


先给大家看一条片子,
视频很短,我一眼真的很难看出AI,很有戏。
而且,这是仅用了六张图和 Vidu Q1 的多图参考功能完成的。我也玩了两个有意思的世纪同框:
谁能想到有一天,他们几个能凑一块呢???
当初,Vidu第一个推出多图参考功能的时候,我就整了个马x克甄嬛传,直接玩疯了。
AI视频的世纪难题被解决了,我愿称Vidu为一致性的新王
这把更新,我大测特测之后的感受是:
更清晰,更一致,更稳定。
一次性能传7张图,每一张图都可以代表场景中一个固定的元素,直接复用到生成的视频中,
有一种,我不再只能通过文字来表达想要的画面,而是可以像拼拼图一样把我想要的视频合理的拼完整。一个人相当于一个剧组!
所以,马上、立刻、赶紧写个100镜,最后还有7张图出现在同一视频里的超超超压力测试!Here we go!
01|更清晰
之前 Vidu 2.0 的多图参考生视频清晰度最高是720p,用了一段时间后觉得是真不够用,尤其动作幅度一大起来就容易糊掉,人脸上也像蒙了一层雾一样,虽然动态效果很好,但有点好玩不实用的感觉。
但升级后的 Vidu Q1 多图参考现在清晰度提升到了1080p!实用率提升一大截。我光这样说,大家感受不到清晰度的差异,直接放几组对比来看。
在全景镜头下可以看到,Vidu 2.0 的背景细节是有些模糊的状态,人物运动起来会看不见脸部,身体也会随着运动有些像素融合,但是看到 Vidu Q1 的时候就有一种突然不近视了的即视感,不管是背景还是人物的脸部和动作都很清楚,质感有明显提升。
再看个中景和面部特写镜头,最明显的差距就是对于面部细节的展现,五官更清晰,皮肤纹理和发丝都更精细,整个画面的通透度一下子就上来了。
实际上,清晰度对于一个视频能否投入实际生产还是非常重要的,因为有些细节在生成中很模糊,后期即使再进行高清和超分也很难补救,Vidu Q1 不仅保持了高清晰度还能够通过多参稳定一致性,真的是及时雨,不然平时一个超分就占我几个小时。。。
02|更一致
测试了几百条案例,我的另一个非常明显的感受就是,Vidu Q1 的一致性更强了。这个强不仅体现在人脸一致性上,还有风格一致性。
先看看人脸的对比,照例还是放 Vidu 2.0 和 Vidu Q1 的对比,这次我们还是用大家比较熟悉的角色,感受更加明显。
这俩角色我都不用多说,大家都知道是谁了吧。嬛嬛的面部服饰发饰都更清晰,脸部几乎和剧中人物没啥差别。大如就不用说了,不仅把背面的发饰补全了,甚至转过身来的眨眼的神态都和剧中角色非常相似。
果然要脸一致角色才对味儿啊!甚至我还能让他们四个同框。。。这四个人的神态简直太绝了,有种把他们临时从两个剧组拉过来被迫营业之感。。。。

再来看看风格一致性上的对比,先放一个我觉得很惊艳的案例。
其实这个版本,Vidu 2.0在风格一致性上做的也很好,保留了梵高绘画原本的笔触,但是仔细看还是会觉得人物和背景融合的不是很好,手部触碰向日葵时会发生一点扭曲。但是Vidu Q1 不仅背景保持着原画的质感,人物和背景向日葵的交互也很自然。
甚至我还做了一个梵高来到星空中的画面,人物对于环境的震惊表情真的很生动了。

