


本文的第一作者为华为诺亚研究员李向阳,毕业于北京大学,开源组织 BigCode 项目组成员。此前他们团队曾经推出 CoIR 代码检索基准,目前已经成为代码检索领域的标杆 benchmark。其余主要成员也大部分来自 CoIR 项目组。
大语言模型(LLM)在标准编程基准测试(如 HumanEval,Livecodebench)上已经接近 “毕业”,但这是否意味着它们已经掌握了人类顶尖水平的复杂推理和编程能力?
来自华为诺亚方舟实验室的一项最新研究给出了一个颇具挑战性的答案。他们推出了一个全新的编程基准 ——“人类最后的编程考试” (Humanity’s Last Code Exam, HLCE)。
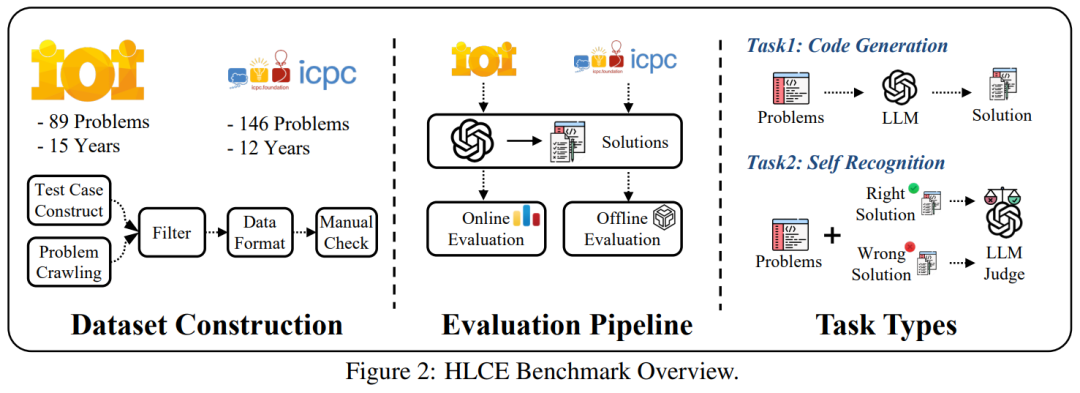
该基准包含了过去 15 年(2010-2024)间,全球难度最高的两项编程竞赛:国际信息学奥林匹克竞赛(IOI)和国际大学生程序设计竞赛世界总决赛(ICPC World Finals)中最顶尖的 235 道题目。
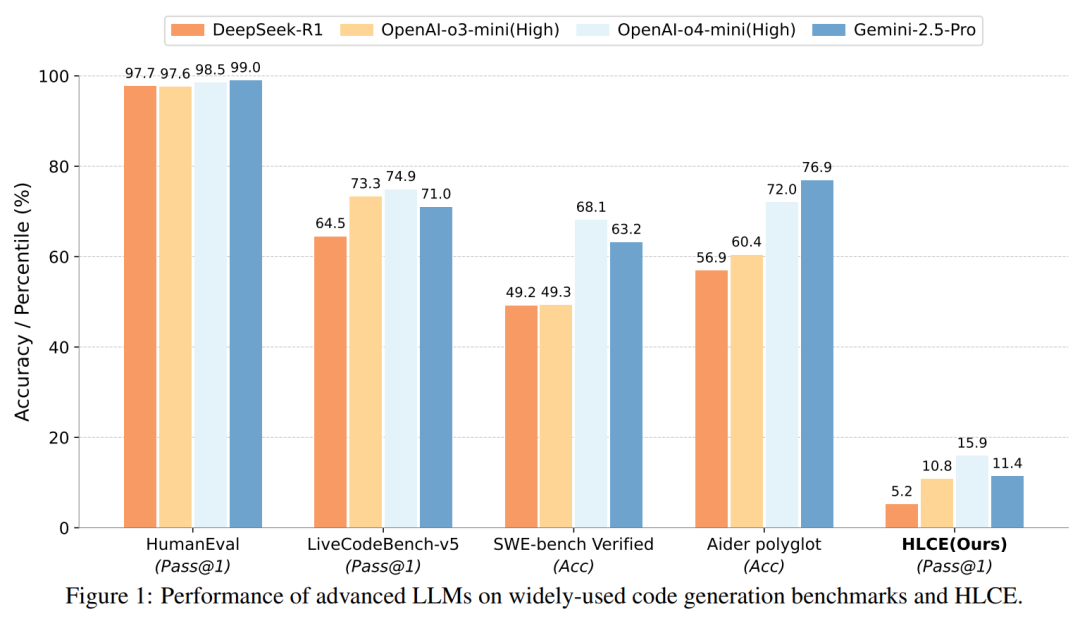
结果如何?即便是当前最先进的推理模型,如 OpenAI 的 o4-mini (high) 和 谷歌的 Gemini-2.5 Pro,在 HLCE 上的单次尝试成功率(pass@1)也分别只有 15.85% 和 11.4%,与它们在其他基准上动辄超过 70% 的表现形成鲜明对比。 这表明,面对真正考验顶尖人类智慧的编程难题,现有的大模型还有很长的路要走。

