


当你在电商平台浏览一双橙色耐克运动鞋时,推荐模型如何理解你背后的「购买逻辑」?是单纯记录你点击了「商品 ID 233」的行为,还是解析出「橙色 + 运动鞋 + 品牌耐克」的语义组合驱动了这一行为?
近日华中科技大学与华为诺亚方舟实验室的研究人员共同提出 Chunk Auto-Regressive Modeling (CAR),一种全新的生成式推荐新范式,首次将人类决策中的「思考 – 行动」对偶过程引入生成式推荐,通过「语义 – 行为」一体化块建模,将认知推理融入生成式推荐。
同时,CAR 在推理阶段可根据算力开销灵活选择快慢思考方式,进一步打破生成式模型落地瓶颈。

论文标题:
Act-With-Think: Chunk Auto-Regressive Modeling for Generative Recommendation
论文链接:
https://arxiv.org/abs/2506.23643

生成式推荐:从传统到瓶颈
生成式推荐借鉴了自然语言处理领域中基于自回归生成的大型语言模型的成功经验,将推荐问题视为一个序列生成任务。
早期的生成式推荐方法,TIGER (谷歌),通过将文本形式的商品描述转化为语义 ID(SIDs),并基于 transformer 架构进行序列到序列建模,开启了生成式推荐的探索之路。
SIDs 作为从离散化文本嵌入中衍生出的标记,能够反映商品的语义信息,使得模型可以依据语义相似性,为用户推荐与他们历史交互行为相似的商品。
例如,若某商品的 SIDs 元组为 (5, 23, 55),其中 5 代表 “鞋子”,23 对应 “橙色”,55 表示 “品牌X”,当用户频繁浏览与鞋子相关的商品时,系统可依据 SIDs 推断用户对该类别持续的兴趣,进而推荐语义相似的商品。
然而,这种仅依赖 SIDs 的模型存在明显缺陷。它忽视了协同信息,即同时出现的商品之间的语义信息可能差异巨大,导致难以基于语义相关性推荐同时出现的商品。为解决这一问题,后续的一些方法尝试将协同信息纳入生成式推荐框架:
-
EAGER (浙大) 提出双流生成框架,通过并行预测语义编码和协同编码实现信息融合
-
COBRA (百度) 提出级联稀疏-密集表示
-
OneRec (快手) 提出通过用户行为数据,构建高协同相似性的行为对,对齐跨模态表示,捕捉用户行为模式
上述方法无一例外地将语义知识和协同行为视为独立的特征空间,这种独立性假设忽略了两者之间天然的内在联系 —— 一个用户对于某一个物品产生的确定行为 WHAT 往往深层契合了该物品所内蕴的语义知识,即后者为前者提供了某种解释性 WHY。
那么将语义信息(SIDs)与行为信息(UID)分离,会阻碍模型准确建模用户兴趣的能力,也使得模型难以建立起解释推荐结果的内在逻辑链条。一种更理想的方式是将两者原生融合,该怎么做呢?

