

最近关于 DeepSeek-R2 的讨论很热。
我翻了一下,最初的信息源应该是科技媒体 The Information 于 6 月 26 日发表的一篇题为《DeepSeek’s Progress Stalled by U.S. Export Controls》的文章,其中指出 DeepSeek 内部的 R2 模型开发遇到了两个关键瓶颈:一是 CEO 梁文锋对模型当前性能不满意,拒绝批准发布;二是受限于美国政府对 NVIDIA H20 芯片的新一轮出口管制,算力短缺正实质性阻碍新模型的训练与部署。
文章还提到,R2 原定于 2025 年 5 月初发布,如今已经默默跳票超过 50 天,DeepSeek 团队正尝试通过国产算力替代和模型结构优化来“重新构建发布条件”。
这条消息一出,路透社、The Tech Basic、NewsBytes,以及国内的 IT 之家、新浪财经,都迅速跟进了相关报道。
那么,究竟是哪里出了问题?R2 为何迟迟不上线?这场沉默背后,隐藏着两个现实:性能没达标,芯片没到位。
01|R2 “难产”全过程
-
2025年2月,路透社首度披露 DeepSeek 计划“最迟 5 月初”发布
R2; -
2025年3月,
R2发布传闻流传于 X 平台,DeepSeek 官方客服账号在用户群中澄清“为假消息”; -
2025年5月,原定时间节点已过,DeepSeek 并无正式动作,技术社区开始出现猜测;
-
2025年6月26日,The Information 首次披露 CEO 梁文锋对 R2 性能不满,决定暂缓上线;
-
次日,包括路透社、IT 之家、新浪财经等媒体接连跟进报道,确认延期为“实际状态”。
02|第一条主线:性能没过关
DeepSeek-R2 原本承载了“国产开源模型压制国外闭源模型”的野心。
根据之前的爆料,其核心规格包括(传闻,未证实):
-
总参数量:1.2 万亿,采用 Hybrid MoE 架构; -
动态激活参数:780 亿; -
单 token 推理成本下降 97.3%; -
主打方向:编程能力、多语言推理、多模态能力。
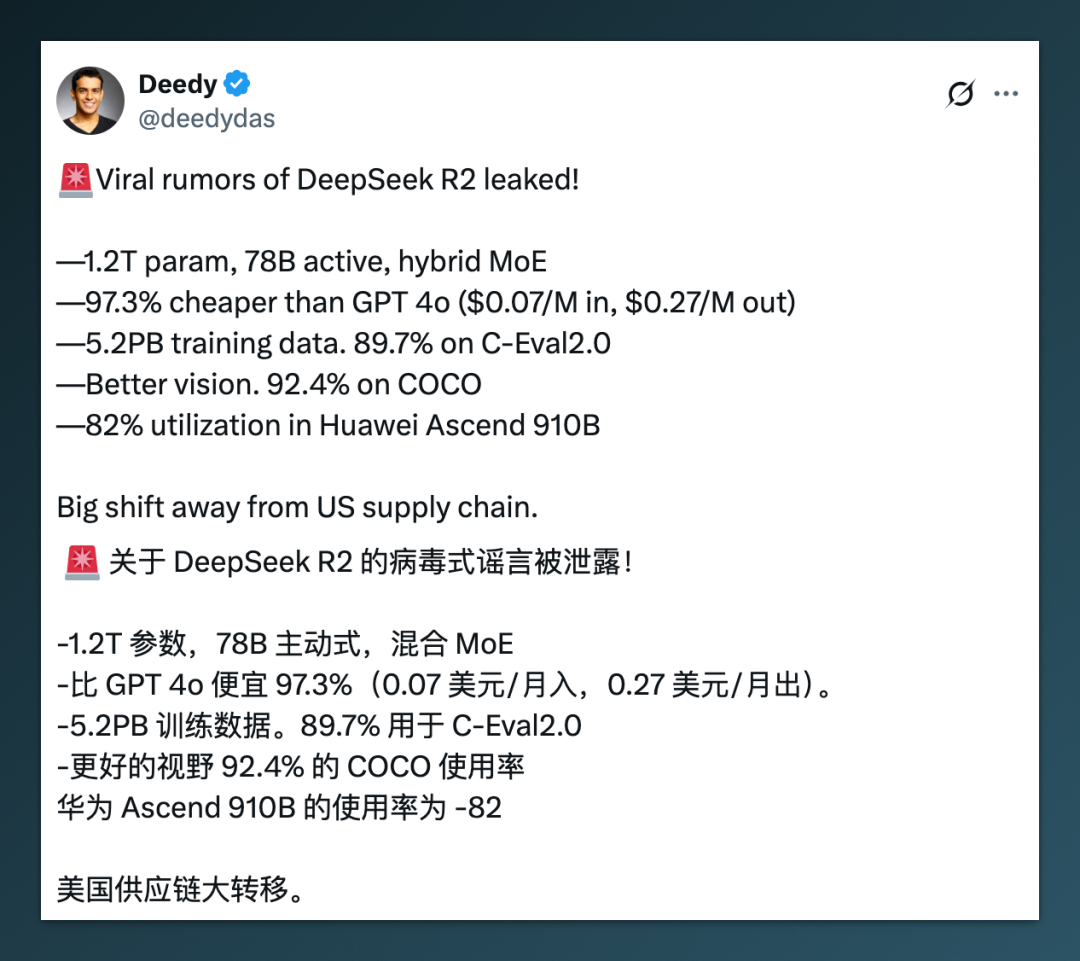
如果是真的,那 R2 就“无敌”了。但可能正因为“目标太高”,反而卡在了最后一公里。
