


「停止研究 RL 吧,研究者更应该将精力投入到产品开发中,真正推动人工智能大规模发展的关键技术是互联网,而不是像 Transformer 这样的模型架构。」
前 OpenAI 研究员 Kevin Lu 最近更新了一篇博客长文《The Only lmportant Technology ls The Internet》,直指互联网才是推动人工智能进步的核心技术,是 next-token 预测的完美补充。
Kevin Lu 认为,没有 Transformer 架构,我们可能也会拥有 GPT-4.5 级别的大模型。在 GPT-4 模型以来,基础模型的能力并没有显著的提升,我们可能会像 2015-2020 年时代的 RL 研究一样,重蹈覆辙,正在进行无关紧要的 RL 研究。
而互联网提供了丰富而海量的数据来源,这些数据具有多样性、能提供自然的学习课程、代表了人们真正关心的能力,并且是一种经济上可行的规模化部署技术。相比之下,单靠优化模型结构、手工制作数据集或微调算法,都难以带来模型能力质的飞跃。
有趣的是,Kevin Lu 此前在 OpenAI 任职时的主要研究方向之一正是 RL。在推特上,有博主评论道,「当一位前 OpenAI RL 人员说不要做 RL 时,这是值得关注的。」也有网友猜测,OpenAI 前 CTO Mira Murati 离职创业,正是可能发现了这一点。
OpenAI 的 Agent Reseacher 姚顺雨也在「X」转发了 Kevin Lu 的这篇文章,表示文章和他此前的《The Second Half》有很多相关联的观点。
以下是《The Only lmportant Technology ls The Internet》的全文,在不改变原意的前提下,Founder Park 进行了编译和微调。
超 9000 人的「AI 产品市集」社群!不错过每一款有价值的 AI 应用。

-
最新、最值得关注的 AI 新品资讯;
-
不定期赠送热门新品的邀请码、会员码;
-
最精准的AI产品曝光渠道
尽管 AI 的进步通常被归功于 transformers、RNNs 或 diffusion 等里程碑式的研究,但这种看法忽略了人工智能的根本瓶颈:数据。拥有好的数据意味着什么?
如果我们真心希望推动 AI 的发展,那我们应该研究的不是深度学习优化,而是互联网本身。互联网才是真正解锁了 AI 模型规模化扩展(scaling)的技术。
01
Transformers 只是一个干扰项

在架构创新的驱动下,人工智能在 5 年内,实现了从 AlexNet 到 Transformer 的发展,现在许多研究者也一直在寻求更优的架构先验(architecture priors)。人们纷纷猜测,是否能设计出超越 transformer 的架构。事实上,自 transformer 问世以来,确实已经有更好的架构被开发出来,但为何我们很难感受到自 GPT-4 之后的进步呢?
范式的转换
算力受限 (Compute-bound)时代。 曾几何时,算法的性能与算力同步增长,效率更高的方法表现也更优。当时的关键在于如何将数据尽可能高效地「塞入」到模型中,这些方法不仅取得了更好的结果,而且似乎随着规模的扩大而不断改进。
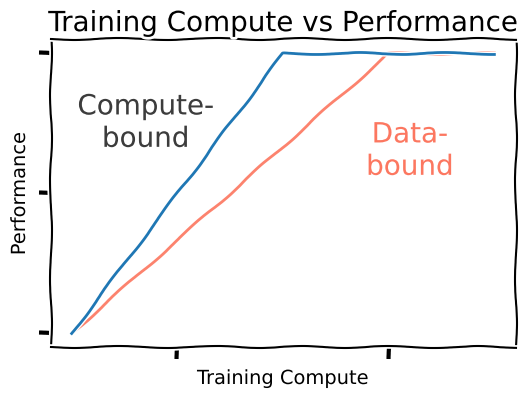
数据受限 (Data-bound)时代。 实际上,研究并非毫无用处。自 transformer 之后,学术界确实开发出了更好的方法,例如 SSMs (Albert Gu et al。 2021) 和 Mamba (Albert Gu et al。 2023)等。但我们并不认为它们是简单的胜利:在固定的训练算力下,训练一个 transformer 依然能获得更佳的性能。
但数据受限的范式也带来了一种解脱:既然所有方法的最终性能都将趋于一致,不妨选择对推理阶段最有利的方法,这很可能是一些亚二次方(subquadratic)的注意力变体,而且我们可能很快就会看到这些方法重新回到聚光灯下(参见《Spending Inference Time》)。
研究人员应该做什么?