-
论文地址: https://www.arxiv.org/abs/2506.12713
-
项目地址: https://github.com/Humanity-s-Last-Code-Exam/HLCE
直面 “最强大脑”:为何需要 HLCE?
近年来,LLM 在代码生成领域取得了惊人的进步,许多主流基准(如 LiveCodeBench、APPS 等)已经无法对最前沿的模型构成真正的挑战。研究者指出,现有基准存在几个关键问题:
1. 难度有限:对于顶级 LLM 来说,很多题目已经过于简单。
2. 缺乏交互式评测:大多数基准采用标准的输入 / 输出(I/O)模式,而忽略了在真实竞赛中常见的 “交互式” 题目。这类题目要求程序与评测系统进行动态交互,对模型的实时逻辑能力要求更高。
3. 测试时扩展规律(Test-time Scaling Laws)未被充分探索:模型在推理时花费更多计算资源能否持续提升性能?这个问题在复杂编程任务上尚无定论。
为构建高质量基准,研究团队对 HLCE 题目进行了深度处理。例如 ICPC World Finals 题目原始材料均为 PDF 格式,团队通过人工逐题提取、转写为 Markdown 并校验,确保题目完整性。最终形成的 HLCE 基准包含:1)235 道 IOI/ICPC World Finals 历史难题;2)标准 I/O 与交互式双题型;3)全可复现的评测体系。
模型表现如何?顶级 LLM 也 “考蒙了”
