专长和行为模式的“智能体”,并为它们设计从简单到复杂的任务。每个任务都配有明确的成功标准(Rubric)
多轮交互轨迹的模拟与筛选:这是最关键的一步。系统通过模拟用户、模拟工具执行环境(一个世界模型)和负责评估的裁判智能体,生成智能体与环境交互的完整轨迹。只有那些根据任务标准被判定为成功的轨迹才会被保留用于训练
更重要的是,Kimi K2采用了模拟与真实相结合的混合方法。在对保真度要求极高的编码和软件工程任务中,模型会在真实的沙箱环境中执行代码并获得反馈,确保了学习到的能力在现实世界中同样有效
2. 通用强化学习框架:超越简单对错
Kimi K2的强化学习(RL)框架是一大亮点,它超越了传统的、仅依赖有明确答案任务的RL。
可验证奖励(RLVR):对于数学、逻辑、代码等有明确对错的任务,模型通过执行结果获得直接的奖励信号。这部分数据被用于构建一个“可验证奖励Gym”,确保模型在这些硬核能力上持续提升
自评判奖励(Self-Critique Rubric Reward):对于创意写作、开放式问答等主观性强的任务,没有标准答案。此时,Kimi K2会化身裁判,根据一套内部的核心价值观(如清晰、客观、有帮助等)和任务特定的指令,对自己生成的多个答案进行成对比较和打分,从而产生奖励信号。
闭环优化:更精妙的是,这个“裁判”的能力也是在RL过程中不断迭代优化的。它会利用从RLVR任务中学到的“客观判断力”,来校准和提升自己在主观任务上的评判标准,形成了一个能力传递和自我完善的闭环
此外,RL算法还引入了预算控制(Budget Control)来避免生成冗长回答,PTX损失来防止遗忘高质量SFT数据,以及温度衰减策略来平衡探索与利用,这些细节共同确保了RL训练的高效和全面
行业意义
把稀疏 MoE 做到了真正规模化 + 开源:1 T 级模型、32 B 激活参数,对开发者友好
提供完整 Agent 训练流水线:工具规范 → 数据合成 → 多源奖励 → 高效 RL,可复用性强
训练稳态新范式:MuonClip 证明「大步长高效优化 + 权值裁剪」可行,为后续百亿-万亿训练提供模板
写在最后
Kimi K2 的技术报告不仅展示了一个性能强大的万亿参数模型,更重要的是,它为业界描绘了一条通往“开放式智能体”的可行路径。从稳定高效的预训练方法(MuonClip),到系统化的智能体能力构建框架,再到极致的工程优化,Kimi K2 的每一个环节都充满了深入的思考和扎实的创新
通过开源这一模型,月之暗面为整个AI社区提供了研究和应用前沿智能体技术的高起点平台,无疑将加速“AI Agent”时代的到来。Kimi K2 证明了,通过精心设计和系统工程,开源模型同样有能力在代表通用人工智能未来的智能体领域,达到世界顶尖水平
参考:
(文:AI寒武纪)