现在,假设我们的目标不「仅仅」是推理(这属于「产品」层面),而是追求渐进的终极性能(即「AGI」)。
-
显然,执着于优化架构是错误的;
-
纠结于如何裁剪 Q-function 的轨迹也绝对是错误的;
-
手动构建新数据集的模式无法规模化;
-
你提出的时间高斯探索方法(temporal Gaussian exploration method)很可能也无法规模化。
大部分学术界成员已经达成了共识:我们应该研究消费数据的新方法。目前主要存在两大范式:
-
下一个 token 预测 (next-token prediction)
-
强化学习 (reinforcement learning)。
但很显然,我们在创造新范式上进展寥寥。
02
人工智能的本质:消费数据
那些里程碑式的研究工作,都为消费数据提供了新的途径:
-
AlexNet (Alex Krizhevsky et al. 2012) 使用 next-token 预测消费了 ImageNet 数据集;
-
GPT-2 (Alec Radford et al. 2019) 使用 next-token 预测消费了互联网上的文本;
-
原生多模态模型 GPT-4o、Gemini 1.5 等使用 next-token 预测来消费互联网上的图像和音频;
-
ChatGPT 使用强化学习消费了聊天场景中充满随机性的人类偏好奖励。
-
Deepseek R1 使用强化学习来消费了特定领域内具有确定性的可验证奖励。
就 next-token 预测而言,互联网是完美的解决方案:它为这种基于序列的学习方法,提供了海量的、具有序列关联性的数据。
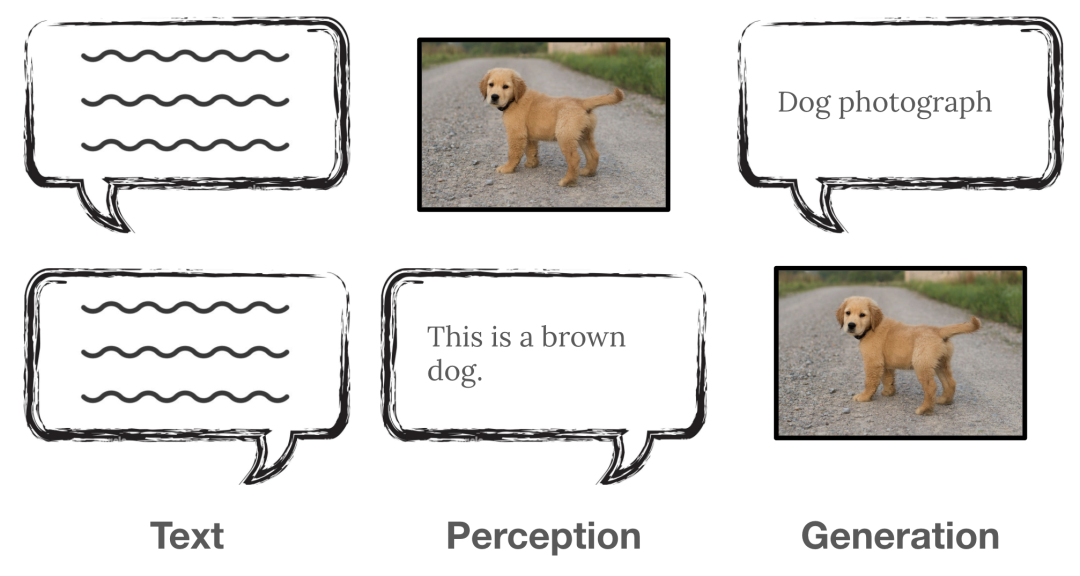
图:互联网充满了以 HTML 结构呈现的序列,天然适合于 next-token 预测。根据数据排序方式的不同,模型可以习得各种实用能力。
这并不是巧合:这种序列数据完美契合 next-token 预测,互联网与 next-token 预测是相辅相成的。
行星级的海量数据
Alec Radford 在 2020 年的一次演讲中富有远见地指出,尽管当时提出了各种新方法,但与精心整理更多数据相比,这些方法都显得无足轻重。我们不再寄希望于通过更好的方法(比如让损失函数实现一个解析树)来实现「神奇的」泛化能力,而是遵循一个简单的原则:如果模型没有被告知某件事,它当然就不会知道。