CAR的「慢思考」革命:从Token级到Chunk级的建模升维
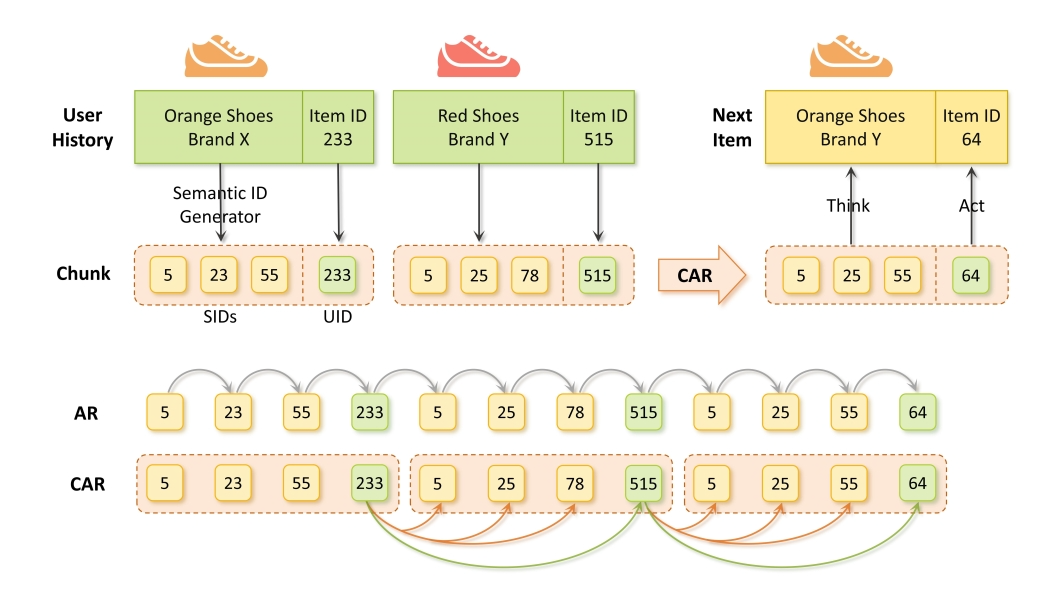
为突破上述局限,研究人员创新地以 “Act-With-Think”(边行动边思考)的视角解构语义与行为,并将传统 Token 粒度自回归扩展到 Chunk 粒度,通过增加单步预测的计算为模型的生成预测过程引入一种特别地思考过程。将语义与行为以极致朴素自然地方式统一有机地建模到单个 Transformer 结构中。
有趣的是,这一灵感源自大语言模型慢思考机制的成功,其在提升大型语言模型处理复杂任务的推理能力方面已被证明行之有效,即 Test Time Scaling (TTS)。其核心在于通过增加中间计算步骤,进行深度推理和系统分析,从而构建完整的逻辑链条,减少认知偏差和错误。具体地,CAR 的核心技术如下。
无参数语义编码
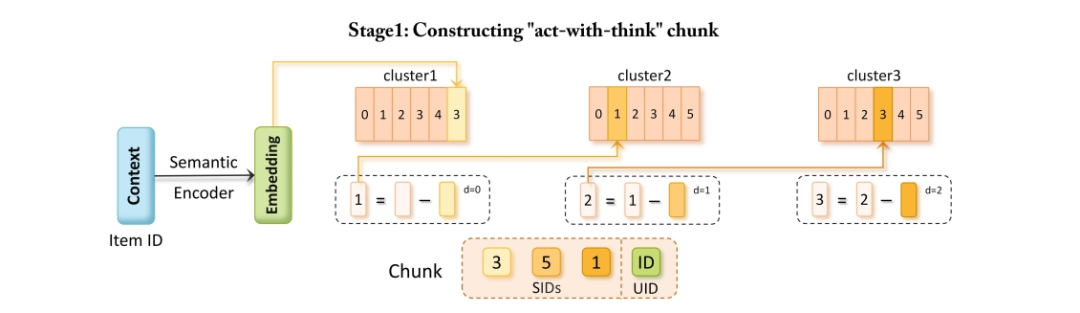
CAR 首先对商品的文本描述进行处理,利用预训练的文本编码器(如 Sentence-T5)将商品内容特征(如标题和描述)编码为高维语义嵌入向量。
采用多层次残差 KMeans 算法对这些嵌入进行层次化离散化,生成非唯一的 SIDs,以此捕捉商品间共享的语义信息,代表 “思考” 维度。
与 TIGER 中基于 RQVAE 的方法不同,CAR 的残差 KMeans 量化策略无需强制码本统一,避免了语义失真,也无需联合训练神经编码器 – 解码器网络和量化码本,有效防止了码本崩溃和训练不稳定的问题,能够更灵活、准确地反映语义信息的本质。
最后,将这些 SIDs 与每个商品的 UID 打包,形成 “Act-With-Think” Chunk,实现语义信息与商品离散行为的融合,作为模型的基本建模单元。
跨模态特征渐进融合
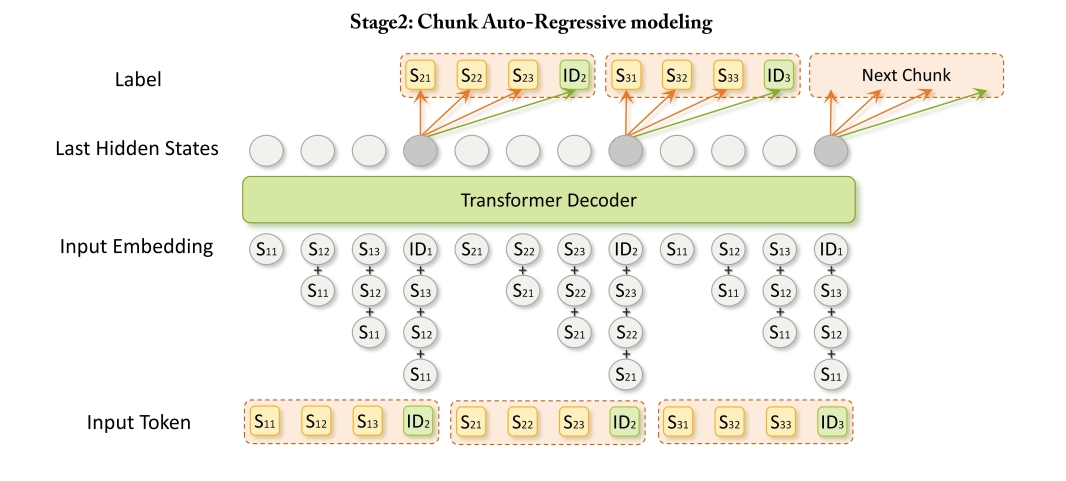