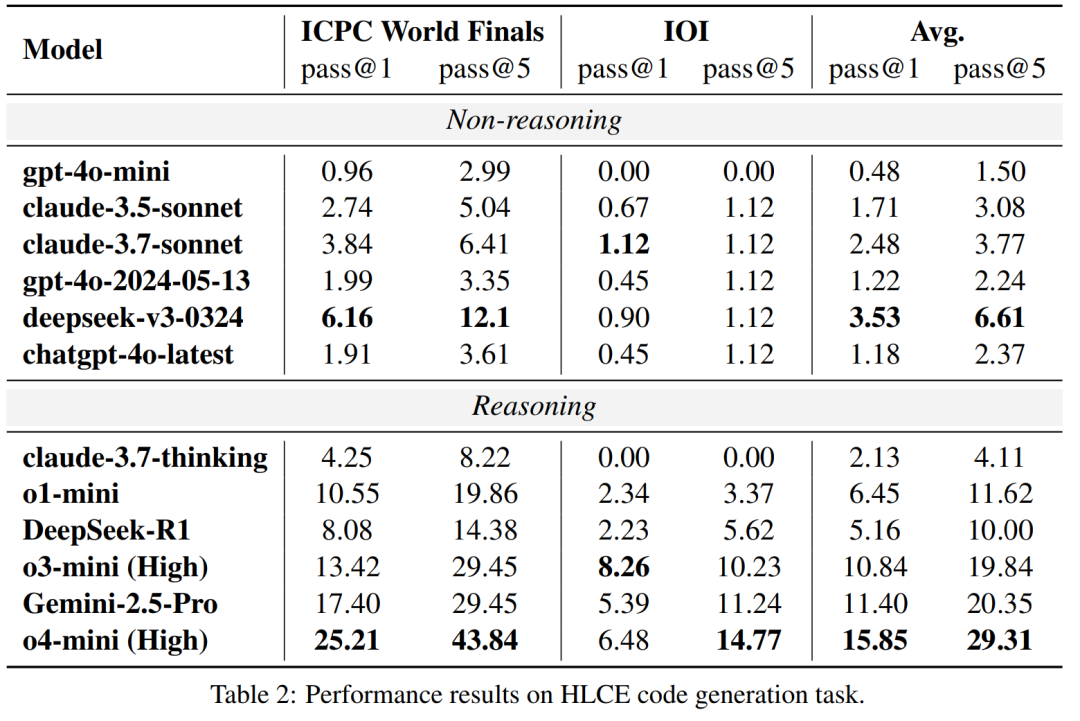
研究团队在 HLCE 上全面评估了 12 个主流 LLM,包括推理模型(如 o4-mini (high), Gemini-2.5 Pro, DeepSeek-R1)和非推理模型(如 chatgpt-4o-latest, claude-3.7-sonnet)。 实验结果揭示了几个有趣的现象:
推理模型优势巨大:具备推理能力的模型表现显著优于非推理模型。最强的 o4-mini (high) 的平均 pass@1 通过率(15.85%)大约是最强非推理模型 deepseek-v3-0324(3.53%)的 4.5 倍。
IOI 交互式题目是 “硬骨头”:所有模型在 IOI 题目上的表现都远差于 ICPC world finals 题目。例如,o4-mini (high) 在 ICPC 上的 pass@1 为 25.21%,但在 IOI 上骤降至 6.48%。研究者认为,这与当前模型的训练数据和强化学习方式主要基于标准 I/O 模式有关,对于交互式问题准备不足。
奇特的模型退化现象:一个例外是 claude-3.7-thinking 模型,尽管是推理模型,但其表现甚至不如一些非推理模型,在 IOI 题目上通过率为 0%。研究者推测,这可能是因为 claude 针对通用软件工程任务进行了优化,而非高难度的算法竞赛。
“我知道我不知道?”:模型的自我认知悖论
除了代码生成,研究者还设计了一个新颖的 “自我认知”(self-recognition)任务:让模型判断自身生成的代码是否正确,以评估其能力边界感知力。