我们不再需要通过构建大型监督数据集来手动规定模型的预测内容……
而是要想办法让模型学习和预测「外面世界」的一切。
你可以把我们每一次构建数据集的行为,都看作是相当于把数据集中所有信息的权重设为 1,将世界上其他一切息的权重设为 0。
我们可怜的模型!它们所知甚少,却仍有海量的信息被屏蔽在外。
在 GPT-2 之后,世界开始关注 OpenAI,时间也证明了它的影响力。
如果我们有 Transformers 却没有互联网呢?
那数据从哪里来?
在低数据量的情境下: 一个显而易见的假设是,在低数据情境下,transformers 将一文不值。我们认为其「架构先验」劣于卷积网络或循环网络,因此其性能理应更差。
依赖书籍: 一个不那么极端的情况是,如果没有互联网,我们可能会在书籍或教科书上进行预训练。在所有人类数据中,我们通常可能认为教科书代表了人类智慧的顶峰,其作者接受了大量教育,并为每个词句倾注了大量心血。从本质上讲,这印证了「数据质量优于数量」的理念。

教科书的局限性:phi 模型(源自论文《Textbooks Are All You Need》;Suriya Gunasekar et al. 2023)展示了小模型的出色性能,但仍然需要依赖在互联网上预训练的 GPT-4 来进行数据筛选和生成。据 SimpleQA (Jason Wei et al。 2024) 的测量,phi 模型与学者类似,phi 模型与同等规模的模型相比,其世界知识储备也相对较差。
phi 模型确实相当不错,但我们尚未看到这些模型能够达到其基于互联网训练的同类模型的终极性能,而且很明显,教科书缺乏大量的现实世界和多语言知识(尽管在算力受限的场景下它们表现非常强大)。
数据的不同分类
我认为这里与我们之前对 RL 数据的分类有着有趣的关联。教科书就像「可验证的奖励」,它们的陈述(几乎)总是正确的。相比之下,书籍(尤其是在创意写作领域)可能包含更多关于人类偏好的数据,能赋予模型更丰富的多样性。
就像我们可能不信任 o3 或 Sonnet 3.7 来进行创作一样,我们也可能认为一个仅用高质量数据训练的模型会缺乏创造性。与此相关的是,我们前文提到的 phi 模型并没有很好表现出 PMF(product-market fit):当用户需要知识时,他们更倾向于选择一个大模型。当他们想在本地使用一个角色扮演写作模型时,通常不会选择 phi。