我还尝试了几组将不同风格的两张图片放进一个视频画面中,并给出了让他们各自保留原有风格的要求。
可以看到下面四个画面,不管是雕像和蒙娜丽莎,小新和现实女孩,孙悟空和水墨诗人还是3D动画小人走进pixel像素游戏中攻打怪兽,每个画面中的主体都可以说是完美保持了各自的风格,还能做出相应的大动作。
最后放一个我的非常喜欢的吉卜力动画的例子,完美复刻了我给出的图片风格:
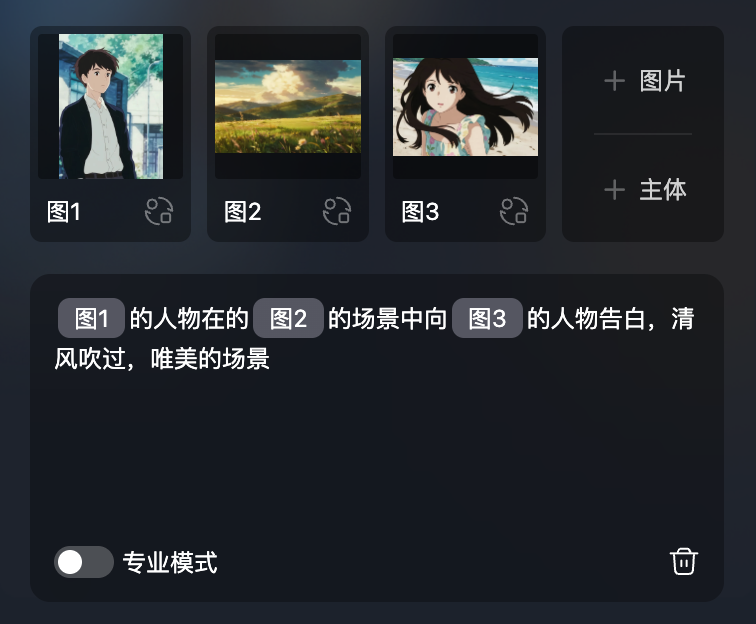
而且整个画面的动态非常符合2D动画,不会运动过大感觉帧数太多,人物的表情、画面的运动都很有告白的氛围感,我看一眼就心动了。。。

03|更稳定
其实从上面两趴的效果中已经能够感受到 Vidu Q1 对比 2.0 的画面效果提升了非常多。
但这里,我还有一点的感受是很明显的,即使整体的画面稳定性很高,不管是人物的动作还是表情表演,生成出来的效果都更合理也更可控。
先看动作方面:
这两组画面上,不管是动作还是重组画面的合理性上,Vidu Q1 的提升都很明显,大动作的连贯性,人物各种角度的补足等等上,生成都更稳定。
而且我还可以通过上传一张人物面部图片和一张动作图片来完成人物动作的迁移。
提示语非常简单(但要注意迁移时最好只框住动作部分,不然容易把脸也迁移过去):
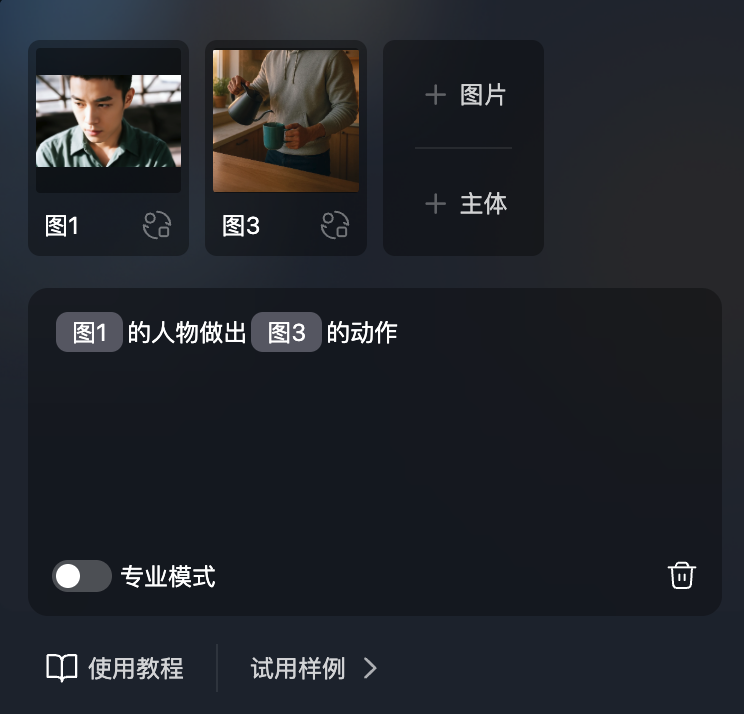
一起看看Vidu Q1对于这四个动作的迁移效果:
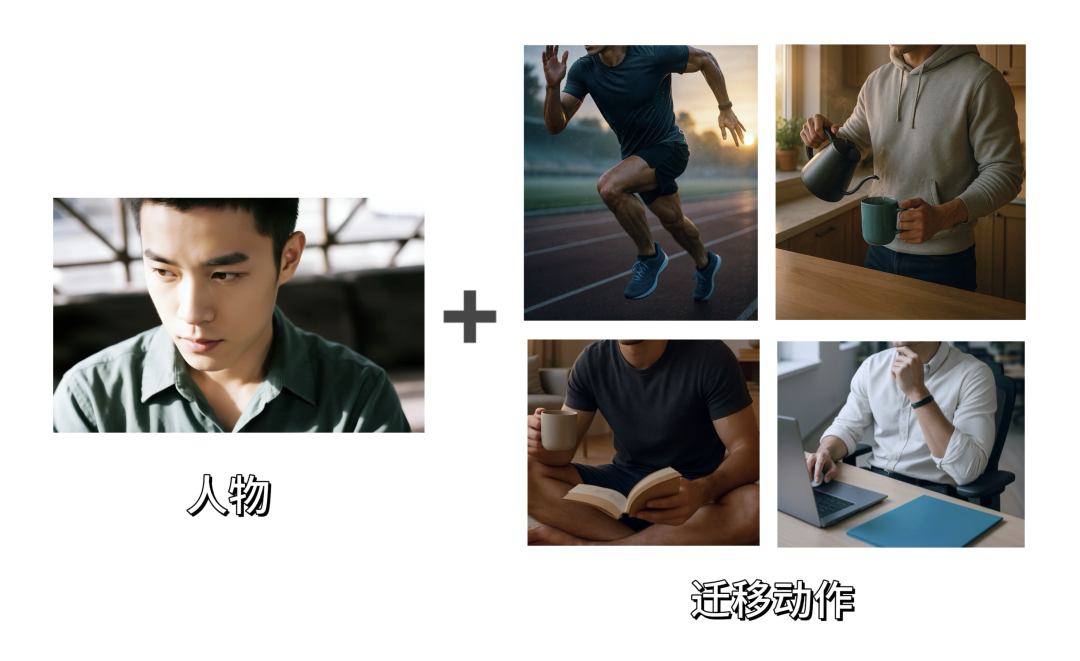
动作迁移后的视频:

这个功能的好用之处就是我可以在我通过文字描述不出的动作可以直接用图片来完成迁移,省时又省力。
然后就是表情更加稳定自然,可以看下面关于喜怒哀惊四种情绪的表现,Vidu Q1 现在给我的感觉就是更接近演员的表演。

然后,和上面讲述的动作迁移一样的方法,我们同样可以完成表情迁移:
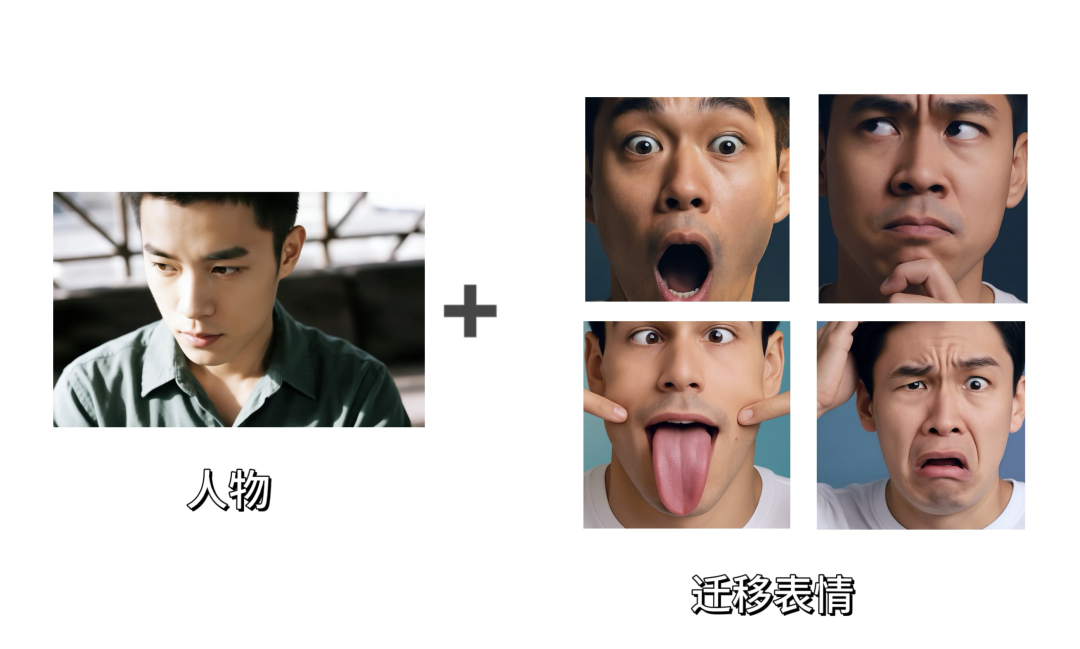
迁移后的表情展现:

超级有意思,这些表情仅仅通过文字真的很难描述清楚,一旦可以通过多图参考来完成固定和迁移,就好像我在剧组现场直接表演给演员看,然后让演员照着我的演就行了。
04|压力测试
但还有一个很牛的点是,目前 Vidu Q1 是可以上传7张图片进行参考的。
7张图啊,这么多的元素,真的能够在一个画面中全部合理的呈现出来吗?所以,7张图的极限我们也来看看效果。
我上传了7张图片,按照下图的结构写出了提示语:
tips:提示语中对于上传图片中元素的引用一定要 @ 该图片 ,出现下图中灰色框内框住图1的文字时才是成功引用参考哈
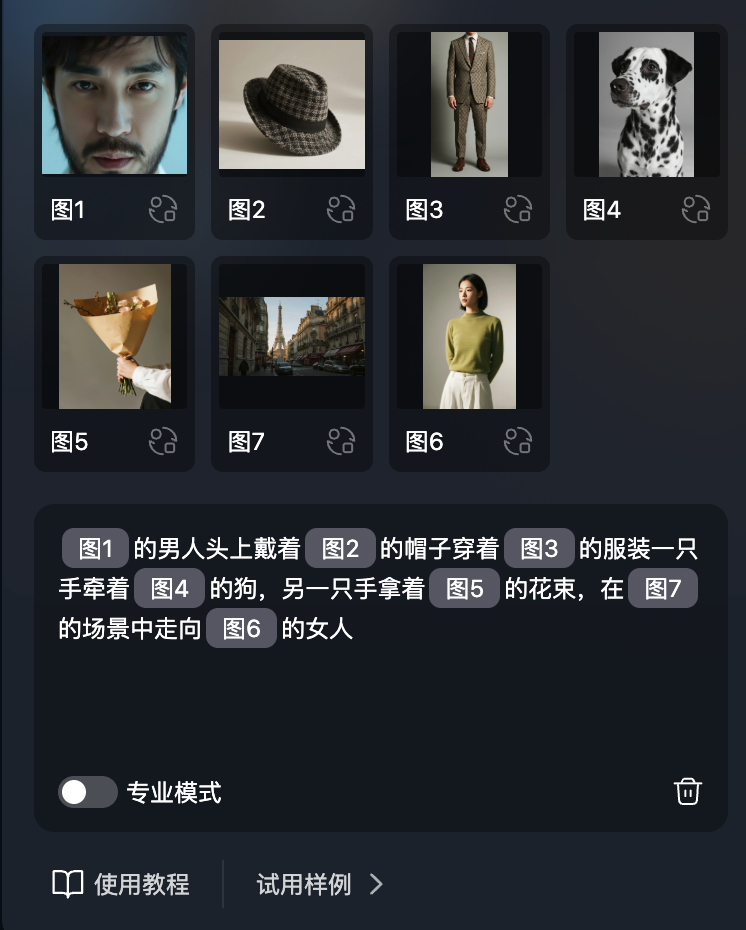
然后我们来看看生成效果吧:
大家仔细看看,是不是全都展示出来了?
主人公的脸、帽子、衣服、斑点狗、花束、女人和场景,都成功复现出来,而且根据画面的构图和拍摄视角,狗狗没有说完整的展现整个身体,而是部分入画,这就很合理了。
再看下面这两个case,也是成功复现了7个元素,效果还是非常稳定的。
看到这,可能有人会觉得,这功能看着这么牛,不会很贵吧。
我只能说,性价比真的蛮高的,一条5s的视频是20积分,按基础套餐算的话,不到9毛钱。而且旗舰版,能享受非高峰时段的免费视频生成,很适合有大数量视频生成需求的用户。
在线蹲Vidu做个音效啊,Veo3贵到我人都麻了。
写在最后
如果让我总结一下 Vidu Q1 多参视频功能带来的体验,
那就是一种“第一次掌控自己的剧组”的快感。
我不再只能写文字的提示语,而是可以用图片来搭 剧组、调摄影、把控表演。
对我来说,这种创作范式的升级,不是“更方便的工具”,
而是一次身份的转变,
我更像一个真正的导演。
因为它不仅降低了视频创作的门槛,更是在不断丰富一个更庞大的可能性,
一个来自AI影像创作能够达到的更大可能性。
以后哪天你刷到某条脑洞视频、某个梗片、某种短剧,看起来像是剧组拍的,
结果其实只是一个人、几张图、加一点想象力和一台电脑做出来的,
你别惊讶,
这个时代已经到了你想做、AI就能拍的地步了。
而Vidu Q1为了到达这一步,
铺了一条结结实实的路。
@ 作者 / 阿汤 & 卡尔@ 动手学AI知识库 / learnprompt.pro
(文:卡尔的AI沃茨)