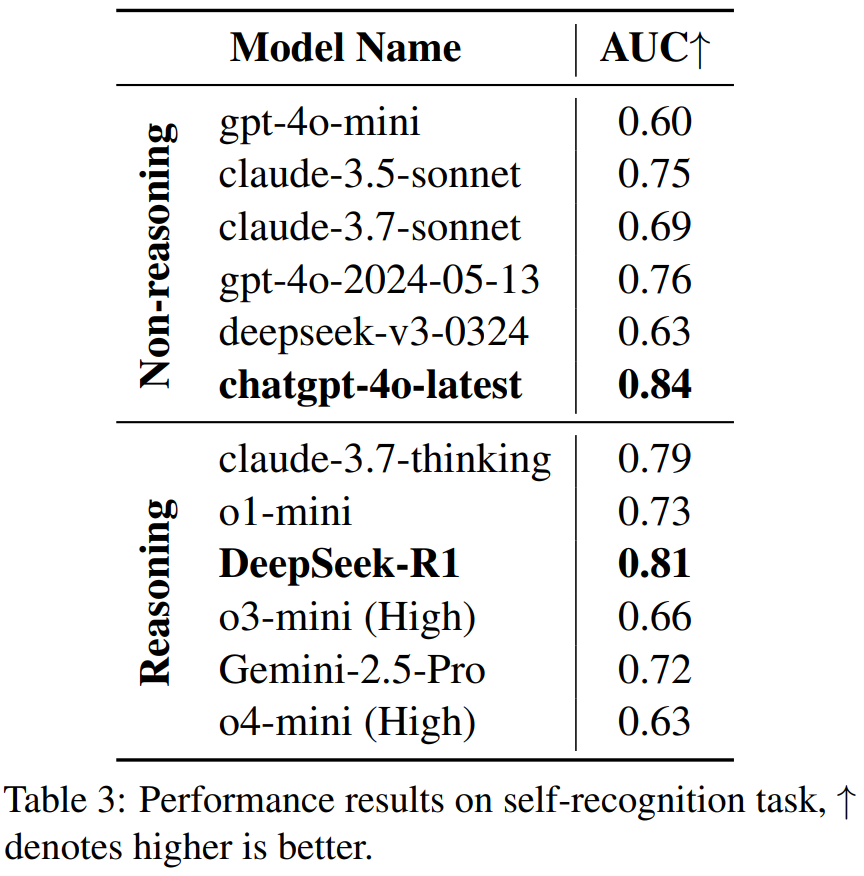
结果出人意料:
-
代码能力最强的 O4-mini (high),自我认知能力(AUC 0.63)并不突出。
-
反观通用模型 ChatGPT-4o-latest,展现了更强的 “自知之明”(AUC 0.84)。
这种 “苏格拉底悖论”—— 卓越的问题解决能力与清晰的自我认知能力未能同步发展 —— 暗示在现有 LLM 架构中,推理能力与元认知能力(metacognition)可能遵循不同的进化路径。
大语言模型的 Test Time scaling law 到极限了吗
一个关键问题是:目前 LLM 的推理能力已经非常强了,目前这种范式达到极限了吗?未来的模型的推理能力还能继续发展吗? 而面对如此高难度的 HLCE benchmark,这显然是一个绝佳的机会来研究大语言模型的 Test Time Scaling Law。
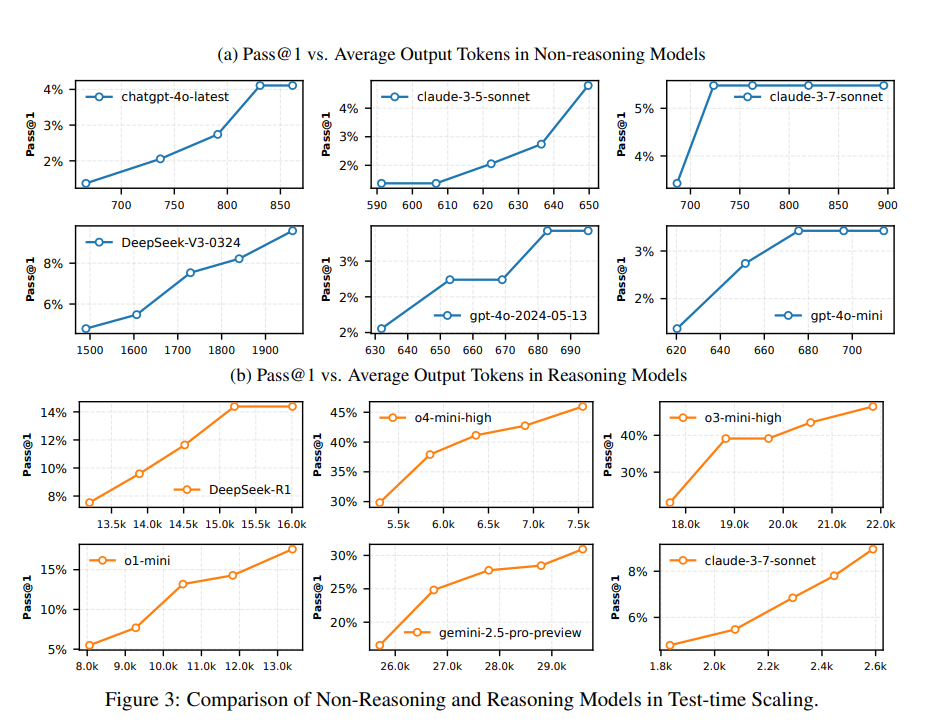
研究者将模型生成的每组回答按照 thinking token 的数量按照长短进行分组,然后重新测试性能。从图中可以看出,随着思考长度的不断延长,模型的性能在不断的提升,并且远远没有达到上限。
这个结论告诉我们,可以继续大胆的优化推理模型,至少在现在远远没有到达 Test Time scaling law 达到上限。
LLM vs 人类顶尖选手:差距还有多大?