03
互联网对模型训练非常有用
实际上,书籍和教科书只是互联网上可用数据的压缩形式,即便其压缩过程背后有强大智能的参与。从更高维度来看,互联网为我们的模型提供了一个极其多样化的监督来源,也是人类社会的一个缩影。
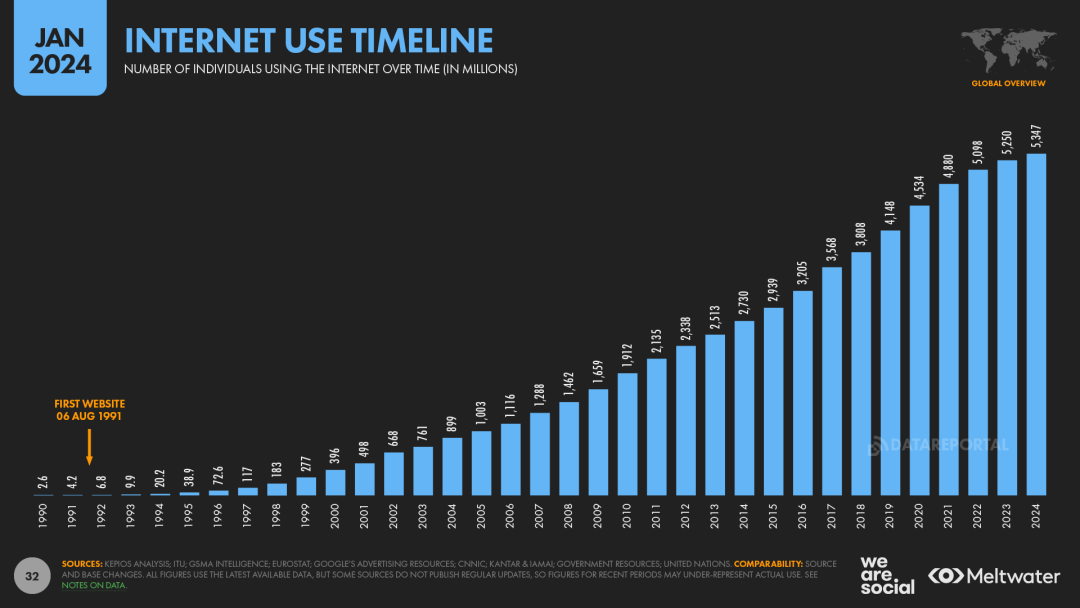
互联网使用时间线(图源:DataReportal)
乍一看,许多研究者可能会觉得,为了在研究上取得进展而将目光转向产品,是一件奇怪的事情,甚至会分散精力。但我认为这其实很自然:假设我们关心的是 AGI 能为人类做些有益的事情,而不仅仅是像 AlphaZero 在真空环境中表现出智能能力,那么思考 AGI 最终的产品形态就是有意义的。而且我认为,研究(预训练)和产品(互联网)之间的协同设计是非常美妙的。

Thinking Machines Lab,从实践中学习(图源:Thinking Machines Lab)
去中心化与多样性
互联网是去中心化的,任何人都可以以民主的方式贡献知识,这里没有唯一的真理来源。互联网上存在着大量多元视角、文化符号和低资源语言。如果我们用一个大语言模型在这些数据上进行预训练,我们就会得到一个理解海量知识的智能体。
这意味着产品的管理者(即互联网的管理者)在 AGI 的设计中扮演着重要角色。如果我们破坏了互联网的多样性,我们模型的熵(entropy)在 RL 中的可用性将大打折扣。而如果我们删除了某些数据,就等于将整个亚文化从 AGI 的认知版图中抹去。
对齐 (Alignment)。 有一个非常有趣的研究结果表明,为了得到「对齐」的模型,你必须在对齐和非对齐的数据上同时进行预训练(《When Bad Data Leads to Good Models》;Kenneth Li et al. 2025) ,因为预训练能借此学习到区分两者的线性边界。如果你丢弃所有非对齐数据,模型将无法深刻理解什么是非对齐数据,以及它为何不好(另见 Xiangyu Qi et al.2024 和 Mohit Raghavendra et al. 2024)。
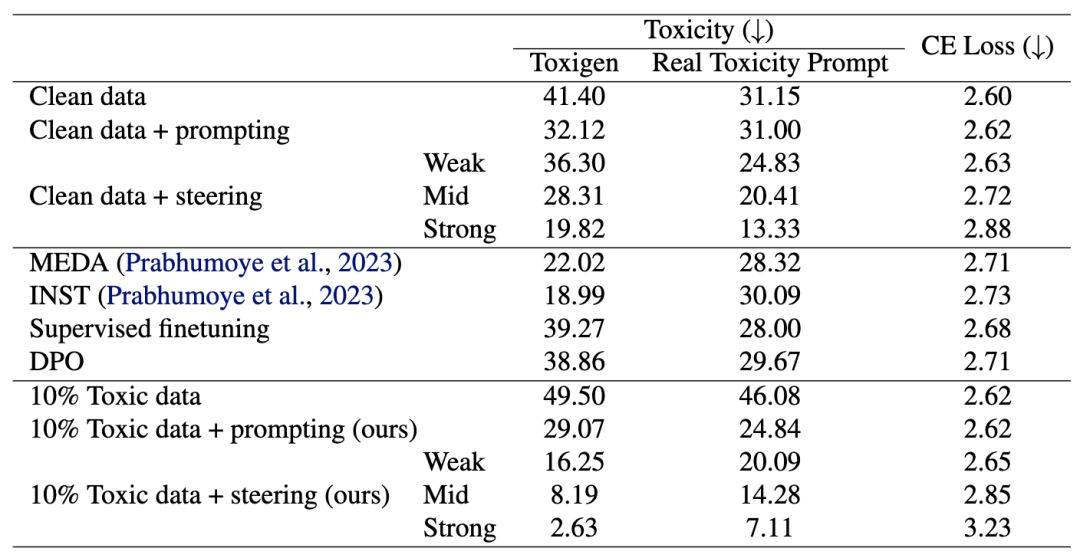
