

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
动视暴雪、斯坦福大学和英伟达等研究人员基于123小时职业玩家的游戏数据和Transformer架构,开发了一个游戏大模型——MLMOVE。
他们在全球爆火的设计游戏《反恐精英:全球攻势》中对MLMOVE进行了综合测试。结果显示,MLMOVE可以像职业玩家那样学习到人类玩家的团队协作策略和技巧。
例如,在进攻和防守时会根据局势的判断来选择闪光弹、烟雾弹,或者与队友配合进行交叉火力掩护,进攻的时候躲闪也更加灵活。
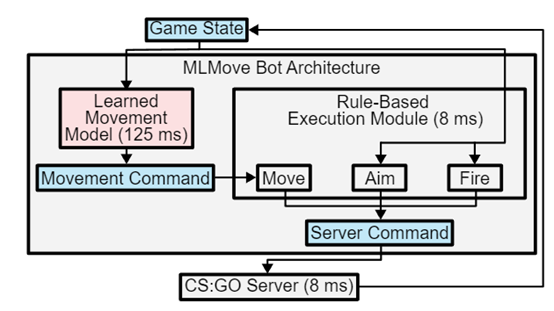
MLMOVE的性能也比现有的商业游戏机器人GAMEBOT和基于规则的机器人RULEMOVE好很多,更接近职业玩家的习惯。
对面两个机器人是MLMOVE
游戏里的AI机器人已经有几十年的历史,从早期的任天堂《马里奥》系列到手游的《王者荣耀》再到PC上的3A大作《巫师3》、《赛博朋克2077》等。但传统AI有一个很大的弊端,多数都是基于规则开发的,经过一段时间摸索玩家很容易就能发现它们的规律,影响整体游戏体验。
而MLMOVE使用了和ChatGPT一样的Transformer架构,可以轻松捕捉玩家间的相互配合和协调移动指令。模型的输入是一系列嵌入token,每个token代表一个玩家的当前状态,并通过嵌入层被转换成高维空间中的点,以帮助MLMOVE更高效的处理这些指令。
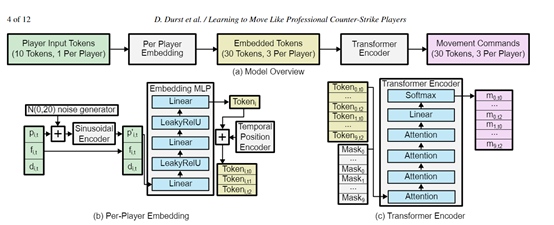
MLMOVE还使用了Transformer的核心模块“自注意力机制”,来学习玩家之间的空间关系和团队协作策略。例如,当一个玩家决定向前移动时,模型需要考虑这个动作如何影响他的队友以及对手的位置。
游戏中玩家被击毙后会被淘汰,将不能再参与到游戏的动态。为了处理这种情况,MLMOVE使用了Transformer的掩码技术,通过将被淘汰玩家的token设置为掩码,模型可以忽略这些玩家只关注存活玩家的移动效果。
像外挂一样的提前预判移动是MLMOVE的一大技术创新,不仅能预测下一个时刻的移动命令,还预测未来两个时间点的移动命令。能帮助模型更好地学习职业玩家运动的时间连贯性,生成更加自然和流畅的移动轨迹。
为了训练MLMOVE模型,研究人员从职业玩家日志中搜集了123小时的数据,涵盖玩家的移动路径、实时战斗对策、行动目标、如何掩护队友、如何配合发起进攻等,可以帮助模型学习更高的战略方法应对不同的场景。
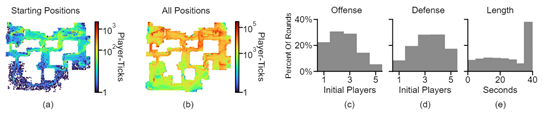
收集到原始数据后,研究人员对这些数据进行预处理。将原始数据转换成模型能够理解的格式。这包括将玩家的位置和速度信息转换成离散的token,以及从数据中提取出关键的游戏状态信息,例如,C4的安放位置和剩余时间等。
为了提高模型的训练效率和效果,研究人员还对训练数据进行了分批处理,将大量的训练数据分成若干个小批次,每次只处理一个小批次的数据。这样做的好处是可以减少内存的占用,提高训练的效率。
同时,还使用了随机梯度下降等优化算法来调整模型的参数,使得模型能够更快地收敛到最优解,能够学习到人类的动作精华。
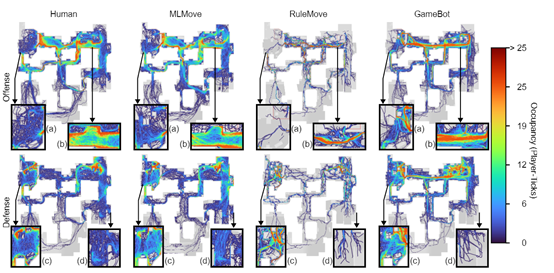
研究人员将MLMOVE与RULEMOVE、GAMEBOT商业机器人进行了横向对比,并邀请职业玩家根据TrueSkill评分体系对各个AI机器人进行评分。
结果显示,MLMOVE在人类评价者中获得了比RULEMOVE和GAMEBOT更高的评分,效果提升在16%—59%之间,可以更好地模仿人类职业玩家进行玩游戏。
(文:AIGC开放社区)