据 The Tech Basic 报道,R2 在内部基准测试中始终无法实现对 R1 的全面碾压,尤其在多语言、编程等关键能力上“提升有限”。
DeepSeek CEO 梁文锋对此态度坚决:“达不到标准,就不发布。”
外界很难判断 R2 的实际表现究竟离“标准”差了多少,但可以推测 DeepSeek 的态度:必须“碾压”才发布。
03|第二条主线:算力的现实冲击
技术性能之外,更现实的问题是:DeepSeek 没有足够的芯片训练和部署 R2。
根本原因在于 —— H20 芯片断供了。
美国政府于 2025 年 4 月升级了对我国 AI 芯片出口管制,英伟达特供中国市场的 H20 被列入新一轮限制清单。受此影响,DeepSeek 无法继续采购新一批芯片。
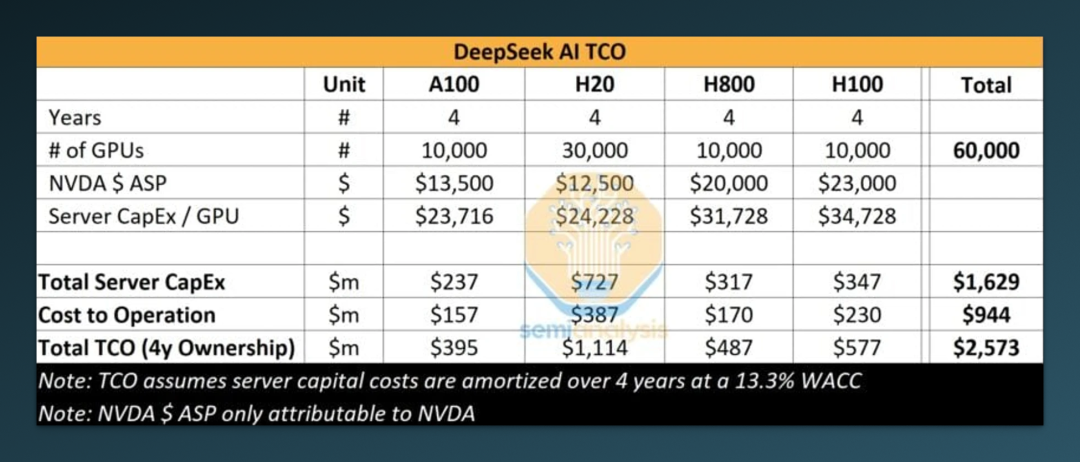
回顾一下 R1 的数据(估算数据来源:SemiAnalysis)。
-
使用芯片包括:H20(3 万块)、H800(1 万块)、H100(1 万块); -
R2若全面部署,芯片需求只增不减; -
一旦 R2推出,云厂商算力压力更大。
路透社援引知情云厂商员工透露,DeepSeek 已提前向云服务合作商下发了 R2 的资源规格预告(算力需求、并发指标、推理延迟目标等)。
另一方面迟迟未发布,可能是在等待“合规芯片”和“国产替代”的成熟。
04|沉默也是一种战略?
有观点认为,DeepSeek 当前的“沉默”状态,其实是一种“有意降温”。
-
不急于发布“半成品”; -
不在芯片最紧张的时候发布“最吃算力的模型”; -
不跟随竞品节奏,而是等待“精准出击”。
因此,社区中出现了新的猜测:R2 可能将在 7 月下旬 WAIC(世界人工智能大会,World Artificial Intelligence Conference) 或 8 月 AI Infra Summit 上首次亮相。
但就目前来看,关于 R2 什么时候发布,DeepSeek 官方始终没有表态。
结语
做个能赢的模型,而不是能发的模型。
如果要总结一句话,那大概是这样:
DeepSeek 不是没准备好上线,而是还没准备好“打胜仗”。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。
(文:AI信息Gap)