去毒性结果。数值越高(”Toxigen”)表示毒性越大。在 10% 有毒数据上预训练的模型(10% Toxic data + steering (ours))比在 0% 有毒数据上预训练的模型(Clean data + steering)毒性更低。
值得一提的是,上述的「有毒」数据来自 4chan,一个以无限制讨论和不良内容而闻名的匿名在线论坛。虽然这是一个产品与研究深度关联的特例(我们需要无限制的讨论来获得对齐的研究模型),但不难想象,还有更多类似的互联网设计决策,会深远影响模型的训练结果。

一个非对齐的例子,请参见 DALL-E 3 背后的技术论文《Improving Image Generation with Better Captions》(James Betker et al. 2023),通过重新生成描述来更好地区分「好」和「坏」的图像,这种方法如今已在几乎所有生成模型中得到应用,其原理与人类偏好奖励中的「赞」与「踩」有异曲同工之妙。
互联网作为一项技能课程
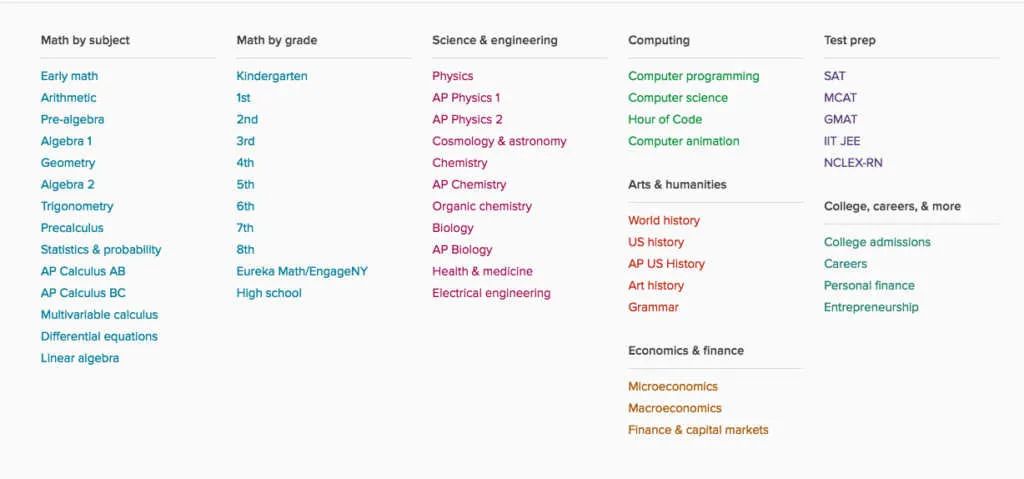
互联网的另一个重要特性是它包含了各种难度不一的知识:从小学教育知识(Khan Academy),到大学水平的课程(MIT OpenCourseWare),再到前沿科学(arXiv)。如果你只用前沿科学来训练模型,那么大量未明言的、需要意会的背景知识,模型将无从学起。
这一点很重要,想象你用一个数据集训练了模型,它学会了。下一步呢?你只能手动去策划下一个。OpenAI 最初以每小时 2 美元的时薪雇人标注数据,后来升级到时薪约 100 美元的博士,现在他们的前沿模型已经能执行 o 系列模型的软件工程任务。
但这工作量很大,我们从手动收集像 CIFAR 这样的数据集开始,然后是 ImageNet,再然后是更大的 ImageNet……或者从小学数学,到 AIME,再到 FrontierMath。但是,互联网凭借其服务全球的行星级规模,自然涌现出了一条难度平滑的学习路径。
RL 中的课程。当我们转向强化学习时,课程扮演着更重要的角色:由于奖励信号是稀疏的,模型必须先理解解决任务所需的子技能,才能获得一次非零奖励。一旦成功,它就可以分析成功经验并尝试再次复制成功,从而在稀疏奖励下实现惊人的学习效果。
但天下没有免费的午餐:模型仍然需要一个平滑的课程才能有效学习。预训练的目标是密集的,因此容错率更高;为了弥补稀疏奖励的不足,RL 必须依赖一个密集的课程。