基于上述发现,研究者将模型的最佳表现(基于 5 次尝试,IOI 取 5 次的最大分数,ICPC world Finals 取 5 次解决掉的最多题目)与历年 IOI 和 ICPC 世界总决赛的奖牌分数线进行了直接对比。
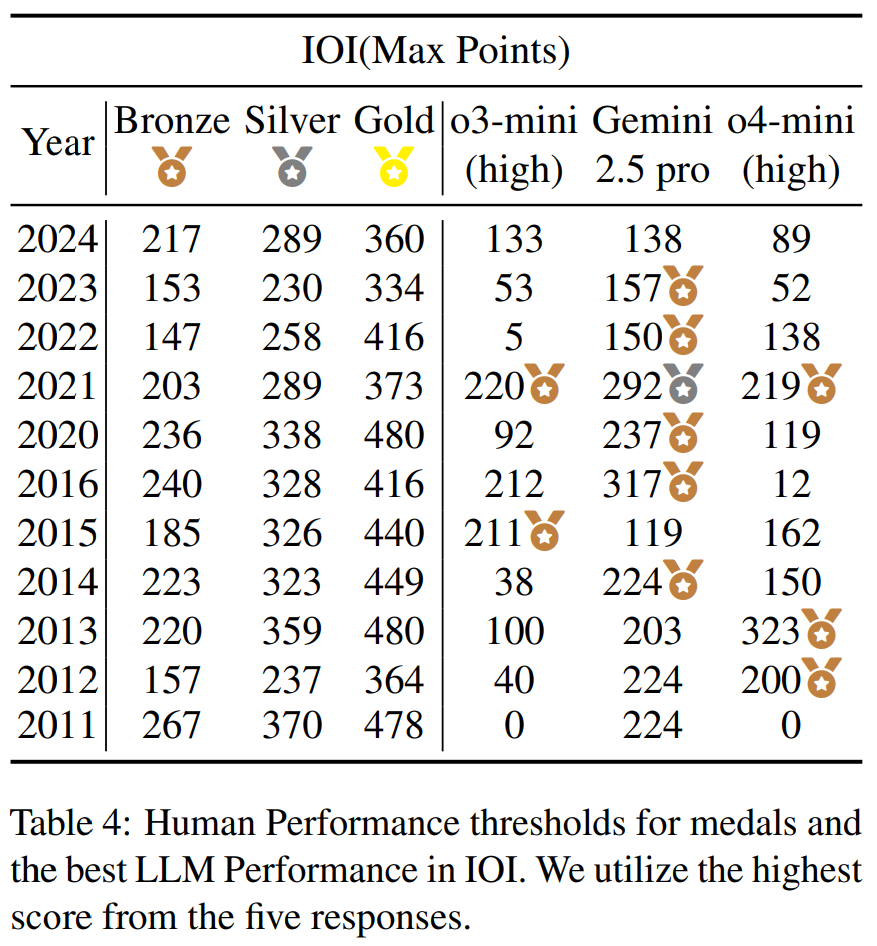
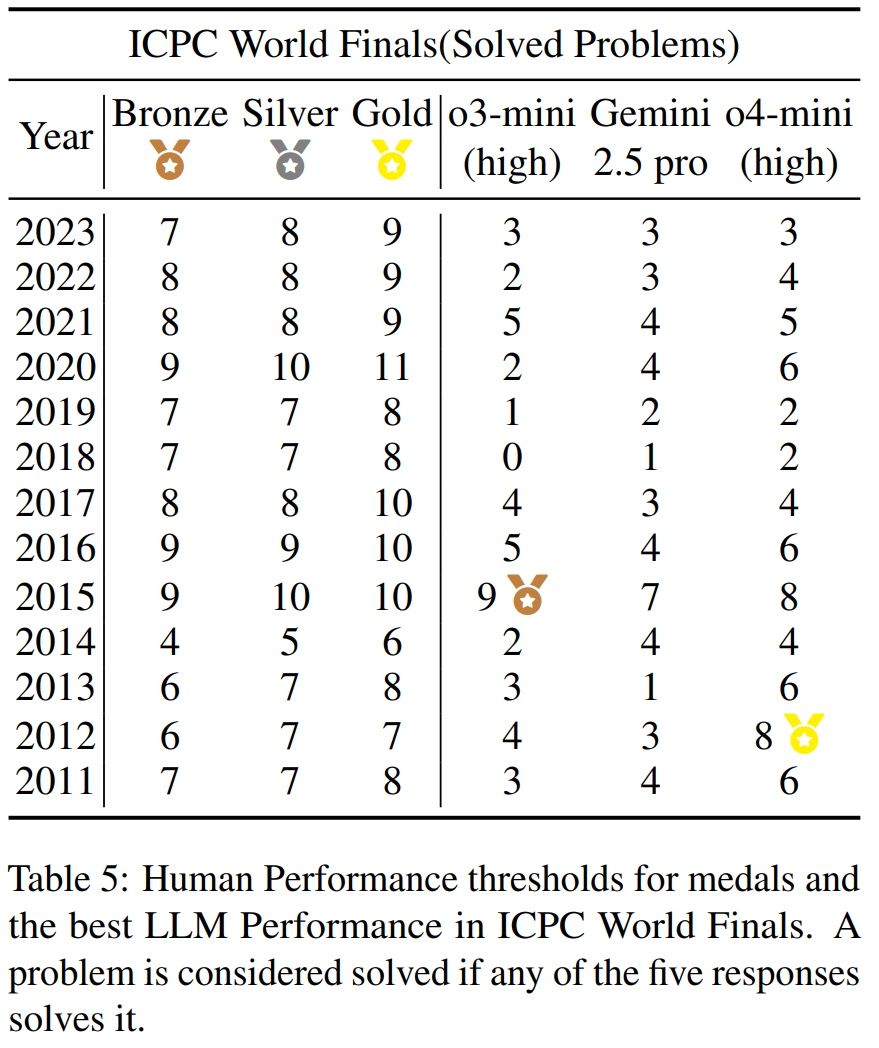
结果令人振奋:顶级 LLM 已经具备了赢得奖牌的实力。Gemini-2.5-pro 和 o4-mini (high) 的表现分别达到了 IOI 和 ICPC 的银牌和金牌水平。
这也解释了一个看似矛盾的现象:尽管模型单次成功率很低,但只要给予足够多的尝试机会(这正是 “测试时扩展规律” 的体现),它们就能找到正确的解法,从而在竞赛中获得高分。
未来方向
这项研究通过 HLCE 这一极具挑战性的基准,清晰地揭示了当前 LLM 在高级编程和推理能力上的优势与短板。 它证明了,虽然 LLM 在单次尝试的稳定性上仍有欠缺,但其内部已蕴含解决超复杂问题的知识。更重要的是,测试时扩展规律在这一极限难度下依然有效,为我们指明了一条清晰的性能提升路径:通过更优的搜索策略和更多的计算投入,可以持续挖掘模型的潜力。
©
(文:机器之心)