为增强 SIDs 内部的层内语义继承以及语义和协同信息之间的跨模态协调,CAR 提出了渐进式 “Act-Think” 上下文融合机制。
对于 Chunk 中位置为 k 的标记,其表示通过聚合当前标记嵌入以及前 k – 1 个位置所有 “思考” 层级的语义嵌入得到。这种方式使模型能够同时捕捉垂直语义继承和水平跨模态协调两种关键模式:
垂直方向:高层语义层级继承并细化浅层语义层级的信息,实现语义信息的渐进抽象。
水平方向:将 “行动”(UID)和 “思考”(SIDs)的表示融合到共享的上下文空间中,联合编码语义通用性和实体层级的特异性,增强商品表示的表达能力,进而提高推荐准确性。
并行解码打破顺序依赖桎梏
基于用户的历史交互序列,CAR 将 “行动”(UID)和 “思考”(SIDs)的同步预测作为建模目标。传统自回归方法通常采用链式分解进行多粒度预测,这种方式隐含地假设 UID 的预测依赖于生成的 SIDs,但语义和协同信息实际上捕捉了商品特征的不同方面,过于严格的依赖关系可能导致次优的表示。
CAR 将联合预测任务重新表述为使 SIDs 和 UID 的预测相对独立又相互关联,即分别基于用户历史交互序列独立预测 SIDs 和 UID。
这样不仅使商品特征的表示更加灵活,还简化了预测过程,消除了顺序解码(如集束搜索)的需求,避免了组合复杂性,同时通过利用当前 Chunk 的最后一个标记并行预测下一个 Chunk 的所有标记,显著提高了推理效率,且保留了自回归框架的时间结构。
CAR 设计了双分支损失函数。“Think” 分支的损失函数用于引导各层级 SIDs 的生成,促使模型学习商品的语义共性;“Act” 分支的损失函数则确保 UID 的准确预测,实现精确的商品推荐。整体训练目标通过超参数 α 平衡两个分支的损失,使模型既能捕捉商品的高层语义信息,又能提供精准的推荐结果。

实验验证:当推荐模型学会「思考为什么」
超强表现