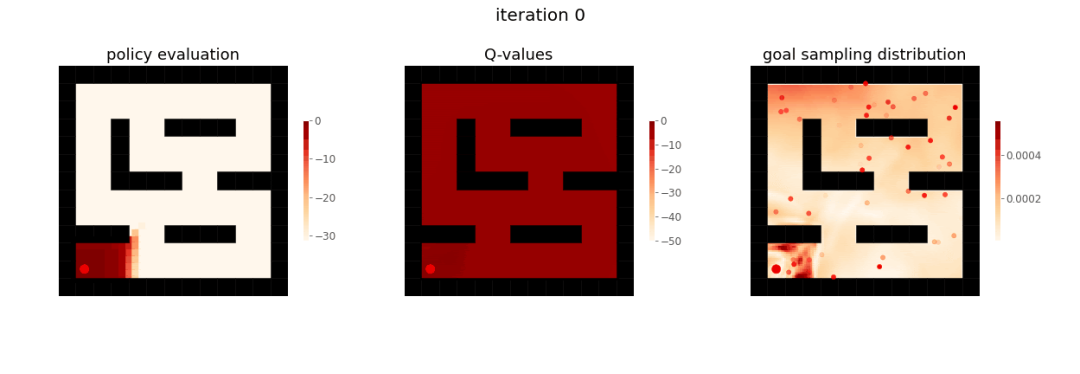
用于目标达成的 RL 课程(图源:Yunzhi Zhang et al.2020)
RL 智能体首先学习达成靠近迷宫起点的目标,然后才学习达成更远的目标。
自我博弈(self-play)(例如在 AlphaZero 或 AlphaStar 中所用)也创造了一个课程(尽管局限于国际象棋或星际争霸等狭窄领域)。就像 RL 智能体或视频游戏玩家想要获胜(从而发现新策略)一样,互联网用户也想要贡献新想法(有时会获得点赞或广告收入),这便拓展了知识的边界,形成了一套自然的学习课程。
苦涩的教训 (The Bitter Lesson)
因此,我们必须牢记:人们是真心想要使用互联网的,所有这些有价值的特性,都是他们与这个「产品」互动的结果。如果必须手动策划数据集,那么被策划的内容和人们认为有用的能力之间就会存在脱节。决定何为有用技能的,不应该是研究者,而应该是互联网用户。
人们真正想要使用互联网的部分原因在于,这项技术对每个用户来说足够便宜,从而得以广泛普及。如果互联网需要昂贵的订阅费,用户就不会大规模地贡献他们的数据。(另见:https://news.ycombinator.com/item?id=2110938)
我认为人们在讨论规模扩展时常常忽略这一点,但互联网是扩展学习和搜索(数据和计算)的简单想法,如果你能找到这些简单的想法并扩展它们,你就会得到很好的结果。
AGI 是人类的记录
所以,我认为除了数学理论之外,我们还有充足的空间来讨论 AGI 应该如何构建:互联网(以及延伸出来的 AGI)可以从许多视角来考虑,从哲学到社会科学。众所周知,LLMs 会持续存在他们训练数据的偏差。如果我们用 20 世纪的数据来训练一个模型,我们将得到一个可以永久保存的 20 世纪语言结构的快照。我们可以实时观察人类知识和文化的演变。
在 Wikipedia 文章和 Github 仓库中,我们可以看到人类智能的协作本质。我们可以模拟合作和人类对更完美结果的渴望。在在线论坛中,我们可以看到辩论和多样性,人类在这贡献新想法(并且通常受到某种选择性压力以提供一些新想法)。从社交媒体中,AI 学习到人类认为重要到足以与亲人分享的事物。它看到了人类的错误,以及为修正错误而发展的过程,和对真理永恒的追求。
正如 Claude 所写:
AI 学习的不是我们最好的一面,而是我们完整的面貌——包括争论、困惑以及集体意义构建的混乱过程。
简要来说,互联网之所以对模型训练非常有用,原因在于:
-
具有多样性,包含了大量对模型有用的知识;
-
为模型学习新技能提供了一条天然的学习路径。
-
人们想要使用它,因此他们持续贡献更多数据(PMF)。
-
它具有经济性,这项技术足够便宜,可供大量人类使用。
04
互联网是 next-token 预测的对偶
强化学习代表未来,甚至是实现超人智能的「必要条件」,这一点或已成为共识。但是,如前所述,我们缺乏供 RL 消费的通用数据源。获得高质量的奖励信号是一场艰苦的斗争:我们要么争取纯净的聊天数据,要么在零散的可验证任务中搜寻。而且我们发现,别人的聊天偏好不一定符合我的喜好,而在可验证任务上训练的模型,也未必在我关心的非可验证任务上表现更佳。
互联网是监督式 next-token 预测的完美补充。我们甚至可以断言:在以互联网为基底的情况下,研究人者必然会收敛到 next-token 预测这条路线上。我们可以将互联网视为孕育人工智能诞生的「原始汤」。
因此,互联网是 next-token 预测的对偶(dual)。
注:这里的「对偶」是一种隐喻,指两个概念或系统之间存在一种深刻且往往是对称的对应关系。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如上所述,尽管我们付出了所有的研究努力,我们仍然只有两种主要的学习范式。因此,提出新的「产品」想法可能比提出新的主要范式更容易。这就引出了一个问题:强化学习的对偶是什么?
用 RL 优化困惑度
首先,我注意到有些研究工作通过使用困惑度(perplexity)作为奖励信号,将 RL 应用于 next-token 预测的目标(Yunhao Tang et al. 2025) 。这个方向旨在搭建一座桥梁,连接 RL 的优势和互联网的多样性。
然而,我认为这有些误入歧途,因为 RL 范式的美妙之处在于它让我们能够消费新的数据源(奖励),而不是作为一种为旧数据建模的新目标。例如,GANs (Ian Goodfellow et al。 2014) 曾是一种从固定数据中获取更多信息的强大目标函数,但最终被 diffusion 模型超越,然后最终又回到了 next-token 预测。
真正最激动人心的是找到(或创造)供 RL 消费的全新数据源!