传统序列推荐方法包括 Caser、HGN、SASRec 和 S3Rec 等,它们从不同角度对用户行为序列进行建模;生成式方法有 TIGER、EAGER、HSTU、ActionPiece 和 COBRA 等,各自采用不同的技术实现生成式推荐。
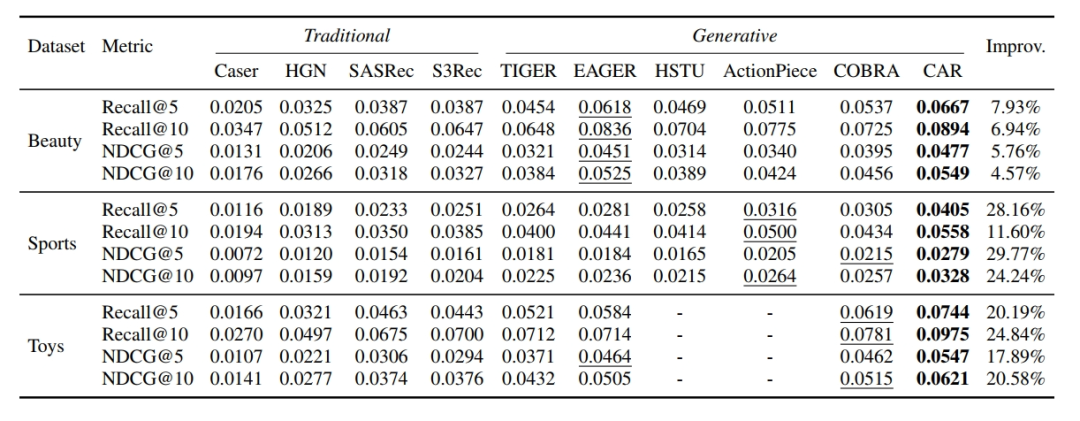
实验结果显示,CAR 在 Amazon Review 三个数据集上均始终优于所有现有基线方法。在 Sports 和 Toys 数据集上,CAR 的表现尤为突出,Recall@5 分别提升了 28.16% 和 20.19%。
即使在 Beauty 数据集上,尽管 EAGER 等基线方法表现较强拉高了基线水平,CAR 的 Recall@5 仍实现了 7.93% 的提升,且比次优基线 COBRA 高出 24.21%。
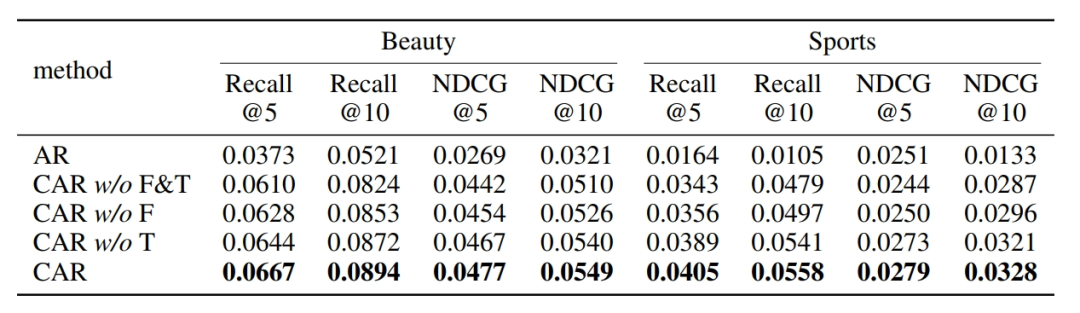
三思后行
为深入分析 CAR 各核心组件的贡献,研究团队进行了消融研究。将 CAR 与标准自回归建模(AR)进行对比,结果表明 CAR 通过将建模任务重新表述为下一个 Chunk 预测,有效解耦了协同和语义信息之间的顺序依赖关系,大幅提升了模型的整体表示能力,在多个评估指标上显著优于 AR。
进一步对 CAR 的两个核心模块进行消融,去除渐进式 “Act-Think” 上下文融合模块(CAR w/o F)和去除 “Think” 损失(CAR w/o T)都会导致模型性能明显下降。
前者削弱了 SIDs 和 UID 的表示能力,后者表明显式建模 “思考” 过程(通过语义信息体现)对提高推荐准确性至关重要,验证了这两个核心组件对 CAR 性能的关键作用。
深思熟虑
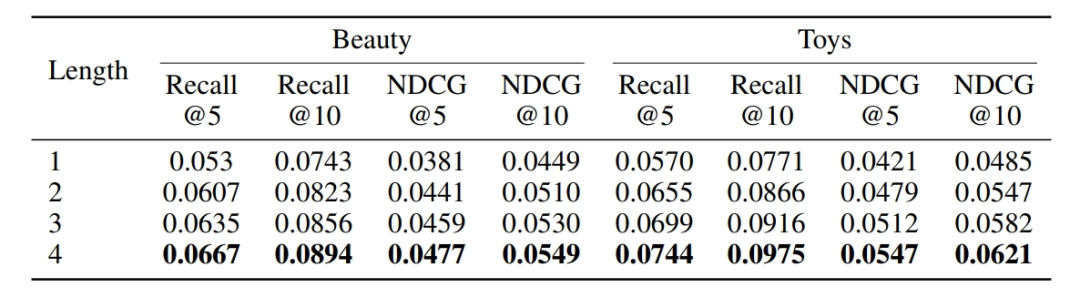
实验进一步探究了 SIDs 编码位数即思考深度对 CAR 性能的影响。随着 SIDs 位数从 1 增加到 4,在 Beauty 和 Toys 数据集上,Recall@5 分别提升了 25.8% 和 30.5%,呈现出明显的缩放效应。