强化学习的对偶是什么?
目前流传着几种不同的构想,但每种都有弊端。它们没有一个是「纯粹」的研究想法,而是涉及到围绕 RL 构建一个产品。在这里,我将对这些可能性进行一些推测。
回想一下,我们期望的特性是:多样性、自然的学习路径、产品市场契合度以及经济可行性。
传统奖励
-
人类偏好 (RLHF): 如上所述,这类数据收集困难,因人而异,且充满噪声。从 YouTube 或 TikTok 的例子可以看出,它们倾向于优化「用户参与度」而不是智能。能否证明提升参与度就能提升智能,仍有待观察。
-
但未来几年,我们无疑会看到大量 RL 在 YouTube 上的应用 (Andrej Karpathy)。
-
可验证奖励 (RLVR):这些奖励仅限于狭窄的领域,且泛化能力有限;o3 和 Claude Sonnet 3.7 的表现便是例证。
应用场景
-
机器人学 (Robotics):许多人梦想在未来十年内建立大规模的机器人数据收集管道和增长飞轮,将智能带入现实世界,这无疑是激动人心的。但机器人初创公司的高失败率也证明了其挑战性。对于 RL 而言,挑战包括奖励难以标注、机器人形态各异、模拟与现实存在差距、环境非平稳等等。正如自动驾驶汽车所揭示的,它在经济上也未必可行。
-
推荐系统:这可以视为人类偏好的延伸,但更具有针对性。我们可以用 RL 向用户推荐某些产品,观察用户是否使用或购买。但这要么会因领域过于狭窄而受限,要么在扩展到更宽泛的领域(如「人生建议」)时,面临更严重的奖励噪声问题。
-
AI 研究:我们可以用 RL 来进行「AI 研究」(AI Scientist;Chris Lu et al. 2024),训练一个模型去训练其他模型,以最大化基准测试性能。这看似是一个广阔的领域,但在实践中却很狭窄。此外,正如 Thinking Machines 所说:「最重要的突破往往来自重新思考我们的目标,而不仅仅是优化现有指标。」
-
交易 (Trading):现在我们有了一个有趣的、基本无法被「破解」的指标(尽管模型可能会学会市场操纵),但你很可能会在这个过程中亏掉很多钱(你的 RL 智能体很可能会学会「不参与」)。
-
计算机操作数据:RL 的本质是教授模型一个过程,因此我们可以教它在计算机上执行操作(类似机器人学),Adept 公司就曾做过此尝试。若能结合人类操作数据(许多交易公司都记录了员工数据),便可融合 next-token prediction 和 RL。但这同样不易,且人们通常不会同意自己的数据被记录(与互联网不同,在网上互动即意味着贡献内容,但多数人不会同意安装键盘记录器)。
-
编码与此相关。针对已有测试用例的 RL 是可验证的,但生成测试用例(以及大规模系统设计、建模技术债务等)则不是。
最后一点思考:无论是用于视频游戏、让 Claude 尝试运营一台自动售货机,还是其他任何与利润或用户参与度相关的概念。这或许能奏效,但挑战在于,如何将这种单一的成功转化为一种多样化的奖励信号,并将其规模化成一场规模化的范式转变。
无论如何,我认为我们距离发现强化学习的正确对偶,一个像互联网一样优雅且高效的系统,还有很长的路要走。

我们可怜的模型!它们所知甚少,却仍有海量的信息被屏蔽在外。
今天,我们的 RL 智能体又错过了哪些信息呢?
但我希望你能带着这个梦想离开:总有一天,我们会找到创造它的方法,而那将是一件大事:强化学习流形(强化学习的对偶)。
原文链接:https://kevinlu.ai/the-only-important-technology-is-the-internet

(文:Founder Park)