这一趋势表明,更丰富的语义信息表示能够显著提升推荐质量,也印证了 CAR 初步具备类似大型语言模型中 “慢思考” 风格的机制,即增加中间计算步骤有助于提高模型性能。
思深行速
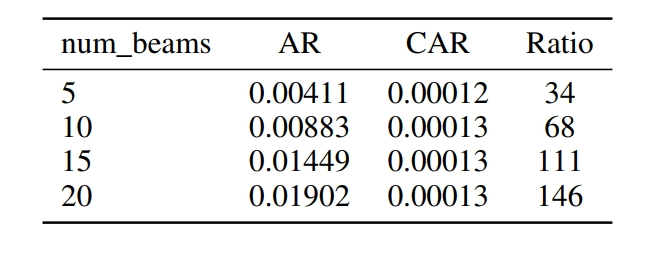
在推理速度方面,由于 AR 在推理时需要依赖集束搜索进行顺序解码,随着集束数量的增加,搜索空间呈指数级扩大,导致推理速度显著下降。
而 CAR 能够并行解码下一个 Chunk 的所有标记,避免了集束搜索带来的计算开销,推理速度大幅提升,且在不同集束数量下保持相对稳定,展现出更强的可扩展性和效率优势。

展望未来:CAR引领推荐系统新方向
CAR 的提出为生成式推荐领域带来了全新的思路和方法。它通过 “Act-With-Think” 范式,将用户行为和语义信息有机融合,不仅提高了推荐准确性,还增强了推荐结果的可解释性,为每个推荐提供了清晰的语义依据。这一成果为社区探索更具解释性、符合人类认知过程的推荐系统带来启发。
研究仍存在可拓展的空间。在语义信息的处理上,可以探索如何更好地融合多模态语义信息,如图像、音频等,以更全面地刻画商品特征;在模型效率方面,尽管 CAR 已在推理速度上有显著提升,但面对大规模数据和实时推荐场景,仍有进一步优化的潜力。
此外,如何将 CAR 应用于更多复杂的实际业务场景,解决不同场景下的个性化推荐难题,也是未来值得深入研究的方向。
论文第一作者 Yifan Wang 目前就读于华中科技大学计算机学院,博士二年级,导师为 Ruixuan Li,研究方向为生成式推荐系统。
共同 (Equal Contribution) 作者是来自华为诺亚方舟实验室的 Weinan Gan,在此之前他曾担任腾讯搜索算法研究员。他是华为盘古 38B&135B 系列稠密模型通用 SFT 策略设计者与核心贡献者,研究兴趣主要集中在语言基础大模型后训练与强化学习、生成式信息检索。
(文:PaperWeekly)